前言
GBDT算法,全名为梯度提升树,是以CART决策树为弱学习器并基于Boosting思想的一种集成学习算法。其与传统的Boosting算法有较大差别,但是也是一种弱学习器之间相互关联,只能串行训练的机器学习算法。GBDT在机器学习算法中具有举足轻重的地位,在深度学习流行之前,在kaggle,天池等竞赛中常常占据榜首,并且在工业界也被经常使用。本文将介绍GBDT的算法原理及其sklearn代码实现。
注:本文基于决策树与集成学习,对此不了解的可以移步本站的决策树与集成学习的博客,决策树上篇,决策树下篇,集成学习简介。另外,本文也会谈及到AdaBoost算法,想要了解AdaBoost算法可以移步本站的AdaBoost算法的博客,AdaBoost算法。
GBDT算法思想
提升思想
GBDT基于Boosting,但不完全是Boosting,相比于AdaBoost这类完全遵循Boosting框架的算法,GBDT对传统的Boosting框架做了一定的改动,原Boosting算法框架图如下
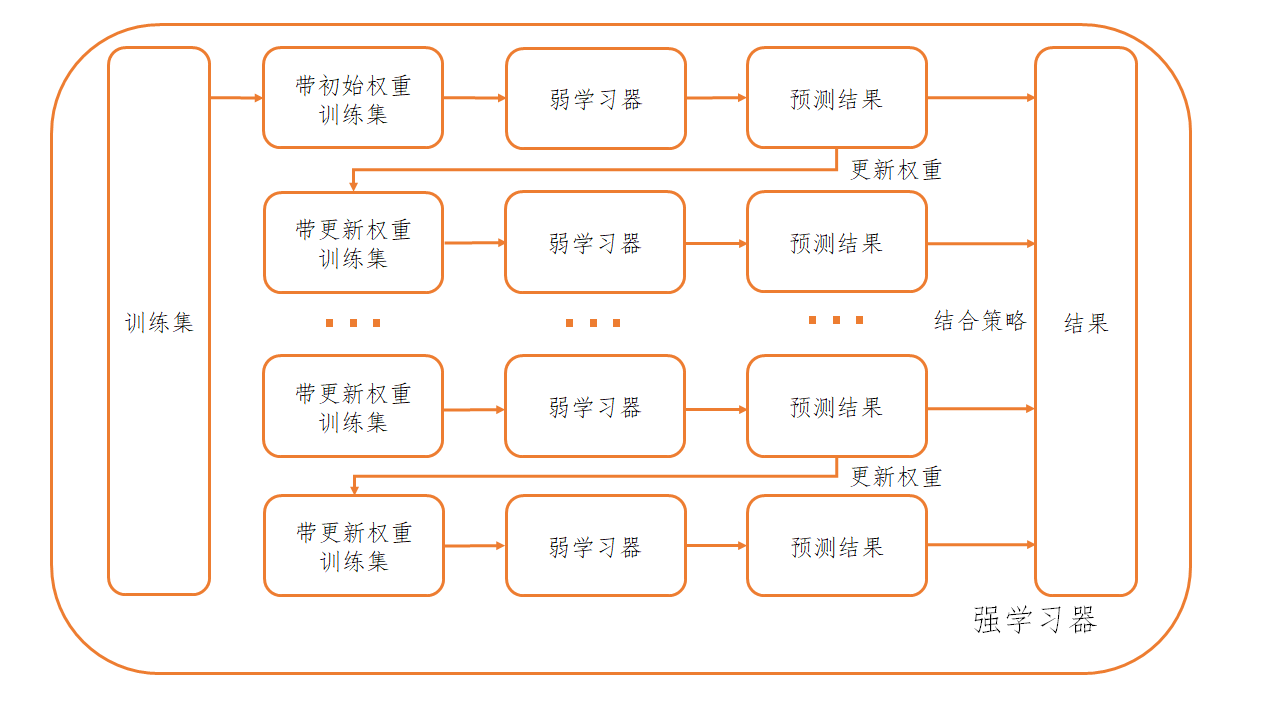
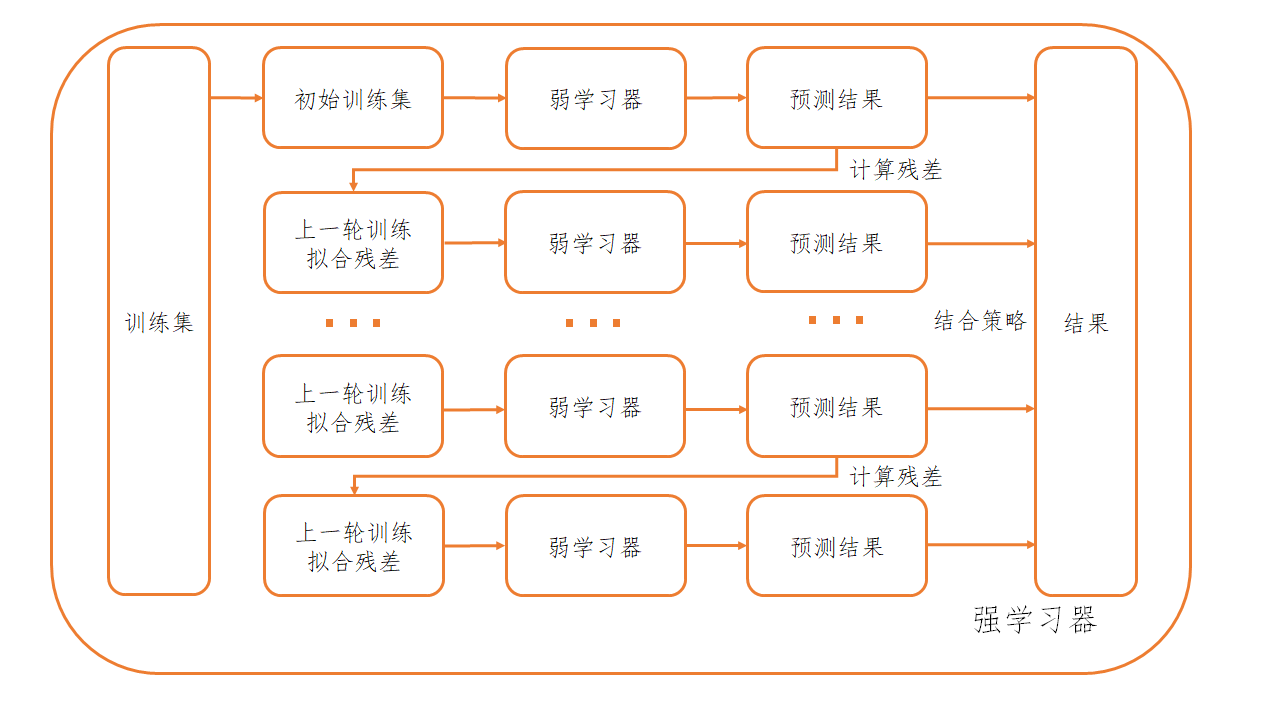
相比于传统的Boosting采用的更新训练集权重,GBDT采用的方法是直接修改训练集,每一次训练使用的数据集为上一次训练出的学习器的拟合残差。也就是说,对于之前的学习器所没有拟合好的样本,在这一轮中会被新的学习器继续缩小差距。这就是所谓的提升思想。
举例来说,假设真实值为100,第一个学习器预测值为80,那残差就是20,第二个学习器的任务就是拟合这个残差,也就是尽量靠近20,假设第二个学习器预测值为15,则残差为5,送到第三个学习器继续学习,最终将所有学习器的预测值相加即可。
综上,GBDT的流程可以总结为下图
负梯度拟合
虽然上文提到GBDT是采用不断拟合残差的训练方法,也就是说rki代表第k轮训练时使用的第i个样本为(xi,yi−f(xi))。但是对于一般的损失函数而言,计算每一步优化往往不是那么简单,因此GBDT使用了损失函数的负梯度来近似残差,具体定义为
rki=−[∂f(xi)∂L(yi,f(xi))]f(x)=fk−1(x)
也就是说第k轮训练时使用的第i个样本为(xi,rki),L(y,f(x))代表损失函数,f(x)=fk−1(x)代表前面k−1轮训练出的学习器。当损失函数为平方误差时,负梯度与残差相等(严格来说是相差常数倍)
