
决策树(上):ID3算法与C4.5算法
前言
决策树算法是一种非常常见的机器学习算法,由于其运算速度快,对数据要求低,并且具有可解释性等优点,其在工业界长盛不衰,并且在集成学习技术中,也经常使用决策树作为其基学习器,这其中甚至包括一些kaggle,天池这类竞赛中常用于刷分的一些算法,如GBDT,XGBoost等。本文会顺着决策树的发展历史,从最开始的ID3算法讲起,介绍决策树算法是如何一步步改进,发展至今的。
决策树简介
什么是决策树
假设有一个决策是否放贷的问题需要解决,而已有的数据有“是否有房”及“是否有工作”两个特征。现在使用决策树构建一个分类模型,一个可能的结果如下图
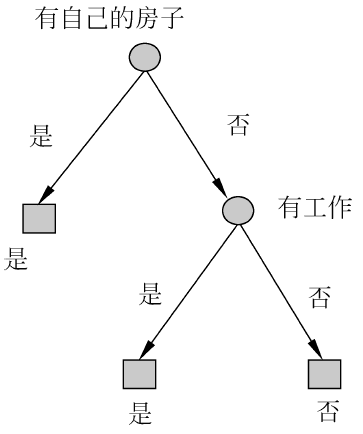
这就是决策树,等同于对数据特征构建一套if-else规则用于解决实际的分类或回归问题。
决策树需要解决的几个问题
经过上述介绍,实现决策树算法需要解决几个问题
- 应该如何进行特征选择(哪个特征先做if,哪个后做,会使得最终模型的效果会更好)
- 如何进行决策树的生成(即具体的算法实现,算法的终止条件是什么)
- 如何解决过拟合问题(如果欠拟合则证明模型的复杂度不够,换用更复杂的模型即可,过拟合则需要考虑如何增加模型的泛化性)
ID3算法
特征选择
信息熵
信息熵用于度量随机变量的不确定性。设一个随机变量,其分布为,信息熵的定义为
下面用一个简单的例子来感受一下信息熵为什么可以度量不确定性。
假设的分布为
在该分布下,信息熵的值只与有关,故信息熵记为。信息熵随着变换的图像为
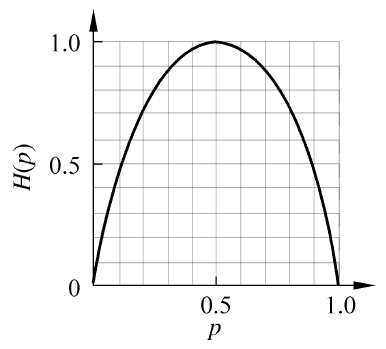
可以看到,在极端情况下,比如全为0或1,则被完全确定,也就是说不确定性最弱,此时为0。反之,在时,的不确定性最强。
联合信息熵与条件信息熵
设随机变量,其联合概率分布为
其联合信息熵为
由此可以得出条件熵
其中,
信息增益
经过上述理论的铺垫,现在让我们看看对于实际的数据集,上述理论有什么作用。让我们回到最开始的贷款申请问题,记数据集为,数据集中包含特征与标签,特征即我们可以分析利用的数据,标签即正确答案,特征与标签也可以理解为回归问题中的。对于贷款申请问题的数据集,如下图,前五列为特征,最后一列为标签。
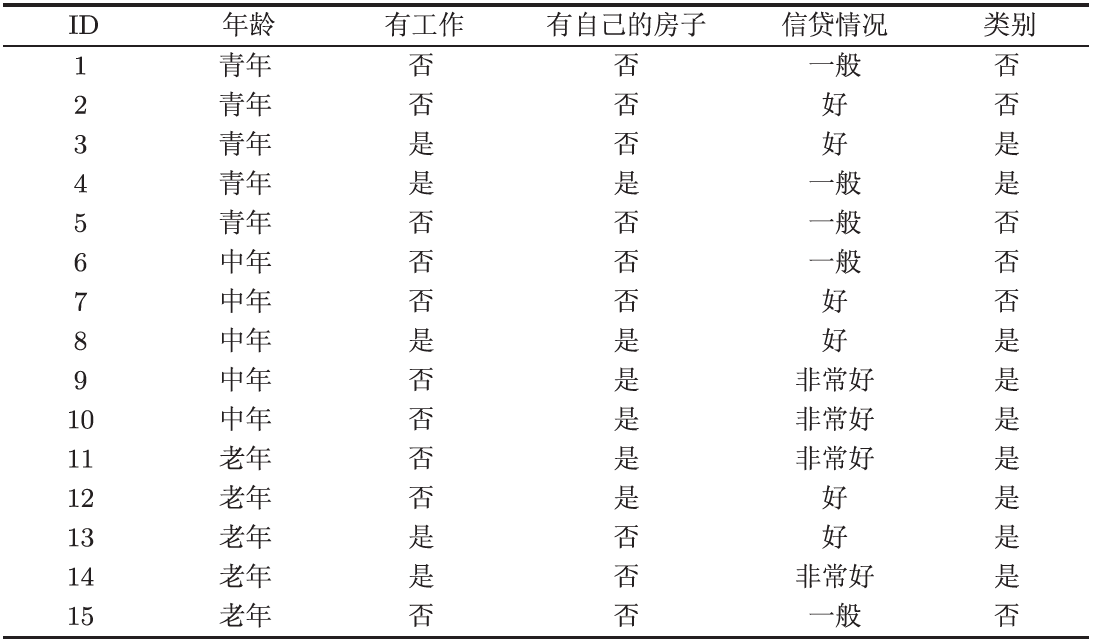
下面,我们着眼于上述例子,其所有特征与标签均为离散型变量。于是一般的,我们假设标签有个类,为数据集的样本数量,为标签属于第类的样本数量。现在让我们只看标签,其服从分布,对其计算信息熵并记为,即
这便是数据集最开始的不确定性。
接下来,让我们引入特征,在特征已知的情况下,根据特征将划分为个子集,记为,且记子集中标签属于第类的样本集合为,同理,符号代表集合中的样本数量。则可以计算条件熵,具体的为
条件熵的意义为在特征已知的情况下,数据集的不确定性。
