前言
目前所流行的机器学习与深度学习算法,可以被总结为是一类利用数据驱动 的算法。而回归算法可以说是最早的数据驱动的算法,其简洁有效,且最基础的线性回归算法具有及其稀有的显示解。虽然其模型复杂度不高,且对于数据有一定要求,但是对于满足要求的数据,线性回归具有如今一众大模型都达不到的效果(毕竟线性回归模型小,还有显示解),因此至今在工业界也被广泛使用,有一种大巧不工的美感。而其后来者,如在机器学习时代大名鼎鼎的SVM,其也是基于线性回归的,而现在所流行的深度学习,其中最重要的算法神经网络,其本质也是多个线性模型,而反过来,线性回归其实就是一个单层的神经网络。
综上,线性回归在机器学习领域具有举足轻重的地位。但是对于回归相关的内容,由于其始于统计,而现于机器学习学习中大放异彩,因此侧重统计与侧重机器学习的讲法会完全不同。权衡再三,本文将侧重机器学习讲解回归相关的内容,而侧重统计的内容待我另起炉灶。
注:本文会涉及到梯度下降算法,对此不了解的读者可以移步本站的梯度下降博客
多元线性回归
在高中数学课本中,我们就接触过最简单的一元线性回归,也就是y = a x + b y = ax + b y = a x + b
而在实际问题中,往往并不止一个自变量x x x
y = w 0 + w 1 x 1 + ⋯ + w p x p y = w_0 + w_1 x_1 + \cdots + w_p x_p
y = w 0 + w 1 x 1 + ⋯ + w p x p
其中p p p
损失函数
确定了模型,接下来就是如何计算出模型的参数 ,对于数据驱动的回归模型,那自然是借助于样本数据。这里我们记第i i i ( x i 1 , x i 2 , ⋯ , x i p , y i ) (x_{i1}, x_{i2}, \cdots, x_{ip}, y_i) ( x i 1 , x i 2 , ⋯ , x i p , y i ) n n n
确定好符号后我们继续,我们的目的肯定是希望最终的模型越准确越好,那至少,这个模型在我们现有的样本数据上的表现要好吧。那现在,我们随便取一个数据样本( x i 1 , x i 2 , ⋯ , x i p , y i ) (x_{i1}, x_{i2}, \cdots, x_{ip}, y_i) ( x i 1 , x i 2 , ⋯ , x i p , y i ) ( w 0 , w 1 , w 2 , ⋯ , w p ) (w_0, w_1, w_2, \cdots, w_p) ( w 0 , w 1 , w 2 , ⋯ , w p ) y i y_i y i y ^ = w 0 + w 1 x i 1 + ⋯ + w p x i p \hat{y} = w_0 + w_1 x_{i1} + \cdots + w_p x_{ip} y ^ = w 0 + w 1 x i 1 + ⋯ + w p x i p ( y i − y ^ ) 2 (y_i - \hat{y})^2 ( y i − y ^ ) 2
好,现在停下来看看我们本来在做什么,我们想要计算模型的参数,那么什么样的参数是好的呢,使( y i − y ^ ) 2 (y_i - \hat{y})^2 ( y i − y ^ ) 2 ( y i − y ^ ) 2 (y_i - \hat{y})^2 ( y i − y ^ ) 2 ( y i − y ^ ) 2 (y_i - \hat{y})^2 ( y i − y ^ ) 2 ( y i − y ^ ) 2 (y_i - \hat{y})^2 ( y i − y ^ ) 2
L ( w ) = ∑ i = 1 n ( y i − y ^ ) 2 = ∑ i = 1 n ( y i − w 0 − w 1 x i 1 − ⋯ − w p x i p ) 2 = ∣ ∣ y − X w ∣ ∣ 2 L(\boldsymbol{w}) = \sum_{i=1}^{n} (y_i - \hat{y})^2 = \sum_{i=1}^{n} (y_i - w_0 - w_1 x_{i1} - \cdots - w_p x_{ip})^2 = ||\boldsymbol{y} - X\boldsymbol{w}||^2