−∂f(xi)∂L(yi,f(xi))=−∂f(xi)∂(yi−f(xi))2=−2(yi−f(xi))(−1)=2(yi−f(xi))
补充
关于负梯度,上文我们是直接给出,这里给出负梯度的构造过程。首先,我们来回顾一下泰勒展开公式,泰勒展开是对于一个函数的近似,其展开阶数越高,拟合程度越高,并且其在给定的x=x0附近的拟合效果是最好的。这里我们回顾一下一阶的泰勒展开
f(x)≈f(x0)+f′(x0)(x−x0)
这里我们不关注余项。将损失函数L(y,f(x))在f(x)=fk−1(x)处进行一阶泰勒展开
L(y,f(x))≈L(y,fk−1(x))+[∂f(x)∂L(y,f(x))]f(x)=fk−1(x)(f(x)−fk−1(x))
令f(x)=fk(x),且fk(x)=fk−1(x)+hk(x),得
L(y,fk(x))≈L(y,fk−1(x))+[∂f(x)∂L(y,f(x))]f(x)=fk−1(x)(fk(x)−fk−1(x))=L(y,fk−1(x))+[∂f(x)∂L(y,f(x))]f(x)=fk−1(x)hk(x)
移项可得
L(y,fk(x))−L(y,fk−1(x))≈[∂f(x)∂L(y,f(x))]f(x)=fk−1(x)hk(x)
现在我们的目的是求解hk(x)使得L(y,fk(x))最小,由于L(y,fk−1(x))是一个定值,等同于使得L(y,fk(x))−L(y,fk−1(x))最小,故[∂f(x)∂L(y,f(x))]f(x)=fk−1(x)hk(x)可以作为目标函数的近似,[∂f(x)∂L(y,f(x))]f(x)=fk−1(x)为hk(x)的梯度,要使得hk(x)取到最小,那么可以往梯度的负方向优化,其思想类似于梯度下降,这也就构造出了负梯度。
GBDT回归树
从上文中我们可以注意到,GBDT是从回归问题的角度出发的,因此我们从回归问题开始讲起。
GBDT回归流程
根据上文中给出的GBDT思想,我们可以给出构建GBDT回归树的流程
输入:训练集T={(xi,yi),i=1,2,⋯,m},训练次数K
输出:强学习器f(x)
(1) 使用训练集T训练初始弱学习器f0(x)=h0(x)=minc∑i=1mL(yi,c),其中h0(x)为只有根节点的CART回归树
