前言
泛化误差可以分解为偏差平方,方差与随机噪声平方之和,也就是E(f;D)=bias2(x)+var(x)+ε2,是统计学习中一个非常重要的结论。本文将会给出该公式的详细推导过程,并且给出这个公式对实际机器学习建模的指导。
方差-偏差分解
概念
泛化误差:指机器学习模型在训练集之外的数据集的表现,一般来说,机器学习建模与调参就是在追求最优的泛化误差
偏差:指机器学习模型的预测结果与实际结果的距离,也就是预测结果的准度
方差:指机器学习模型的预测结果之间的距离,也就是预测结果的波动程度
具体表现如下图
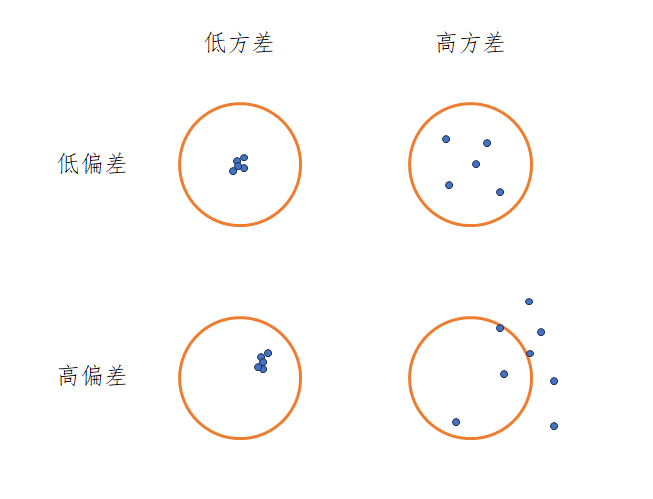
可以看到偏差越低,预测值距离中心,即真实值更近,方差越低,预测值越集中。
公式推导
首先,我们假设真实的x与y之间存在关系y=f(x)+ε,其中的ε为随机噪声,我们假设其独立并服从均值为0方差为σ2的正态分布。现在,记我们训练出的机器学习模型为f^,也就是说,模型的预测结果为f^(x)。那么,泛化误差可以写为E[(y−f^(x))2],偏差可以写为(f−E[f^]),方差根据定义可写为E[(f^−E[f^])2]
E[(y−f^(x))2]=E[(f+ε−f^)2]=E[((f−E[f^])−(f^−E[f^])+ε)2]=E[(f−E[f^])2+(f^−E[f^])2+ε2+⋯]=E[(f−E[f^])2]+E[(f^−E[f^])2]+E[ε2]+E[⋯]=(f−E[f^])2+E[(f^−E[f^])2]+σ2=bias2[f^]+var[f^]+σ2
上述推导过程中的⋯代表将平方拆开后的交叉项,交叉项的期望E[⋯]为0,下面我们来看看交叉项的处理方法
E[⋯]=E[2(f−E[f^])ε]+E[2E[f^](f^−E[f^])]−E[2f(f^−E[f^])]−E[2ε(f^−E[f^])]
首先,ε独立,且E[ε]=0,故
E[2(f−E[f^])ε]=2E[(f−E[f^])]E[ε]=0E[2ε(f^−E[f^])]=2E[ε]E[(f^−E[f^])]=0
然后我们来处理剩下的两项
E[2E[f^](f^−E[f^])]=E[2E[f^]f^−2E[f^]E[f^])]=2E[f^]E[f^]−2E[f^]E[f^]=0
由于E[f^]是常量,所以可以从期望运算中直接提出
E[2f(f^−E[f^])]=E[2ff^−2fE[f^])]=2E[f]E[f^]−2E[f]E[f^]=0
由于f与f^相互独立,故E[ff^]=E[f]E[f^]
实际意义
方差-偏差分解与拟合程度
将泛化误差与偏差方差的关系可视化,如下图
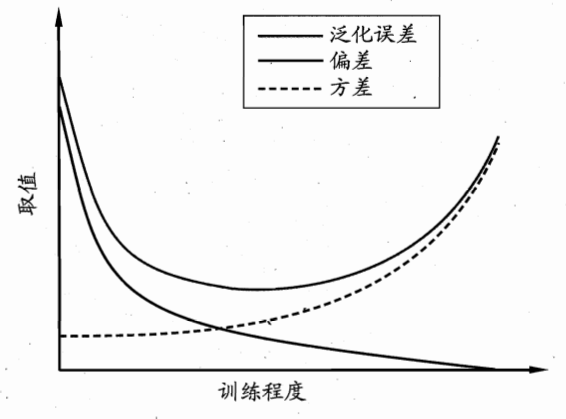
可以看到,一开始是偏差主导泛化误差,也就是欠拟合的情况,而在过了最佳泛化误差点后,则是方差主导泛化误差,这也就是过拟合。
调参策略
从上述结论我们可以想到,我们要降低泛化误差可以通过降低偏差,方差与噪声来实现
降低偏差:偏差过高的情况是模型的学习能力不够,可以通过增加模型的复杂度来降低偏差,比如换用复杂度更高的模型,使用集成学习(Boosting),增加神经网络的层数等。
降低方差:方差过高的情况是模型过拟合或者数据代表性不足的问题,可以通过处理过拟合的方法来解决,如正则化,剪枝等,也可以通过优化数据来解决,如特征工程。
降低噪声:在统计学习中这属于不可优化的部分,但是在实际场景中,可以通过优化数据获取端来达到降低噪声的目的,如更干净准确的数据采集。