L ( w ) = i = 1 ∑ n ( y i − y ^ ) 2 = i = 1 ∑ n ( y i − w 0 − w 1 x i 1 − ⋯ − w p x i p ) 2 = ∣∣ y − X w ∣ ∣ 2
其中w = ( w 0 , w 1 , w 2 , ⋯ , w p ) T \boldsymbol{w} = (w_0, w_1, w_2, \cdots, w_p)^T w = ( w 0 , w 1 , w 2 , ⋯ , w p ) T w 0 , w 1 , w 2 , ⋯ , w p w_0, w_1, w_2, \cdots, w_p w 0 , w 1 , w 2 , ⋯ , w p y \boldsymbol{y} y X X X
y = ( y 1 , y 2 , ⋯ , y n ) T X = [ 1 x 11 x 12 … x 1 p 1 x 21 x 22 … x 2 p 1 x 31 x 32 … x 3 p ⋯ 1 x n 1 x n 2 … x n p ] \boldsymbol{y} = (y_1, y_2, \cdots, y_n)^T \\
X = \begin{bmatrix}
1&x_{11}&x_{12}&\ldots&x_{1p}\\
1&x_{21}&x_{22}&\ldots&x_{2p}\\
1&x_{31}&x_{32}&\ldots&x_{3p}\\
&&\cdots\\
1&x_{n1}&x_{n2}&\ldots&x_{np}
\end{bmatrix}
y = ( y 1 , y 2 , ⋯ , y n ) T X = 1 1 1 1 x 11 x 21 x 31 x n 1 x 12 x 22 x 32 ⋯ x n 2 … … … … x 1 p x 2 p x 3 p x n p
其实就是样本数据的自变量与因变量,而矩阵X X X 1 1 1 w 0 w_0 w 0
注1:这里的矩阵写法只是为了简洁 ,本质上与前面的式子是一样的,对矩阵不熟悉的同学看不懂也没有关系,看懂前面的式子也是一样的。
注2:这里的∣ ∣ ∣ ∣ ||\ \ || ∣∣ ∣∣ L 2 L_2 L 2 ∣ ∣ |\ \ | ∣ ∣ ∣ ∣ |\ \ | ∣ ∣ ∣ ∣ ∣ ∣ ||\ \ || ∣∣ ∣∣
还有一个小点,在有些地方,L 2 L_2 L 2 ∣ ∣ ∣ ∣ 2 ||\ \ ||_2 ∣∣ ∣ ∣ 2 2 2 2 L 2 L_2 L 2 2 2 2 ∣ ∣ ∣ ∣ 1 ||\ \ ||_1 ∣∣ ∣ ∣ 1 L 1 L_1 L 1 L 2 L_2 L 2 L p L_p L p
最后还有范数的计算,对于向量a = ( a 1 , a 2 , ⋯ , a p ) \boldsymbol{a} = (a_1, a_2, \cdots, a_p) a = ( a 1 , a 2 , ⋯ , a p )
到这里,计算模型的参数的问题已经被我们转化 为了求解函数L ( w ) L(\boldsymbol{w}) L ( w ) 最小值问题 。也就是说,多元线性回归模型的计算参数计算公式为
w ^ = m i n w L ( w ) = m i n w ∣ ∣ y − X w ∣ ∣ 2 \hat{\boldsymbol{w}} = \mathop{min} \limits_{\boldsymbol{w}} L(\boldsymbol{w}) = \mathop{min} \limits_{\boldsymbol{w}} ||\boldsymbol{y} - X\boldsymbol{w}||^2
w ^ = w min L ( w ) = w min ∣∣ y − X w ∣ ∣ 2
如L ( w ) L(\boldsymbol{w}) L ( w ) 损失函数,这里我们采用的该损失函数被称为平方误差损失函数(MSE)。
解析解与数值解
解析解
最后,就剩下一个问题,如何求解损失函数。这里我们需要先介绍一下解析解与数值解。解析解是指用解析表达式 来表达的解,例如我们初中就接触过的二次函数y = a x 2 + b x + c y = ax^2 + bx +c y = a x 2 + b x + c 0 0 0 x = − b 2 a x = - \frac{b}{2a} x = − 2 a b