根据上述计算,很自然的可以得出,使用特征进行划分,数据集的不确定性的降低量,该指标定义为信息增益,记为
于是,在数据均为离散型的情况下,我们便有了衡量特征优劣的指标。一个特征能够使数据集的不确定性最大限度的降低,也就是信息增益最大,则该特征就是最优的特征。
ID3决策树生成算法
铺垫至此,终于可以引出具体的决策树算法了。决策树的生成思路非常简单,就是对一个树节点,选择最优特征,并根据该特征分化出个子节点,再对这个子节点做相同操作。这里再把这张图放上来,首先根节点选择“是否有自己的房子”这个特征,然后根据该特征风化为两个节点,当然数据集也根据此特征被分为两个不相交的集合(一个集合中是全为有自己的房子的数据,也就是左边的节点,另一个集合中是全为没有自己的房子的数据,也就是右边的节点),然后左边的节点达到了停止条件,而右边的节点根据分开后的数据集,再进行特征选择,再进行节点分化。(有点类似于递归,结合下图,好好感受一下)
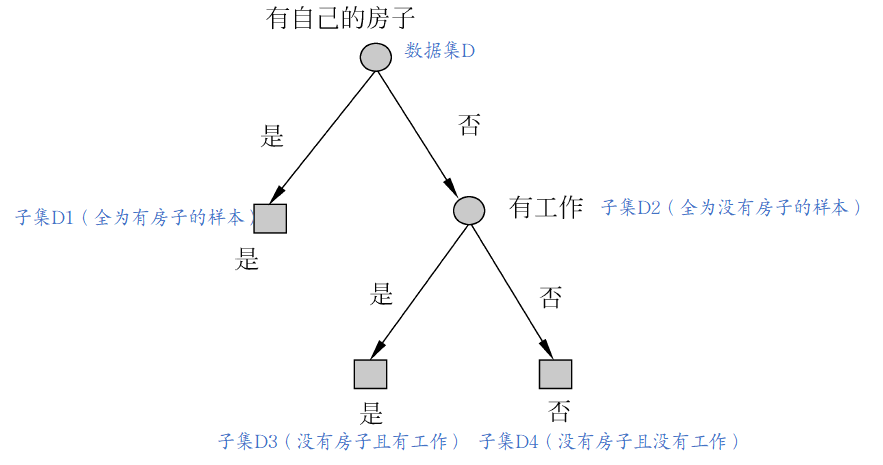
接下来还有最后一个问题,也就是结束条件。最直观的,如果一个节点中的数据集全为一个类别,那自然可以终止分化。或者,分化至该节点时,所有的特征都已经被使用过了,那也只能终止分化。而为了使整个模型较为经济,我们还可以考虑在最优特征的信息增益过小时,也即该特征的作用不大,没必要为了这一点点提升浪费计算性能,况且还可能有过拟合的问题,因此可以设定阈值,当最优特征的信息增益小于时,终止分化。
综上所述,结束条件有三条,分别为:
- 该节点的样本均为一类
- 该节点可筛选的特征集为空
- 该节点筛选出的最优特征的信息增益小于阈值
满足其中一条,则该节点可终止分化,并将该节点的预测类别设定为该节点的数据集中最多的一类(毕竟没办法保证最终的叶子节点样本是纯的一类,那就只能投票法用最多类别预测了)
将ID3算法详细写出(比较书面化的写法,上面的看懂了就很简单了)
输入: 训练数据集, 特征集阈值;
输出: 决策树。(1) 若中所有实例属于同一类, 则为单结点树, 并将类作为该结点的类标记, 返回;
(2) 若, 则为单结点树, 并将中实例数最大的类作为该结点的类标记, 返回;
(3) 否则, 计算中各特征对的信息增益, 选择信息增益最大的特征;
(4) 如果的信息增益小于阈值, 则置为单结点树, 并将中实例数最大的类作为该结点的类标记, 返回;
(5) 否则, 对的每一可能值, 依将分割为若干非空子集, 将中实例数最大的类作为标记, 构建子结点, 由结点及其子结点构成树, 返回;
(6) 对第个子结点, 以为训练集, 以为特征集, 递归地调用步(1)步(5), 得到子树, 返回。
ID3算法的不足
- 使用信息增益筛选特征时,存在偏向于取值较多的特征的问题
- 没有考虑连续型特征的处理方法
- 没有考虑过拟合的解决方案
C4.5算法