(2) 对于第k轮训练,计算负梯度rki=−[∂f(xi)∂L(yi,f(xi)))]f(x)=fk−1(x),得到训练集Tk={(xi,rki),i=1,2,⋯,m}
(3) 使用训练集Tk训练得到CART回归树hk(x),更新强学习器为fk(x)=fk−1(x)+hk(x)
(4) 经过K轮训练后得到强学习器f(x)=fK(x)=∑k=0Khk(x)
回归常用损失函数
对于回归问题,常用的损失函数有四种,分别为
平方误差(均方差):最常用的损失函数
L(y,f(x))=(y−f(x))2
绝对误差:在x为0处不可导,因此没有解析解,但是对常用数值计算方法求近似解的机器学习算法来说,无伤大雅
L(y,f(x))=∣y−f(x)∣
Huber损失:这是平方误差和绝对损失的折中产物,对于远离中心的异常点,采用绝对损失,而中心附近的点采用均方差,这个界限一般用分位数点度量。
L(y,f(x))={21(y−f(x))2δ(∣y−f(x)∣−2δ)∣y−f(x)∣≤δ∣y−f(x)∣>δ
分位数损失:即分位数回归的损失函数
L(y,f(x))=y≥f(x)∑θ∣y−f(x)∣+y<f(x)∑(1−θ)∣y−f(x)∣
其中θ为分位数。
注:一般使用前两种损失函数,后两种主要用于数据异常点较多的情况,用于提高模型的健壮性。
GBDT分类树
而对于分类问题来说,由于输出y是离散值,这使得我们无法描述残差。GBDT使用的做法为,将分类问题也看做回归问题对待,这类似于logistic回归使用线性回归模型来处理分类问题,弱学习器依旧使用CART回归树,使用损失函数来描述残差。
二分类问题
logistic回归回顾
与逻辑回归问题相同,我们先从二分类问题开始讲起,这里我们简单回顾一下逻辑回归,其思想为通过sigmoid函数,将线性回归的输出映射到(0,1)代表概率,定义二分类变量y∈{0,1},则逻辑回归模型可以写为
f(x)=σ(h(x))=1+e−h(x)1
其中h(x)为线性回归模型,f(x)可以理解为x属于类别1的概率,而x属于类别0的概率自然就是1−f(x),记为
p1=f(x)p0=1−f(x)
上述两个概率值可以统一写为
p(x)=f(x)y(1−f(x))1−y=p1yp01−y
可以注意到,当y=1时,p(x)=p1,即判断为第一类的概率,反之同理。因此p(x)的意义为判断正确的概率。因此逻辑回归问题的目标函数为