∂ L ∂ w = 2 X T ( X w − y ) \frac{ \partial L }{ \partial \boldsymbol{w} } = 2 X^{T} (X \boldsymbol{w} - y)
∂ w ∂ L = 2 X T ( X w − y )
令损失函数的导数等于0 0 0
2 X T ( X w − y ) = 0 ⇒ w ^ = ( X T X ) − 1 X T y 2 X^{T} (X \boldsymbol{w} - y) = 0
\quad \Rightarrow \quad
\hat{\boldsymbol{w}}= (X^T X)^{-1} X^T \boldsymbol{y}
2 X T ( X w − y ) = 0 ⇒ w ^ = ( X T X ) − 1 X T y
数值解
而什么是数值解呢,就是只关注x x x 梯度下降,这是机器学习与深度学习中最常用的优化算法,例如函数y = x 2 y = x^2 y = x 2 x = 0 x=0 x = 0 x = 0.0001 x = 0.0001 x = 0.0001 x = − 0.0002 x = -0.0002 x = − 0.0002
对比与区别
好,现在让我们来对比一下解析解与数值解。毫无疑问解析解是优秀的,因为解析解相当于一个通解 ,只要损失函数是确定的,最优解也就出来了,而使用计算机进行计算时这会节省大量的计算时间,在以大量计算著称的机器学习领域这无疑是巨大的优势。而相比之下,数值解相当于是一个特解 ,具体问题具体分析,每拿到一个新的数据都要算出具体的损失函数,然后用优化算法搜索最小值,这非常的浪费算力。
现在让我们来思考一下,既然解析解全都是优点,那为什么还要有数值解呢。首先,在纷繁复杂的损失函数中,解析解是非常稀有的 ,我们上面刚刚讲过用( y i − y ^ ) 2 (y_i - \hat{y})^2 ( y i − y ^ ) 2 ∣ y i − y ^ ∣ |y_i - \hat{y}| ∣ y i − y ^ ∣
L ( w ) = ∑ i = 1 n ∣ y i − y ^ ∣ = ∑ i = 1 n ∣ y i − w 0 − w 1 x i 1 − ⋯ − w p x i p ∣ = ∣ ∣ y − X w ∣ ∣ 1 L(\boldsymbol{w}) = \sum_{i=1}^{n} |y_i - \hat{y}| = \sum_{i=1}^{n} |y_i - w_0 - w_1 x_{i1} - \cdots - w_p x_{ip}| = ||\boldsymbol{y} - X\boldsymbol{w}||_1
L ( w ) = i = 1 ∑ n ∣ y i − y ^ ∣ = i = 1 ∑ n ∣ y i − w 0 − w 1 x i 1 − ⋯ − w p x i p ∣ = ∣∣ y − X w ∣ ∣ 1
这个损失函数马上就没有解析解了,这也就是为什么上面我们要用平方而不是绝对值。至少以人类现在的数学发展水平来说,很多函数都是没有解析解的。
其次,让我们观察一下上面给出的多元线性回归的解析解,不难看到其需要计算逆矩阵,相信学习过线性代数的读者大多跟笔者一样觉得计算逆矩阵是一件非常麻烦的事情,这对于计算机也是一样的 。而在深度学习领域,由于模型的层层堆叠,即便存在解析解,多个庞大矩阵的逆矩阵计算也会将计算量拉到一个不可接受的程度。
现在我们来整理一下,解析解是最优雅的解决方案,但是其可遇不可求,并且在深度学习领域,随着模型的层层堆叠,其计算量可能会达到一个不可接受的程度。而数值解虽然有很多缺点,但是其不挑损失函数,且计算量相对可控,因此,在多个领域中,数值解都是非常泛用的存在。最后,之所以要在这里提到解析解与数值解,是因为我们上面所使用的损失函数是少数拥有解析解的函数,多数教材也是在线性回归处提到解析解,毕竟后续算法基本都是数值解。
岭回归与Lasso回归
损失函数
岭回归与Lasso回归是对多元线性回归的一种改进,其在损失函数 中加入了正则化项 ,以此解决了多元线性回归可能存在的问题。所谓的正则化项其实就是参数w \boldsymbol{w} w L 1 L_1 L 1 w \boldsymbol{w} w L 1 L_1 L 1 ∣ ∣ w ∣ ∣ 1 ||\boldsymbol{w}||_1 ∣∣ w ∣ ∣ 1 L 2 L_2 L 2 w \boldsymbol{w} w L 2 L_2 L 2 ∣ ∣ w ∣ ∣ 2 2 ||\boldsymbol{w}||_2^2 ∣∣ w ∣ ∣ 2 2
