
sklearn读取图像数据的方法
前言
在使用sklearn进行机器学习建模时,由于sklearn本身没有针对图像数据的模块,如Pytorch就有可以将图像数据读取为tensor的模块。所以涉及到与图像数据相关的机器学习问题时,就需要借助其余的库将图像数据读取为numpy数组。本文介绍如何使用skimage库进行图像数据的读取。
skimage读取图像数据
图像数据的组成
在计算机看来,任何数据都是数字,图像也同理。我们先从黑白图像开始,我们都知道图像是由像素点组成的,因此可以使用数字来表示一个像素点的颜色,假设数字0代表白色,数字255代表黑色,而在0到255之间的整数代表灰色(数字越大颜色越接近黑色),那么每一个像素点都可以表示为一个属于的数字。那么,一张28*28的黑白图像就可以表示为28*28个数字。在计算机中,这可以用一个(28, 28)的二维数组表示,也可以用一个长度为784的一维数组表示,并记录图像大小为28*28。
然后我们再来看常见的彩色图像。这里我们需要了解RGB,我们来看看百科的描述:RGB色彩模式是工业界的一种颜色标准,是通过对红(R)、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,RGB即是代表红、绿、蓝三个通道的颜色,这个标准几乎包括了人类视力所能感知的所有颜色,是运用最广的颜色系统之一。如果使用RGB色彩模式来表示像素点的颜色,那么彩色图像的像素点的颜色可以由三个属于的数字表示,也就是说一张28*28的彩色图像就可以表示为28*28*3个数字。在计算机中,这可以用一个(28, 28, 3)的三维数组表示。(注:一张大小为(x, y, z)的图像可以读为x行y列的z通道图像)
读取图像数据与常用操作
读取图像
现在我们来看看skimage库如何读取图像数据,读取图像数据的函数都属于io模块,下面我们来读取单张图像,首先导入需要的库
1 | from skimage import io # 读取图像数据 |
然后我们来读取一张黑白图像,这里我们使用经典的手写数字数据集MNIST
1 | img = io.imread('./mnist_train/0/mnist_train_1.png', as_gray=False) # 第一个参数是文件名可以是网络地址,第二个参数默认为False,True时为灰度图 |
可以看到其类型为numpy.ndarray,尺寸为(28, 28)。接着我们显示图像
1 | io.imshow(img) # 显示图片 |
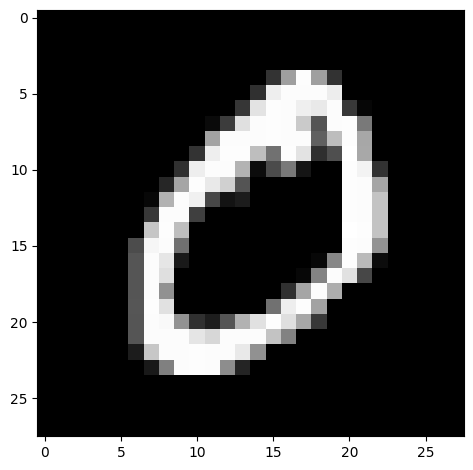
同理,我们来读取一张彩色图像,这里我们读一张壁纸
1 | img = io.imread('君の名は.jpg') |
尺寸为(1080, 1920, 3),图像显示为
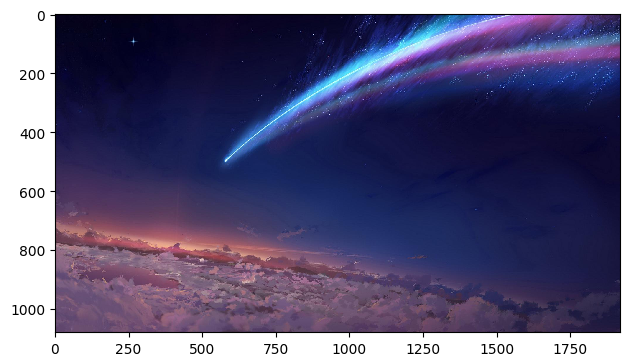
图像常用操作
在做机器学习建模的情况下,对图像的常用操作有两个,调整图像尺寸与将图像数据转化为向量。首先是调整图像尺寸,由于在图像数据收集的过程中,很容易出现图像数据大小不一的情况,这时候就需要将图像调整为统一尺寸,这可以通过transform模块中的resize()函数来实现。例如,现在我们要将上面读取的壁纸调整为300*300的大小
1 | from skimage import transform |
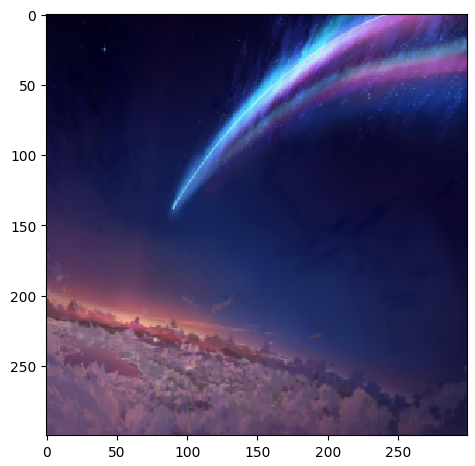
