
特征工程:特征选择常用方法
前言
特征工程简介
在机器学习建模的过程中,特征工程是非常重要的一步,在深度学习流行之前,一个机器学习模型的质量主要就取决于特征工程。并且,特征工程更多的需要依靠工程与业务上的经验,而非一个个确定的方法。
特征工程可以分为三个部分,特征提取,特征创造,特征选择
特征提取:从文字,图像,声音等其他非结构化数据中提取新信息作为特征。
特征创造:通过对现有特征的组合,得到新的特征,类似于回归中的交叉项。一般依靠业务经验与尝试。
特征选择:从现有特征中提取出对模型贡献最大的特征,追求用最少的特征跑出最好的模型。一般依靠业务经验筛选与客观筛选方法。
注:在进行特征工程之前一定要尽可能了解业务,有时候业务的经验比筛半天特征有用!
本文将介绍特征选择常用的方法。
准备工作
本文我们使用MNIST手写数字数据集来做示例,因为其特征数量大,且特征没有实际意义,因为全是像素点嘛,所以很适合用于演示客观的特征选择方法。先导入需要的库(全文需要用到的库都在这里了)
1 | import matplotlib.pyplot as plt |
再读取数据集,读取图像数据的方法可见sklearn读取图像数据的方法
1 | # 读取数据 |
1 | # 提取特征与标签 |
该数据共有784个特征,接下来我们来进行特征工程,看看最终能将其筛选到多少个特征。
过滤法
过滤法就是通过一些统计指标来筛选对标签贡献很小的特征,适用性很强,运行速度快,但是效果有限,只能筛选掉少量特征,一般用于初步筛选。
方差过滤
方差用于衡量数据的差异性,在信息学中,方差越大被认为具有更多的信息,因此可以通过特征的方差大小来筛掉方差过小的特征,可以通过sklearn.feature_selection中的VarianceThreshold来实现。
当然在特征工程中,这并不完全正确。例如,对于评三好学生这个需求来说,迟到次数与被处分次数,显然是被处分次数这个特征的方差更小,一般都不太会有处分产生,但是因此断定被处分次数这个特征可以被筛选掉,是不合适的。
但是可以确定的是,如果在特征中,一个特征的方差为0,这就代表这个特征只有一个取值,那么这个特征对于训练来说是没有任何意义的,所以对于方差为0的特征可以直接筛掉,VarianceThreshold默认也是筛掉方差为0的特征。
1 | # 使用方差过滤(过滤方差为0的特征) |
VarianceThreshold与sklearn其他模块的用法相同,都是实例化,然后fit训练,transform进行转化,可以用fit_transform同时进行。通过过滤方差为0的特征,可以将784个特征过滤到717个。
相关性过滤
方差过滤是从特征自身的角度去进行筛选,而特征选择还需要考虑的就是特征对标签的贡献,这可以用相关性来衡量。如果特征与标签的相关性过低,那么就可以筛掉这个特征。相关性过滤可以使用的方法有度量相关性的指标,如相关系数,互信息等,假设检验,如卡方检验,F检验,T检验等。这里我们弱化原理,着重介绍代码实现。这部分的特征选择,都需要用到sklearn.feature_selection中的SelectKBest函数,这个函数语法如下
1 | SelectKBest(score_func=<function f_classif>, k) |
两个参数分别为评分函数与特征个数,其作用是根据评分函数的评分筛选出k个特征。而不同的筛选方法就需要填入不同的评分函数,再通过学习曲线或P值(假设检验可用)来选择最合适的k值。
卡方检验
下面以卡方检验为例,计算卡方的函数为sklearn.feature_selection中的chi2,假设我们要筛选出500个特征,代码如下
1 | # 使用卡方检验过滤 |
上述代码的意思就是,以卡方为指标,筛选出500个特征。需要注意的是,fit时需要将特征与标签一起输入。
接下来还有一个问题,就是如何选择合适的k值,假设检验类的方法一般借助P值来确定k值。P值是假设检验中用于判断是否拒绝原假设的一个阈值,这个值是人为设定的,一般为0.05。这里我们不深究假设检验的原理,代码可以直接帮我们计算出P值,我们只需要计算出有多少个特征的P值小于阈值,并将其作为k值即可,代码如下
1 | # 用P值确定k值 |
F检验