L ( w ) = ∣ ∣ y − X w ∣ ∣ 2 2 + α ∣ ∣ w ∣ ∣ 2 2 L(\boldsymbol{w}) = ||\boldsymbol{y} - X\boldsymbol{w}||_2^2 + \alpha ||\boldsymbol{w}||_2^2
L ( w ) = ∣∣ y − X w ∣ ∣ 2 2 + α ∣∣ w ∣ ∣ 2 2
Lasso回归的损失函数为
L ( w ) = ∣ ∣ y − X w ∣ ∣ 2 2 + α ∣ ∣ w ∣ ∣ 1 L(\boldsymbol{w}) = ||\boldsymbol{y} - X\boldsymbol{w}||_2^2 + \alpha ||\boldsymbol{w}||_1
L ( w ) = ∣∣ y − X w ∣ ∣ 2 2 + α ∣∣ w ∣ ∣ 1
其中的α \alpha α 正则化系数 ,我们后面再讲。
正则化项
我们先来解决一个问题,就是为什么要加入正则化项。如果是在统计学教材中,则一定会讲到解决多重共线性问题,这也是该算法的本意,且有严格的数学推导。不过既然是侧重与机器学习的文章,这里我就用机器学习的角度来解释一下正则项。
在机器学习中,正则项常常被用于控制模型复杂度,防止模型过拟合 。简单来说,在机器学习中,模型的复杂度过大或者过小都不是我们所期望的,复杂度过大会导致过拟合,复杂度过小会导致欠拟合,而我们需要在这之间找到一个平衡点。而解决欠拟合的手段非常的单一,就是用更复杂的模型,上更多的参数。所以,如今一般的策略是先做到过拟合,再通过限制模型的手段将其复杂度往下降,例如决策树的剪枝就是一种防止过拟合的手段 。
现在让我们来看看回归模型,我们会发现一个问题,回归模型的参数数量是固定的,那我们该如何降低复杂度呢。还有一种手段,就是限制参数的取值范围,这也可以达到降低复杂度的作用。而此时我们会发现,参数w \boldsymbol{w} w L 2 L_2 L 2
∣ ∣ w ∣ ∣ 2 = w 1 2 + w 2 2 + ⋯ + w p 2 || \boldsymbol{w} ||_2= \sqrt{w_1^2 + w_2^2 + \cdots + w_p^2}
∣∣ w ∣ ∣ 2 = w 1 2 + w 2 2 + ⋯ + w p 2
可以直观的看出,各参数的数值部分(也就是不管正负)越大,范数越大。而现在损失函数中加入了范数,我们希望损失函数尽可能的小,这就要求在兼顾模型的拟合效果(也就是将真实值与预测值之间的差距缩小)的同时,还需要控制模型的复杂度(就是范数不能太大)。这就需要在两者之间找到一个平衡点。而上述损失函数中的正则化系数 α \alpha α α \alpha α
注:在统计视角的回归分析教材中,对于参数α \alpha α α \alpha α 对参数α \alpha α 。
解析解
最后,上述两个损失函数其实也是存在解析解的,这里我们直接给出,岭回归的解析解为
w ^ = ( X T X + α I ) − 1 X T y \hat{\boldsymbol{w}} = (X^T X + \alpha I)^{-1} X^T \boldsymbol{y}
w ^ = ( X T X + α I ) − 1 X T y
Lasso回归的解析解为
w ^ = ( X T X ) − 1 ( X T y − α 2 I ) \hat{\boldsymbol{w}} = (X^T X)^{-1} (X^T \boldsymbol{y} - \frac{\alpha}{2} I)
w ^ = ( X T X ) − 1 ( X T y − 2 α I )
logistic回归与softmax回归
logistic回归与softmax回归是使用多元线性回归模型进行分类算法,logistic回归用于二分类问题,而softmax回归用于多分类问题。
logistic回归
首先我们来看二分类问题,也就是logistic回归。在多元线性回归模型的基础上,要将其用于分类,我们需要解决两个问题 。第一,回归模型的输出是一个连续值,而分类问题的输出是一个离散值,如何让回归模型输出离散值 。第二,既然要解决的问题变成了分类问题,那原来的损失函数也就用不了了,应该使用何种损失函数 。