i=1∏mf(xi)yi(1−f(xi))(1−yi)
也就是令所有样本的判断正确概率最大,为了方便计算,我们将其取对数,并加上负号,得到损失函数为
L=−i=1∑myiln(f(xi))+(1−yi)ln(1−f(xi))
该损失函数被称为对数似然损失函数。
GBDT二分类算法的流程
现在我们将逻辑回归的理论套用至回归树上,只需要将h(x)替换为CART回归树即可,损失函数依旧为
L(y,f(x))=−yln(f(x))−(1−y)ln(1−f(x))
注:这里写的是单个样本的损失函数,上面写的是所有样本的损失函数,因为这里我们要用单个样本的损失函数来求负梯度,实际上两个损失函数是一样的。
有了损失函数之后,就是求负梯度
rki=−[∂f(xi)∂L(yi,f(xi))]=f(xi)1−yi−f(xi)yi=f(xi)(1−f(xi))f(xi)−yi
至此,我们可以给出GBDT二分类算法的流程,这与GBDT回归树相比仅仅是换了一个损失函数
输入:训练集T={(xi,yi),i=1,2,⋯,m},训练次数K
输出:强学习器f(x)
(1) 使用训练集T训练初始弱学习器f0(x)=h0(x)=minc∑i=1mL(yi,c),其中h0(x)为只有根节点的CART回归树
(2) 对于第k轮训练,计算负梯度rki=−[∂f(xi)∂L(yi,f(xi)))]f(x)=fk−1(x)=f(xi)(1−f(xi))f(xi)−yi,得到训练集Tk={(xi,rki),i=1,2,⋯,m}
(3) 使用训练集Tk训练得到CART回归树hk(x),更新强学习器为fk(x)=fk−1(x)+hk(x)
(4) 经过K轮训练后得到强学习器f(x)=fK(x)=∑k=0Khk(x)
多分类问题
softmax回归回顾
而对于多分类问题,我们可以参照一般化的logistic回归,也就是softmax回归。其使用的是one-vs-rest的策略,也就是对于R个类别的问题,构建R个逻辑回归模型,但是每一个模型的输出意义不同,第r个模型的输出fr(x)代表样本属于第r类的概率,反之1−fr(x)代表样本不属于第r类的概率。最后将其结合为一个向量Y,向量Y的第r个分量Y(r)代表该样本属于第r类的概率,为了满足概率的要求,需要该向量做归一化,以保证向量和为1。理想情况下的Y应该是只有正确类别对应的分量为1,其余分量均为0,因此可以对训练集的标签进行独热编码,将每一个样本的标签转化为1×R的向量。
