
机器学习通用技术:学习曲线
学习曲线简介
在机器学习中,学习曲线(learning curve)是一种用于评估模型性能和训练样本数量之间关系的可视化工具。学习曲线通常将模型在训练集和验证集(或测试集)上的**性能指标(如准确率、均方误差等)**与训练样本数量进行比较。下面是一张学习曲线的示例图
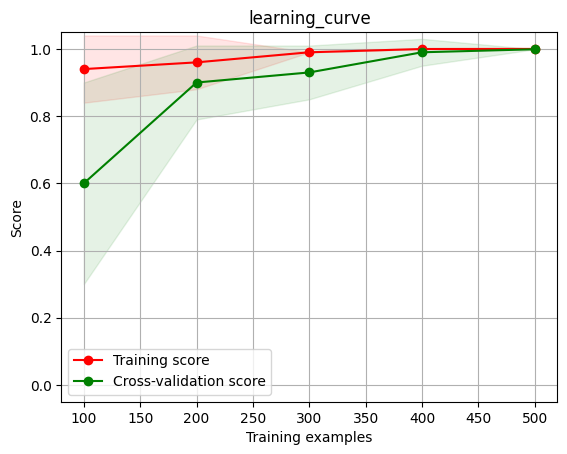
学习曲线的横轴表示训练样本的数量,纵轴表示模型的性能指标。曲线上的点表示在给定训练样本数量下,模型在训练集和验证集上的性能。通常情况下,学习曲线会随着训练样本数量的增加而变化。通过观察学习曲线,可以判断模型的拟合情况以及是否需要增加更多的训练样本。如果模型在训练集和验证集上的性能指标都较低,可能需要更复杂的模型或者更多的特征。如果模型在训练集上表现很好但在验证集上表现较差,可能需要减小模型的复杂度或者增加更多的训练样本。学习曲线为我们提供了一个直观的方式来评估模型的性能和训练样本数量之间的关系,并帮助我们优化模型的表现。
sklearn绘制学习曲线
在sklearn中,其为我们提供了绘制学习曲线的函数,也就是sklearn.model_selection中的learning_curve函数,但是其并不会直接绘制出图像,而是仅仅计算图像的数据,绘图代码则需要我们自己编写。
learning_curve函数
下面我们先来看一看learning_curve函数的常用参数列表
| 参数 | 说明 |
|---|---|
| estimator | 机器学习模型,类型为sklearn实例化对象 |
| X | 训练数据的特征部分 |
| y | 训练数据的标签部分 |
| train_sizes | 用于生成学习曲线的相对数量的训练样本,这是一个比例值数组,即所有值必须在(0,1]之内,如输入(0.3, 0.6, 0.9),则会进行3次训练,第一次使用30%的数据,第二次使用60%,第三次使用90%。其默认为np.linspace(0.1, 1.0, 5)。 |
| cv | 交叉验证折数,默认为5 |
| n_jobs | 用于进行计算的CPU数量 |
一般的其有3个返回值,即
1 | train_sizes, train_scores, test_scores = learning_curve() |
分别代表
| 返回值 | 说明 |
|---|---|
| train_sizes | 用于训练的样本数,也就是X轴 |
| train_scores | 训练集准确率,y轴之一 |
| test_scores | 测试集准确率,y轴之一 |
其中返回值train_scores与test_scores都是大小为的矩阵。
学习曲线绘制
得到返回值后,我们就可以开始绘制学习曲线了,首先X轴自然是train_sizes,而y轴则是对应的train_scores与test_scores,但是由于学习曲线使用了交叉验证,因此一个train_sizes会有cv个结果,对此我们需要对其取均值,也就是