sigmoid函数
那让我们先来解决第一个问题,如何让回归模型输出离散值。那我们先来看看,我们希望的输出值是什么样的,这里我们在处理的是二分类问题,用0 , 1 0,1 0 , 1 0 0 0 1 1 1 ( 0 , 1 ) (0,1) ( 0 , 1 ) 1 1 1
回到让回归模型输出离散值这个问题,我们给出的答案是套娃,在原线性模型上再套一层函数 。我们看,多元线性回归的模型是
f ( x ) = w 0 + w 1 x 1 + ⋯ + w p x p = w T x ~ f(\boldsymbol{x}) = w_0 + w_1 x_1 + \cdots + w_p x_p = \boldsymbol{w}^{T} \widetilde{\boldsymbol{x}}
f ( x ) = w 0 + w 1 x 1 + ⋯ + w p x p = w T x
其中w = ( w 0 , w 1 , w 2 , ⋯ , w p ) T \boldsymbol{w} = (w_0, w_1, w_2, \cdots, w_p)^T w = ( w 0 , w 1 , w 2 , ⋯ , w p ) T x = ( x 1 , x 2 , ⋯ , x p ) T \boldsymbol{x} = (x_1, x_2, \cdots, x_p)^T x = ( x 1 , x 2 , ⋯ , x p ) T x ~ = ( 1 , x 1 , x 2 , ⋯ , x p ) T \widetilde{\boldsymbol{x}} = (1, x_1, x_2, \cdots, x_p)^T x = ( 1 , x 1 , x 2 , ⋯ , x p ) T
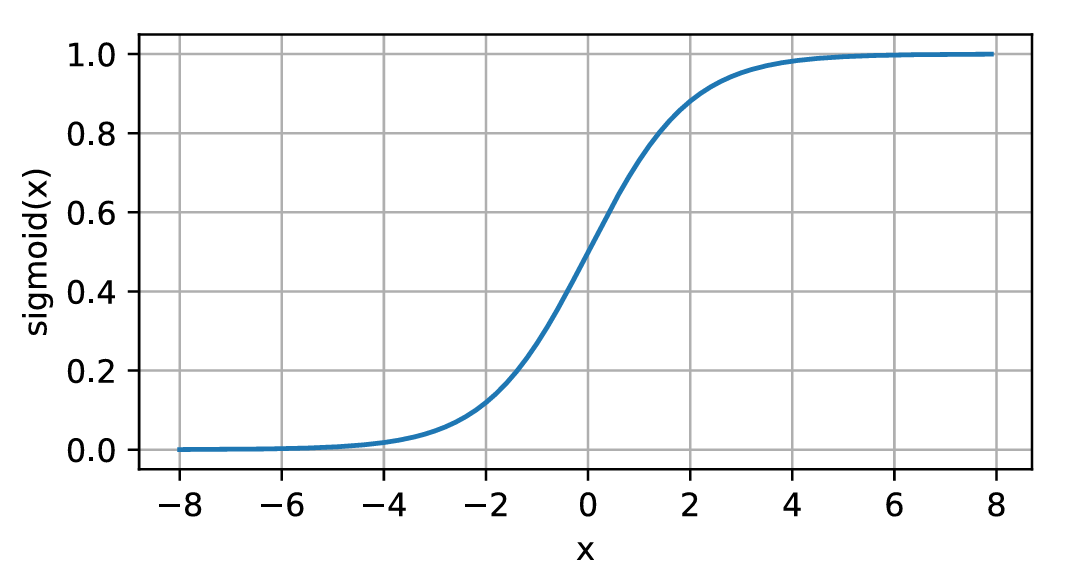
我们需要认识到,数学上的函数与代码中的函数一样,都是有固定形状的输入与输出的。例如这个函数,其输入为p p p ( − ∞ , + ∞ ) (-\infty,+\infty) ( − ∞ , + ∞ ) ( 0 , 1 ) (0,1) ( 0 , 1 ) ( − ∞ , + ∞ ) (-\infty,+\infty) ( − ∞ , + ∞ ) ( 0 , 1 ) (0,1) ( 0 , 1 ) sigmoid函数,函数表达式为
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}}
σ ( x ) = 1 + e − x 1
函数图像如下
可以看到,这个函数完美的符合我们的要求。那么,我们的logistic回归模型就可以写为
y ^ = F ( x ) = σ ( f ( x ) ) = 1 1 + e − f ( x ) = 1 1 + e − w T x ~ \hat{y} = F(\boldsymbol{x}) = \sigma(f(\boldsymbol{x})) = \frac{1}{1 + e^{-f(\boldsymbol{x})}} = \frac{1}{1 + e^{-\boldsymbol{w}^{T} \widetilde{\boldsymbol{x}}}}
y ^ = F ( x ) = σ ( f ( x )) = 1 + e − f ( x ) 1 = 1 + e − w T x 1
那现在,我们来看看输出概率而非直接输出类别有何好处。其主要的好处就是使得我们的模型更精细,就比如说,在模型的实际使用中,有两个样本的logistic回归模型输出分别为0.7和0.8,那我们可以判断出输出为0.8的样本被归于类别1的概率是更大的,而如果直接输出类别,那这两个样本在我们看来就是一样的。并且,直接输出概率还可以自由的设定分类阈值,这也能更加满足实际应用中的需求,例如像银行贷款这种需要高置信度的场景,我们可能需要设定其概率达到0.7,0.8甚至更高,我们才会允许其进行贷款,或者说这个周期内概率最高的100人可以获得贷款等。在这种场景下,输出概率值会更加灵活。
注:虽然我们前面一直说概率值,但是严格来说logistic回归的输出并不是概率值,只是其数学性质与概率值基本相同,并且称其为概率值会更好理解,因此一般教材中也会直接称其为概率值,对此不必太钻牛角尖。