softmax回归所使用的softmax函数,就是完成了从线性回归到概率向量的转化,也就是将第r个线性回归模型的输出hr(x)直接转化为向量Y的第r个分量Y(r)。该函数定义为
softmax(xi)=∑j=1Rxjxi
也就是说,在得到R个h(x)后,可以计算得向量Y的各分量为
Y(r)=softmax(hr(x))=∑j=1Rhj(x)hr(x)
综上,softmax回归的流程为
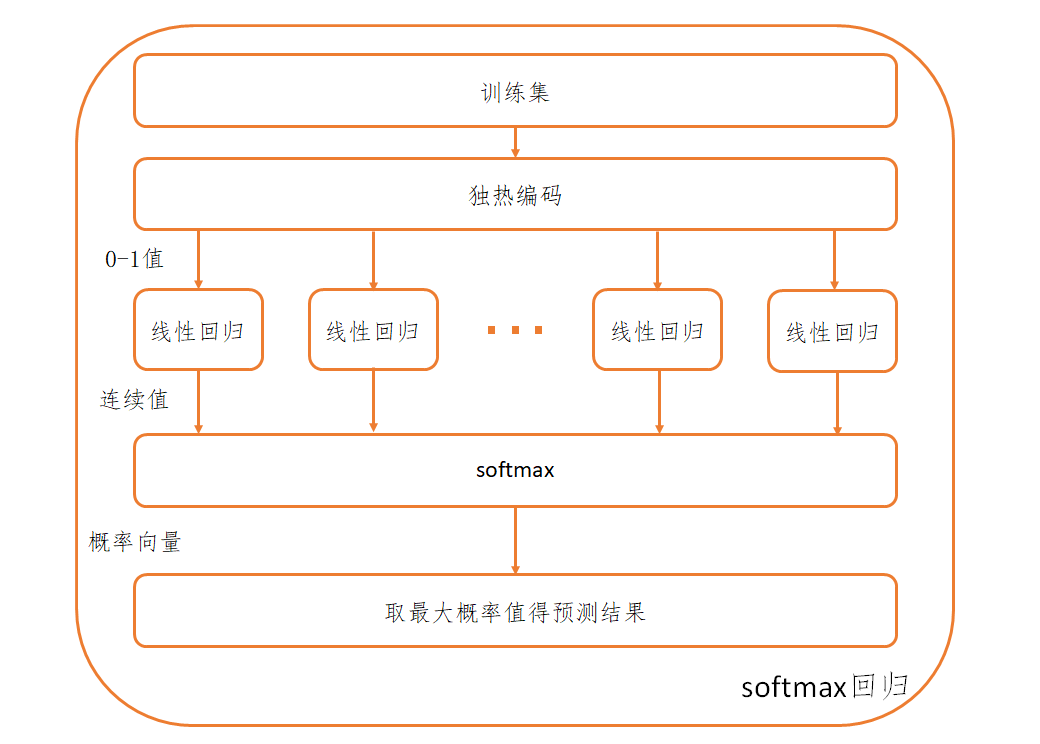
接着是损失函数,我们记真实值的标签向量为Y,这是一个仅有一个分量为1,其余分量均为0的向量,记概率向量为P,其每一个分量都代表样本被分到该类的概率,并且向量和为1。很自然的,我们会希望两个向量的距离越近越好,也就是希望向量的模∣∣Y−P∣∣2越小。但是在分类问题中,我们其实并不用追求正确的分类对应的分量取值为1,如一个归属与第r类的样本,只要P(r)>1/R,其实就可以判断正确,所以平方损失函数有些过于严苛了,我们可以使用交叉熵来衡量
H(Y,P)=−j=1∑RY(j)ln(P(j))
注意到向量Y仅有一个分量为1,因此对属于第r类的样本
−j=1∑RY(j)ln(P(j))=−ln(P(r))
也就是说交叉熵仅关注正确类别对应的概率,这很符合我们的需求。
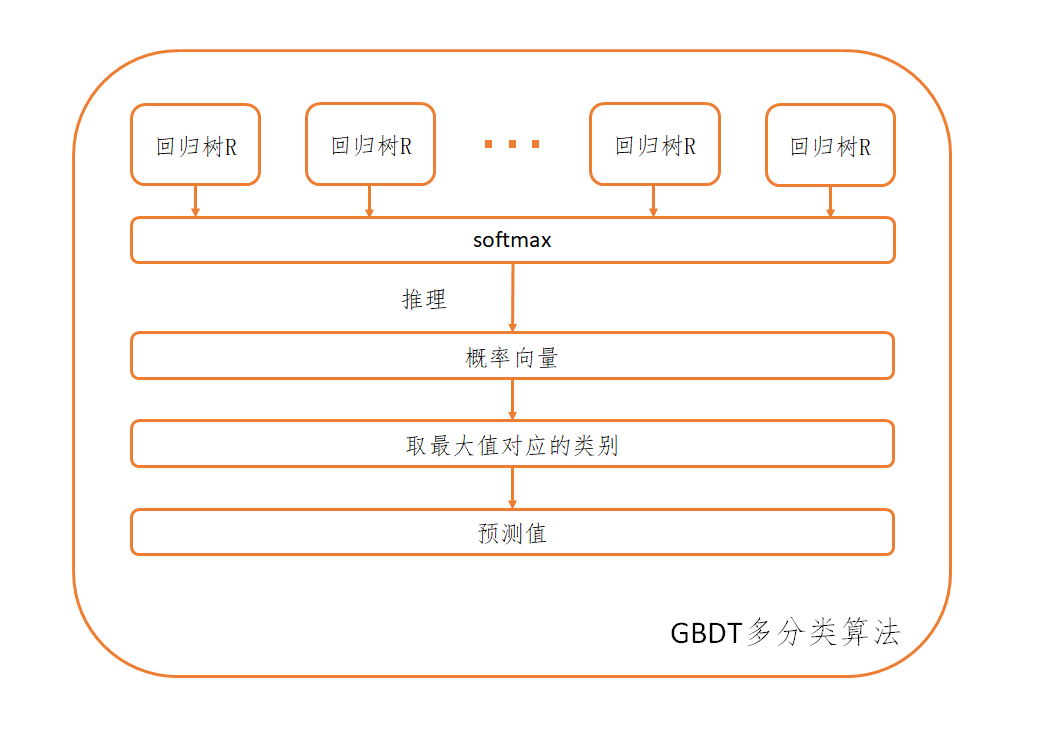
GBDT多分类算法的流程
GBDT多分类算法就是在softmax回归的基础上,将线性回归模型替换为CART回归树,也就是说对于有R个类别的分类问题,我们需要构建R颗CART回归树,也就是说,我们需要将GBDT二分类算法做的事情做R次。那就剩最后一个问题,就是确定损失函数与负梯度。接下来我们来看对于第r颗树的训练,损失函数使用softmax回归中使用的交叉熵损失函数
H(Y,P)=−j=1∑RY(j)ln(P(j))
由于P(j)=softmax(f(j)(x)),故损失函数为
L(Y(j),f(j)(x))=−j=1∑RY(j)ln(∑i=1Rf(i)(x)ef(j)(x))=−j=1∑RY(j)[f(j)(x)−ln(i=1∑Rf(i)(x))]
由于∑j=1RY(j)=1,故
L(Y(j),f(j)(x))=ln(i=1∑Rf(i)(x))−j=1∑RY(j)f(j)(x)