1 | train_scores_mean = np.mean(train_scores, axis=1) |
这样我们就得到了y轴的值,使用matplotlib进行绘图,其核心代码为
1 | plt.plot(train_sizes, train_scores_mean, 'o-', color="r",label="Training score") |
当然,除了评价指标,也就是偏差之外,我们还关注方差,因为根据理论,我们最终关心的泛化误差可以被分解为偏差与方差,具体内容与公式推导可以移步机器学习理论——泛化误差、方差与偏差。故我们可以在学习曲线中也加入方差,首先计算方差
1 | train_scores_std = np.std(train_scores, axis=1) |
而方差的表现形式也就是示例图中曲线两边的部分,其面积越大,代表其方差越大,该部分的核心绘图代码为
1 | plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r") |
至此,我们完成了学习曲线的绘制,由于sklearn官方并没有给出绘图的函数,而每次写这么一大段代码也实属不方便,因此大家一般会将上述绘图过程封装为一个函数,方便自己调用。大家在网上可以看到各种版本的学习曲线绘制函数,基本上大同小异,这里分享我自用的学习曲线绘制函数
1 | # 定义绘制学习曲线函数 |
建议大家理解学习曲线绘图的代码后,根据自己的绘图习惯,写一个自己的plot_learning_curve(),并保存下来以便日后使用。
理解学习曲线
最后介绍如何通过看学习曲线来判断模型的现状,我们通过几个例子来说明(都是以正确率作为指标),首先是最开始展示的示例图
这可以说是一张很理想学习曲线图,训练集与测试集的正确率都很高,并且方差也很小。
然后我们在来看看下一张
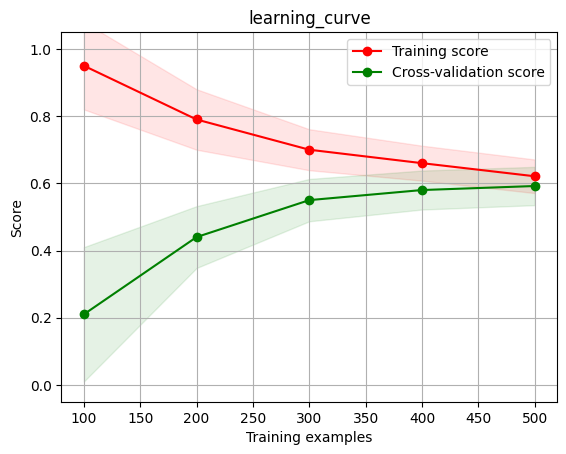
这是典型的欠拟合学习曲线,为什么呢?我们来分析一下这张图,训练集在样本量小的时候正确率还可以,但是随着样本量增加逐渐下降,这就说明当前的模型复杂度不足以描述该数据集,也就是欠拟合。
接着是这张
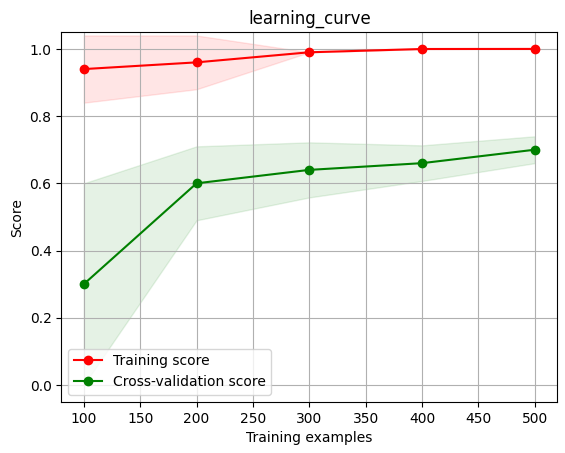
这是典型的过拟合学习曲线,因为其训练集的正确率一直很高,说明模型很好的学习到了数据集中的内容,但是其测试集的正确率一直跑不高,这就是典型的过拟合。
当然,上面的图都是理想情况,大家还需要具体情况具体分析,例如下面这张图
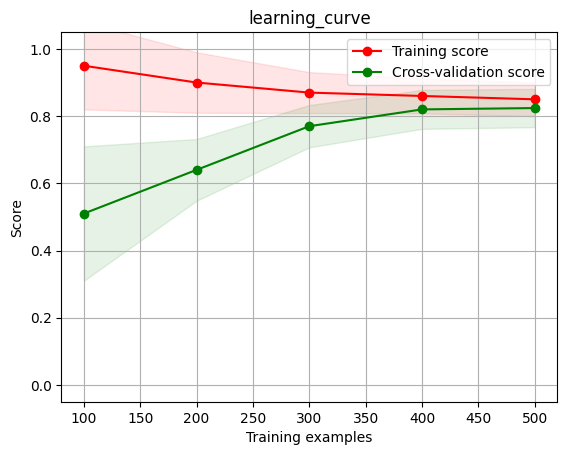
看起来是欠拟合图像的样子,但是我们发现其最后收敛的正确率其实也不会特别低,这时候我们就要结合具体情况分析,比如我们的需求并不需要90+的正确率,那这个模型我们是可以接受的,再比如这是一个未经调参的集成学习模型,那通过这个学习曲线我们就可以知道我们需要将模型调复杂一点,这样其正确率可能会继续上升,到90甚至更高,这也是有可能的。