其余检验指标,也是一样的流程,再来看看F检验,计算F的函数为sklearn.feature_selection中的f_classif与f_regression,分别用于分类与回归问题。用F检验筛选特征的代码
1 | # F检验 |
对比卡方检验就是换了个指标。
互信息
再来看看一些用相关性指标筛选的,如互信息MIC,这是一个用于衡量相关性的指标,大小位于之间,越接近1代表相关性越强。相比Pearson相关系数,MIC可以捕捉到线性与非线性的关系。可以使用sklearn.feature_selection中的mutual_info_classif与.mutual_info_regression来计算互信息,这分别用于分类与回归问题。一般可以直接筛掉MIC为0的特征,代码如下
1 | result = MIC(data, target) |
对于相关性指标类的筛选方法,可以使用学习曲线来确定k值,代码如下
1 | # 绘制学习曲线 |
这里用随机森林作为评估特征选择效果的模型,缺点是运行速度较慢。
嵌入法
嵌入法(Embedded)是一种基于机器学习模型的特征选择方法,对于线性模型与树模型来说,其训练过程中会产生衡量特征对模型的贡献度的评分,而嵌入法就是根据该评分进行特征筛选。
注1:判断方法是具有
coef_,feature_importances_属性或参数中可选惩罚项的模型就可以用于嵌入法注2:嵌入法中使用的模型只用于特征筛选,并不代表最终就要使用该模型,例如你可以用基于随机森林的嵌入法筛选出的特征去跑K近邻,这是完全没问题的
嵌入法可以使用sklearn.feature_selection中的SelectFromModel实现,其参数列表如下:
| 参数 | 说明 |
|---|---|
| estimator | object 用来构建transformer的基本估计器。既可以是拟合的(如果prefit设置为True),也可以是不拟合的估计器。这个估计器拟合之后必须具有feature_importances_或coef_属性。 |
| threshold | string, float, optional default None 用于特征选择的阈值。保留重要性更高或相等的特征,而其他特征则被丢弃。如果为“median”(或“mean”),则该threshold值为要素重要性的中位数(或均值)。也可以使用缩放因子(例如,“ 1.25 *平均值”)。如果为None(无),并且估计器的参数惩罚显式或隐式设置为L1(例如Lasso),则使用的阈值为1e-5。否则,默认使用“mean”。 |
| prefit | bool, default False 预设模型是否直接传递给构造函数。如果为True,transform必须直接调用并且SelectFromModel不能使用cross_val_score,GridSearchCV和与此估计类似的实用程序。否则,使用训练模型fit,然后transform进行特征选择。 |
| norm_order | non-zero int, inf, -inf, default 1 在估算器threshold的coef_属性为维度2的情况下,用于过滤以下系数向量的范数的阶数。 |
| max_features | int or None, optional 要选择的最大特征数。若要仅基于max_features选择,请设置threshold=-np.inf。 |
我们主要关注的是前两个参数,也就是模型与阈值。
树模型
首先我们来看树模型,树模型以feature_importances_属性作为特征选择的指标,这里我们以随机森林为例,随便设置一个阈值做特征筛选
1 | # 使用嵌入法进行特征选择(随机森林) |
可以看到,在嵌入法中,我们需要选择的超参数是threshold,在树模型中,threshold代表feature_importances_属性的阈值,可以使用学习曲线来确定最佳的threshold取值,代码如下
1 | # 绘制嵌入法阈值的参数曲线 |
学习曲线如下
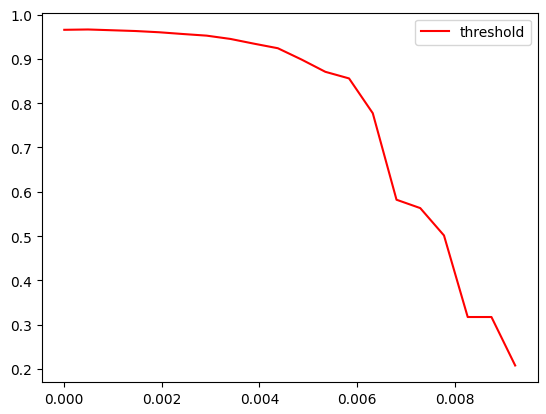
由于不同的特征量会导致feature_importances_差距很大,所以这里用np.linspace在0到最高得分之间划分20个点绘制学习曲线,后续还可以继续缩小范围寻找更优的超参数。这里我们就取0.004