最后是求解负梯度,这里需要注意的是,当我们求解第一个GBDT分类器f(1)(x)时,我们是将损失函数对f(1)(x)求偏导,也就是
−[∂f(1)(x)∂L(Y(j),f(j)(x))]=Y(1)−∑i=1Rf(i)(x)ef(1)(x)=Y(1)−softmax(f(1)(x))
因此,在我们训练第一个GBDT分类器时,第k轮训练时使用的第i个样本为(xi,rki),其中
rki=−[∂f(1)(x)∂L(Y(j),f(j)(x))]f(1)(x)=fk−1(1)(x)=Y(1)−softmax(f(1)(x))
也就是说,在我们训练第r个GBDT分类器时,第k轮训练时使用的第i个样本为(xi,rki),其中
rki=−[∂f(r)(x)∂L(Y(j),f(j)(x))]f(r)(x)=fk−1(r)(x)=Y(r)−softmax(f(r)(x))
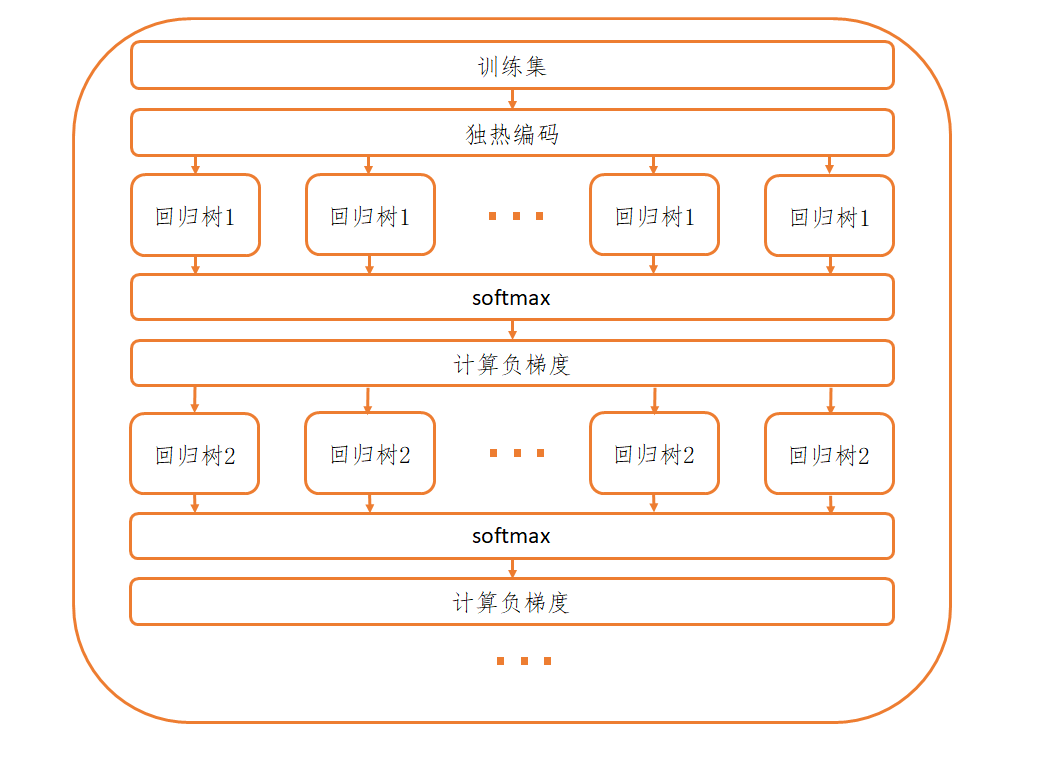
至此,我们可以得到GBDT多分类算法的流程为
输入:训练集T={(xi,yi),i=1,2,⋯,m},训练次数K,样本类别数R
输出:强学习器F(x)
(1) 对训练集T进行独热编码,得到R个训练集T(r),r=1,2,⋯,R
(2) 对于第r个学习器的训练,使用训练集T(r)训练初始弱学习器f0(r)(x)=h0(x)=minc∑i=1mL(yi,c),其中h0(x)为只有根节点的CART回归树
(3) 对于第k轮训练,计算负梯度rki=−[∂f(r)(x)∂L(Y(j),f(j)(x))]f(r)(x)=fk−1(r)(x),得到训练集Tk={(xi,rki),i=1,2,⋯,m}
(4) 使用训练集Tk训练得到CART回归树hk(x),更新强学习器为fk(r)(x)=fk−1(r)(x)+hk(x)
(5) 对于第r个学习器的训练,经过K轮训练后得到学习器f(r)(x)=fK(r)(x)=∑k=0Khk(x)
(6) 经过R次GBDT学习器的构建,将R个GBDT学习器结合为一个向量f(x)=(f(1)(x),f(2)(x),⋯,f(R)(x))
(7) 最终输出为f(x)中取值最大的分量对应的类别,即F(x)=maxrf(r)(x)
也可以总结为下图
sklearn代码实现
