
随机森林原理与代码实现
前言
随机森林(Random Forest,简称RF)是一种在机器学习中被广泛运用的算法,其基于决策树算法与Bagging的集成学习思想,具有运行速度快,可并行训练,对数据包容性强等特点。本文将介绍随机森林的原理(主要是如何结合决策树与Bagging,及其相关的改进),并且介绍其在sklearn中的代码实现。
从Bagging到随机森林
随机森林是基于Bagging思想的,故我们先来回顾一下Bagging的框架,其流程图如下
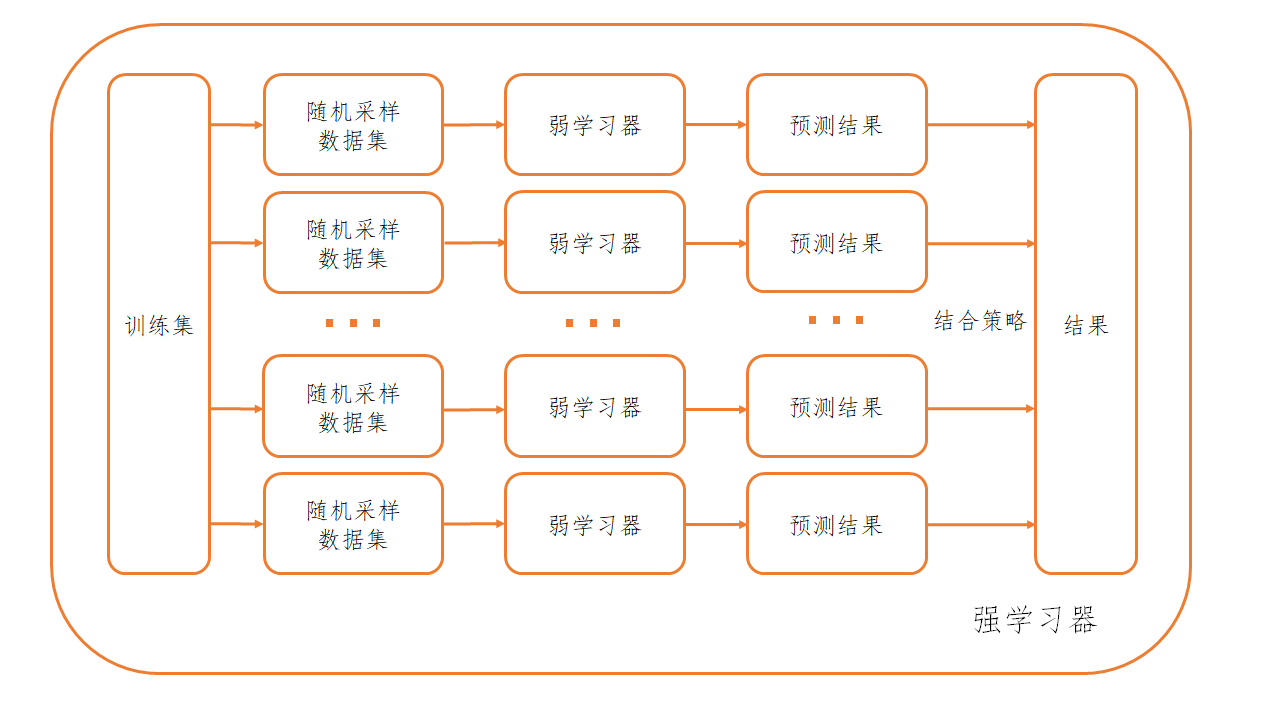
现在,根据上述流程图,我们在这个框架中填入随机森林的具体内容
随机采样:随机森林采用的是有放回随机采样,一般来说,会对大小为的训练集进行次有放回随机采样
弱学习器:随机森林使用的弱学习器是决策树
结合策略:随机森林对分类问题使用投票法,对回归问题使用平均法,一般不会进行加权
填入上述内容之后,这个Bagging的框架就成了一个具体的算法,而这就是随机森林
补充:
对于随机森林使用的随机采样方法,每一个随机采样出的数据集会包含左右的数据,理论推导如下:
假设训练集大小为,则每个样本在一次采样中被采样到的概率为,则一个样本在次随机采样中都没有被采样的概率为,当样本量足够大时,这个概率会收敛,也就是
也就是说,大概会有的样本不会被采样,这部分数据被成为袋外数据。
sklearn代码实现
最后我们来介绍一下线性回归的sklearn代码实现,运行环境为jupyter notebook
注1:
sklearn是机器学习中常用的python库,其封装了大多数常见的机器学习算法,使得复杂的机器学习算法可以在短短几行代码中被实现,俗称“调包”(bushi。下面的内容会建立在对sklearn有简单了解的基础上,没有接触过sklearn的读者可移步sklearn快速入门作简单了解。注2:以下内容会介绍实现算法的函数及其重要参数,并且用
sklearn中自带的小型数据集跑一个简单的demo。主要目的是将sklearn中的参数跟理论部分做一个对照,知道理论部分中讲到的参数在sklearn中是哪个,怎么调。还有就是简单把这个算法跑一遍,不过由于机器学习是一门以实践为主的学科,我们用sklearn中自带的小型数据集做的demo的作用也就仅此而已了,其对实际工程中的调参没有任何参考意义,仅仅是告诉你这个算法怎么跑起来。注3:本文并不会把函数的细节讲得面面俱到,甚至参数都只是调重要或常用的讲,想要详细了解的可以参考sklearn官方文档或者sklearn中文文档。
我们先做一些前期工作,导入依赖库
1 | import matplotlib.pyplot as plt |
我们使用红酒数据集与糖尿病数据集作为示例数据,这里我们使用sklearn自带的数据模块,读取数据代码为
1 | # 读取数据 |
1 | # 提取特征与标签(红酒数据集) |
1 | # 提取特征与标签(糖尿病数据集) |
好,做完准备工作我们正式开始讲算法实现。
在sklearn中,实现随机森林的函数为RandomForestClassifier()与RandomForestRegressor(),两个函数分别负责处理分类问题与回归问题,这与决策树相同。由于随机森林是决策树与Bagging思想的结合,因此其参数也可以分为决策树部分与Bagging部分,下面我们分类来看。
决策树参数
首先是决策树参数,由于随机森林是以决策树作为弱学习器的,所以决策树的所有参数随机森林都有,RandomForestClassifier()函数的有分类树有的所有参数,填法也跟分类树相同,RandomForestRegressor()当然就是跟回归树相同啦。这里就罗列一些最常用的,权当回归一下
criterion:特征选择指标,分类树就是基尼系数与信息增益,回归树就是MSE与MAE
max_depth:最大深度
min_samples_leaf & min_samples_split:节点或子节点需要包含的最少训练样本
min_impurity_decrease:限制信息增益
max_features:限制特征数
random_state:随机数种子,用于随机选择特征,保证每次训练得到的结果一致。
这里需要更多讲一下的就是random_state,这个参数的效果与决策树相同,就是特征选择时会不看完所有的特征,但是需要注意的是,随机森林由于本身计算量就大于决策树,并且其本身有产生差异性学习器的需求,因此随机森林在特征选择时考虑的特征相比单科决策树会更少(如果说,单科决策树会考虑8成的特征,那随机森林可能每棵树只看一半的特征)。