C4.5算法是对上述提出的3个不足进行改进后的决策树算法,其中过拟合问题,也就是决策树剪枝相关的内容,这里暂且不讲,下面让我们解决剩余的2个问题。
信息增益比
对于信息增益存在的偏向于取值较多的特征的问题的问题,引入一个新的指标对其进行修正,也就是信息增益比,具体定义为
其中,,也就是特征的信息熵。
让我们来好好看看这个公式,其中是在ID3算法中使用的信息增益,而特征的信息熵又是什么呢。还记得数据集的信息熵吗,就是只看类别这一列,然后代入信息熵的定义计算,具体为
而特征的信息熵就是只看特征这一列,然后代入信息熵的定义计算,现在看懂了吗。
C4.5算法使用信息增益比作为特征筛选的指标。
连续型特征的处理方法
对于连续型特征,一个很自然的想法是将其分为多个区间,根据其属于不同的区间划分为不同的子节点,也就是将其转换为离散型变量,属于不同的区间就是属于不同的类别。比如还是回到最开始的信贷问题,现在引入一个特征“年龄”,现在选取“年龄”作划分,小于50岁的划到一个节点,大于50岁的划到另一个节点,这就达到了使用连续型特征的目的。
那么根据上述的思路,相比离散型数据会有什么需要特别的地方呢。首先,要怎么划分区间是最好的。这里面还会有几个子问题,第一,要划分为几个区间,第二,如何选取划分点,而且对于连续型特征来说,可选取的划分点是无限的,这也是一个不好处理的问题。其次,连续型特征在可以被多次使用。比如,“是否有自己的房子”这个特征,使用一次后便会被从特征集中删除,不能被再次使用。而“年龄”这个特征,划分为大于小于50岁后,在其子节点,我还可以继续划分为小于25岁,大于25岁小于50岁,如下图。因此,连续型变量不会被从特征集中删除。
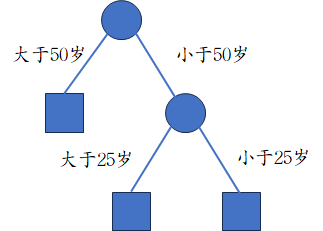
接下来我们就说说C4.5算法是如何进行区间划分的。首先,划分为多少个区间的问题,C4.5算法直接默认设定为2个,然后是如何选取划分点的问题,首先,C4.5算法会计算出有限的划分点供选择,具体的来说,假设该节点有个样本,将其连续型特征的取值从小到大排列,记为,将所有相邻的两个取值做平均,得到个点,记为,这个点就作为划分点的候选,最后,分别使用这个点进行划分,并计算其信息增益比,选择信息增益比最大的划分点作为最终划分点。
C4.5算法的不足
- C4.5算法生成的决策树是多叉树,在计算机中,二叉树的运算效率会更高
- C4.5算法只能用于分类问题
- C4.5算法使用的信息增益比中含有大量的对数运算,连续型变量的处理方法中也含有大量的排序运算,其运算效率较低
总结
本文介绍了ID3与C4.5两种决策树算法,但其都是决策树算法发展历史中的产物,介绍这两种算法是为了帮助读者更好的理解决策树算法,下半部分将介绍CART算法,也就是现在最常用的决策树算法,同时还会介绍其在sklearn中相应的API。下篇请看决策树(下)——CART算法及其代码实现