对数似然损失函数
然后我们来解决第二个问题,用什么损失函数。那我们会想,用原来的损失函数不行吗,仔细想想也不是说用不了啊。没错,确实是可以用,但是前人的研究告诉我们效果并不好,不过好用的损失函数前人也帮我们研究好了。
首先,我们前面说过logistic回归的输出F ( x ) F(\boldsymbol{x}) F ( x ) 1 − F ( x ) 1 - F(\boldsymbol{x}) 1 − F ( x )
p ( x ) = [ F ( x ) ] y [ 1 − F ( x ) ] 1 − y p(\boldsymbol{x}) = [F(\boldsymbol{x})]^{y} [1 - F(\boldsymbol{x})]^{1 - y}
p ( x ) = [ F ( x ) ] y [ 1 − F ( x ) ] 1 − y
我们看,当样本的真实值为类别1,也就是y = 1 y = 1 y = 1 p ( x ) = F ( x ) p(\boldsymbol{x}) = F(\boldsymbol{x}) p ( x ) = F ( x ) y = 0 y = 0 y = 0 p ( x ) = 1 − F ( x ) p(\boldsymbol{x}) = 1 - F(\boldsymbol{x}) p ( x ) = 1 − F ( x ) 函数p ( x ) p(\boldsymbol{x}) p ( x ) 。
将所有样本的p ( x ) p(\boldsymbol{x}) p ( x )
∏ i = 1 n p ( x i ) = ∏ i = 1 n [ F ( x i ) ] y i [ 1 − F ( x i ) ] 1 − y i \prod_{i=1}^n p(\boldsymbol{x_i}) = \prod_{i=1}^n [F(\boldsymbol{x_i})]^{y_i} [1 - F(\boldsymbol{x_i})]^{1 - y_i}
i = 1 ∏ n p ( x i ) = i = 1 ∏ n [ F ( x i ) ] y i [ 1 − F ( x i ) ] 1 − y i
其中x i = ( x i 1 , x i 2 , ⋯ , x i p ) T \boldsymbol{x_i} = (x_{i1}, x_{i2}, \cdots, x_{ip})^T x i = ( x i 1 , x i 2 , ⋯ , x i p ) T 代表了将所有样本预测正确的概率 ,我们希望将其最大化,也就是说,这就是我们的损失函数了。为了方便运算,一般对其取对数再取负,那么我们最终的损失函数为
L ( w ) = − l n ( ∏ i = 1 n p ( x i ) ) = − l n ( ∏ i = 1 n [ F ( x i ) ] y i [ 1 − F ( x i ) ] 1 − y i ) = − ∑ i = 1 n y i l n [ F ( x i ) ] + ( 1 − y i ) l n [ 1 − F ( x i ) ] = − ∑ i = 1 n y i l n [ 1 1 + e − w T x ~ i ] + ( 1 − y i ) l n [ e − w T x ~ i 1 + e − w T x ~ i ] L(\boldsymbol{w}) = - \mathrm{ln} \left( \prod_{i=1}^n p(\boldsymbol{x_i}) \right) =
- \mathrm{ln} \left( \prod_{i=1}^n [F(\boldsymbol{x_i})]^{y_i} [1 - F(\boldsymbol{x_i})]^{1 - y_i} \right) = \\
- \sum_{i=1}^{n} y_i \mathrm{ln} \left[ F(\boldsymbol{x_i}) \right] + (1 - y_i)\mathrm{ln} \left[ 1 - F(\boldsymbol{x_i}) \right] =