最后我们来介绍一下sklearn代码实现,运行环境为jupyter notebook,需要用到的库为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import AdaBoostRegressor
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import load_wine
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from scipy import stats
import warnings
warnings.filterwarnings("ignore")
|
使用红酒数据集与波士顿房价数据集作为示例数据
1
2
3
|
wine = load_wine()
boston = load_boston()
|
参数列表
在sklearn中,实现GBDT的函数为GradientBoostingClassifier()与GradientBoostingRegressor(),其常用参数列表为
| 参数 |
说明 |
| n_estimators |
训练次数,也就是弱学习器数量,在任何集成学习算法中都是重要的参数。 |
| learning_rate |
学习率,默认为1,较大的学习率可以完成模型的快速收敛,较小的学习率可以使得模型的学习更加的精细。learning_rate和n_estimators之间存在权衡关系,一般较小的学习率要配合较大的训练次数。 |
| loss |
损失函数。对于分类问题,可填{‘deviance’, ‘exponential’},默认为’deviance’,’deviance’指对数似然损失函数,‘exponential’指指数损失函数,也就是AdaBoost中所使用的。对于回归问题,可填{‘ls’, ‘lad’, ‘huber’, ‘quantile’},默认为‘ls’,其中‘ls’指平方损失函数,‘lad’指绝对损失函数,‘huber’指Huber损失函数,‘quantile’指分位数损失函数。 |
由于GBDT使用决策树作为其弱学习器,与随机森林一样,其继承了决策树的参数,常用的有
max_depth:最大深度
min_samples_leaf & min_samples_split:节点或子节点需要包含的最少训练样本
min_impurity_decrease:限制信息增益