1 | clf = RandomForestClassifier(n_estimators=100, random_state=1008) |
可以看到,相较于过滤法筛选出的600+个特征,嵌入法可以直接将特征数降低至两位数,并且在随机森林上可以得到90%以上的准确度,这对于后续的模型训练以及上线是非常大的优化。还有,对于K近邻这种运算速度慢的模型来说,这个数量的特征就是可以接受的了(K近邻在MNIST上的效果很好,但是MNIST原始特征量太大了),使用经过筛选的特征,再经过调参,MNIST数据在随机森林与K近邻上都是可以跑到97%以上的准确性的,这里就不做演示了。
线性模型
接着是线性模型,线性模型以coef_属性作为特征选择的指标,这里我们以逻辑回归为例,threshold代表coef_属性的阈值
1 | clf = LogisticRegression() |
同理,可以用学习曲线来确定最优的超参数。
但是需要注意的是,线性模型可以使用正则化,正则化本身就有筛选特征的作用,正则化会将需要筛选的特征的coef_属性减小,用正则化将需要筛掉的特征得分变小,然后再通过嵌入法设置阈值筛选特征,可以有更好的效果。尤其是L1正则化,因为L1正则化会将特征的得分压缩至0,因此可以直接将阈值设置为一个很小的值进行特征选择,不需要绘制学习曲线。
1 | # 使用嵌入法进行特征选择(逻辑回归) |
在使用了正则化的情况下,要调整特征筛选的阈值,调整threshold的意义其实不大,应该调整的是正则化的强度,也就是参数C,可以通过绘制C的学习曲线来筛选最合适的超参数。
1 | # 绘制C的参数曲线 |
包装法
包装法(Wrapper)也是一种基于机器学习模型的特征选择方法,但是不同的是,包装法会借助一个目标函数进行特征选择,而我们只需要给定需要的特征数即可。最常用的方法是递归特征消除(RFE),这可以使用sklearn.feature_selection中的RFE实现,这个算法会通过递归,根据给定模型的评估指标,每次筛选掉一部分特征,多次筛选至设定的特征数后停止递归,其参数列表如下
| 参数 | 说明 |
|---|---|
| estimator | object 一种监督学习估计器,其fit方法通过coef_ 属性或feature_importances_属性提供有关特征重要性的信息。 |
| n_features_to_select | int or None (default=None) 要选择的特征数量。如果为None,则选择一半特征。 |
| step | int or float, optional (default=1) 如果大于或等于1,则step对应于每次迭代要删除的特征个数(整数)。如果在(0.0,1.0)之内,则step对应于每次迭代要删除的特征的百分比(向下舍入)。 |
| verbose | int, (default=0) 控制输出的详细程度。 |
我们主要关注前三个参数,可以看出n_features_to_select是我们需要确定的超参数,我们可以通过绘制学习曲线来确定这个超参数,代码如下
1 | # 绘制包装法参数曲线 |
学习曲线如下
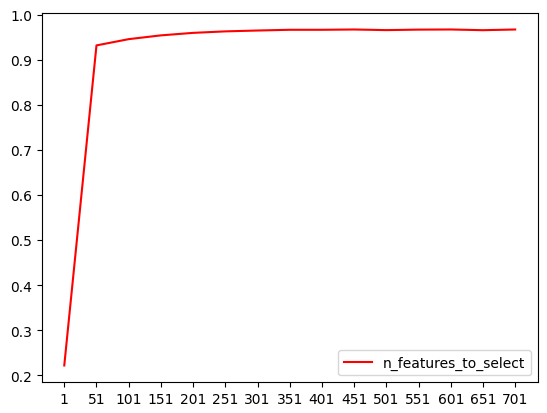
根据学习曲线,我们可以发现在特征达到51时就已经可以得到90%以上的结果了,还可以在51附近进一步搜索,这里就直接选择51了。
1 | selector = RFE(clf, n_features_to_select=51, step=10) |
包装法还有两个重要的属性
1 | selector.support_ # 返回所有的特征的是否最后被选中的布尔矩阵 |
总结
本文介绍了特征选择的常用方法,以及其对应的sklearn代码实现。首先是过滤法,过滤法就是用一些统计学指标来进行特征筛选,主要是用于初步筛选一些真的太没用的特征。然后是嵌入法与包装法,都是基于树模型与线性模型,这类训练过程中会计算出特征分数的模型来进行特征筛选的,嵌入法会根据分数直接筛选至指定数量,而包装法则会进行多次迭代筛选,一般均用于最大程度的筛选特征,缺点是运行速度慢。