然后是将图像数据转化为向量,这是因为机器学习模型对数据输入的要求。我们来回忆一下机器学习模型的数据,是由样本和特征组成的(当然还有标签),而对于图像数据来说,每一张图像是一个样本,至于特征,我们可以简单粗暴的将每一个像素点都视为一个特征(这会有很多的缺点,当然也会有其对应的技术来克服这些缺点),而每张图像是二或三维的,因此我们需要将其转化为一维的向量。由于skimage库读取的图像数据是numpy数组,因此我们直接使用numpy的方法进行转化即可。
1 | img = np.reshape(img, -1) # 将图像数据拉成一维 |
可以看到,数据的尺寸由(300, 300, 3)转换为了(270000,)
批量读取图像数据
接着是批量读取数据的方法,这当然可以用循环结合imread()函数实现,不过效率更高的方法是用io模块里的ImageCollection()函数来进行图像的批量读取,具体语法如下
1 | io.ImageCollection(str) |
其中,参数str需要填文件夹名加图片后缀,例如填入'./train/*.jpg',代表读取程序目录下文件夹train中的所有jpg格式的图片。如果图片数据包含不止一种格式,可以填入'./train/*.jpg:./train/*.png',注意中间用:分隔。
现在,我们来读取MNIST数据集中所有数字0的图片,代码如下
1 | img = io.ImageCollection("./mnist_test/0/*.png") |
可以看到类型为skimage.io.collection.ImageCollection,这是一个图片集合,并不是numpy数组,使用len()可以查看图片数量。使用索引可以提取出单个图像数据
1 | type(img[0]) |
可以看到,提取出的单个图像类型为numpy.ndarray。
读取MNIST数据集并进行建模
了解完读取图像数据的方法后,我们来将整个MNIST数据集读取为numpy,并使用sklearn进行机器学习建模。首先让我们来看看MNIST数据集长什么样,其训练集与测试集分别放在两个文件夹中
![]()
每一个文件夹中又有数字0-9共10个文件夹,分别存放10个数字的图像
我们需要做的是,读取每一张图像数据,将其拉为一维数组,并在数组最后加上标签,即数字0-9,并将其放到同一个numpy数组中。完整代码如下
1 | # 读取数据 |
1 | train.shape |
可以看到train与test的尺寸分别为(60000, 785)与(10000, 785)。可以看到训练集有60000个样本,测试集有10000个样本,特征均为784个(最后一个为标签)。
最后,我们对MNIST进行简单的建模,首先将特征与标签分开
1 | # 特征与标签 |
由于图像数据将每一个像素点都当做一个特征,所以即使是28*28这种尺寸很小的图片,特征量还是很爆炸的,这会导致训练模型的时候很慢。但是这种情况下,其实会存在很多信息量很小的特征,所以,一些特征工程的技术对图像数据会有奇效,这里用最常用的PCA降维来进行特征选择
1 | # PCA降维 |
可以看到,保留了90%的信息的情况下,特征数直接从784个降到了46个,这对我们后续的模型训练是非常友好的,最后我们就可以跑一些常见的模型,基本上都能有非常好的效果
1 | # 划分训练集测试集 |
1 | # K近邻 |
1 | # 随机森林 |