max_features:限制特征数
random_state:随机数种子,用于随机选择特征,保证每次训练得到的结果一致。
下面我们已经以红酒数据集与波士顿房价数据集作为示例数据集,来跑分类与回归的demo
分类
1
2
3
4
5
6
7
|
data = pd.DataFrame(wine.data)
data.columns = wine.feature_names
target = pd.DataFrame(wine.target)
target.columns = ['class']
Xtrain, Xtest, Ytrain, Ytest = train_test_split(data, target, test_size=0.2)
|
1
2
3
4
5
6
7
|
clf = GradientBoostingClassifier(n_estimators=200
,learning_rate=0.5
,max_depth=4
,random_state=1008)
clf.fit(Xtrain, Ytrain)
clf.score(Xtest, Ytest)
|
作为以决策树为弱学习器的集成学习方法,GBDT自然也继承了决策树的一些重要属性,如特征重要性
1
| clf.feature_importances_
|
回归
1
2
3
4
5
6
7
|
data = pd.DataFrame(boston.data)
data.columns = boston.feature_names
target = pd.DataFrame(boston.target)
target.columns = ['MEDV']
Xtrain, Xtest, Ytrain, Ytest = train_test_split(data, target, test_size=0.2)
|
1
2
3
4
5
6
7
8
9
|
clf = GradientBoostingRegressor(n_estimators=200
,learning_rate=0.5
,max_depth=3
,min_samples_split=40
,min_samples_leaf=40
,random_state=1008)
clf.fit(Xtrain, Ytrain)
clf.score(Xtest, Ytest)
|