Bagging参数
最后就是Bagging思想部分的参数,这部分的参数不多,并且对分类与回归问题都是通用的
n_estimators:决策树数量,可以说是随机森林最重要的参数
oob_score:是否使用袋外数据进行测试,默认为False
bootstrap:是否使用有放回随机抽样,默认为Ture,一般不会动
示例
讲完了参数,最后就是用示例数据集把算法跑起来了,首先是分类问题,使用红酒数据集作为示例数据集,首先对红酒数据集进行训练集与测试集的划分
1 | # 划分训练集与测试集 |
然后就是sklearn建模经典代码卡
1 | # 随机森林 |
上面说到,n_estimators是随机森林算法中最重要的参数,毕竟是集成学习算法,主打的就是一个力大砖飞。因此随机森林的调参最关键的也就是调整n_estimators参数,一般使用超参数曲线来搜索最佳的数值,下面是绘制超参数曲线的兼用卡代码
1 | # 调参 |
当然,sklearn还提供了一些好用的方法与属性供我们使用,下面我们讲一些常用的。接触过sklearn的应该都知道predict()方法,该方法用于使用训练好的模型进行预测。但是前面我们提到,在分类问题中,随机森林使用的是投票法,因此对于一个数据,我们实际上是可以得到其被分到每一个类别的票数的,也可以理解为该数据被分到每一类的概率,而上述内容可以通过predict_proba()方法实现
1 | clf = RandomForestClassifier(n_estimators=45) |
使用predict()方法,其输出结果为我们提前编码好的类别
1 | array([1, 2, 2, 0, 0, 0, 0, 2, 1, 0, 1, 1, 2, 1, 0, 2, 1, 1, 0, 1, 1, 2, |
下面我们使用predict_proba()方法
1 | clf.predict_proba(Xtest) # 返回被分到每个类的概率 |
其输出结果为一个矩阵,每一个数据都有被分类到每一个类别的概率
1 | array([[0.13333333, 0.8 , 0.06666667], |
注:上面也说过了,这个概率值其实就是各类别获得的票数占总票数的比例,因此这个方法是分类问题独有的!!
接着是一些常用的属性,首先随机森林以决策树作为基础,那自然也继承了决策树的优良属性,没错,我说的就是feature_importances_属性。由于决策树的特性,在决策树的构建的同时,所有的特征会被打分,而这个分数可以成为衡量特征重要性的一个参考,而特征重要性就可以通过调用该属性输出。
1 | # 属性:特征重要性 |
1 | array([0.15588695, 0.03815767, 0.0092663 , 0.02084591, 0.02503749, |
还有一个常用的属性,我们在讲Bagging部分的时候提到过,随机森林的构建过程中,每一棵树大概会有的数据不会被使用,而即使是完整的随机森林构建过程,也常常会有数据没有被任何一棵树所使用,这部分数据被我们称为袋外数据。到这里我们可以想到,既然这个数据对于我们构建的随机森林来说是没有见过的,那我们是不是就可以讲袋外数据作为一个小测试集,用于辅助测试随机森林的效果呢。sklearn中提供了一个参数oob_score,以及一个属性oob_score_,将两者配合就可以得到使用袋外数据作为测试集的测试结果,具体代码如下
1 | # 属性:袋外数据测试结果 |
将参数oob_score设置为True,再在训练完成后调用属性oob_score_,就可以得到袋外数据的测试结果
1 | 0.9647887323943662 |
最后是回归问题,使用糖尿病数据集作为示例数据集,首先对糖尿病数据集进行训练集与测试集的划分
1 | # 划分训练集与测试集 |
其实回归问题除了没有predict_proba()方法之外,其余部分与分类问题的是基本一致的,也是优先调整n_estimators参数,也可以输出特征重要性,以及使用袋外数据进行测试,这里就简单附上建模代码,不展开了
1 | # 随机森林 |
总结
随机森林算法结合了决策树算法与Bagging集成学习思想,具有训练快,泛用性强等优点,同时相比决策树算法,提高了复杂度与随机性,使得其可以适用于更复杂的数据,也因此,其在工业界被广泛运用。