- \sum_{i=1}^{n} y_i \mathrm{ln} \left[ \frac{1}{1 + e^{-\boldsymbol{w}^{T} \widetilde{\boldsymbol{x}}_i }} \right] + (1 - y_i)\mathrm{ln} \left[ \frac{e^{-\boldsymbol{w}^{T} \widetilde{\boldsymbol{x}}_i}}{1 + e^{-\boldsymbol{w}^{T} \widetilde{\boldsymbol{x}}_i}} \right]
L ( w ) = − ln ( i = 1 ∏ n p ( x i ) ) = − ln ( i = 1 ∏ n [ F ( x i ) ] y i [ 1 − F ( x i ) ] 1 − y i ) = − i = 1 ∑ n y i ln [ F ( x i ) ] + ( 1 − y i ) ln [ 1 − F ( x i ) ] = − i = 1 ∑ n y i ln [ 1 + e − w T x i 1 ] + ( 1 − y i ) ln [ 1 + e − w T x i e − w T x i ]
也可以写作矩阵形式
L ( w ) = − ∑ i = 1 n y i l n y ^ i + ( 1 − y i ) l n ( 1 − y ^ i ) = − y T ln y ^ − ( 1 − y ) T ln ( 1 − y ^ ) L(\boldsymbol{w}) =
- \sum_{i=1}^{n} y_i \mathrm{ln} \hat{y}_i + (1 - y_i)\mathrm{ln} (1 - \hat{y}_i)
= - \boldsymbol{y}^T \ln \hat{\boldsymbol{y}} - (\boldsymbol{1} - \boldsymbol{y})^T \ln (\boldsymbol{1} - \hat{\boldsymbol{y}})
L ( w ) = − i = 1 ∑ n y i ln y ^ i + ( 1 − y i ) ln ( 1 − y ^ i ) = − y T ln y ^ − ( 1 − y ) T ln ( 1 − y ^ )
该损失函数被称为对数似然损失函数。
注:这里取对数是为了方便计算,而取负则是为了将最大化转换为最小化,因为在机器学习中损失函数默认都是最小化 ,如果你的损失函数要求最大化,那就加一个负号就可以了。
数值解与正则化
最后我们来做一些收尾工作,首先是损失函数的求解 ,在logistic回归中是没有解析解的,因此损失函数的求解依靠优化算法来实现,例如使用鼎鼎大名的梯度下降,这里我们不对优化算法做过多的介绍。
最后是正则化,logistic回归也可以通过正则化项来防止过拟合,这与上文的岭回归与Lasso回归是一样的,即
L ( w ) = − y T ln y ^ − ( 1 − y ) T ln ( 1 − y ^ ) + α ∣ ∣ w ∣ ∣ 2 2 L ( w ) = − y T ln y ^ − ( 1 − y ) T ln ( 1 − y ^ ) + α ∣ ∣ w ∣ ∣ 1 L(\boldsymbol{w}) = - \boldsymbol{y}^T \ln \hat{\boldsymbol{y}} - (\boldsymbol{1} - \boldsymbol{y})^T \ln (\boldsymbol{1} - \hat{\boldsymbol{y}}) + \alpha ||\boldsymbol{w}||_2^2 \\
L(\boldsymbol{w}) = - \boldsymbol{y}^T \ln \hat{\boldsymbol{y}} - (\boldsymbol{1} - \boldsymbol{y})^T \ln (\boldsymbol{1} - \hat{\boldsymbol{y}}) + \alpha ||\boldsymbol{w}||_1
L ( w ) = − y T ln y ^ − ( 1 − y ) T ln ( 1 − y ^ ) + α ∣∣ w ∣ ∣ 2 2 L ( w ) = − y T ln y ^ − ( 1 − y ) T ln ( 1 − y ^ ) + α ∣∣ w ∣ ∣ 1
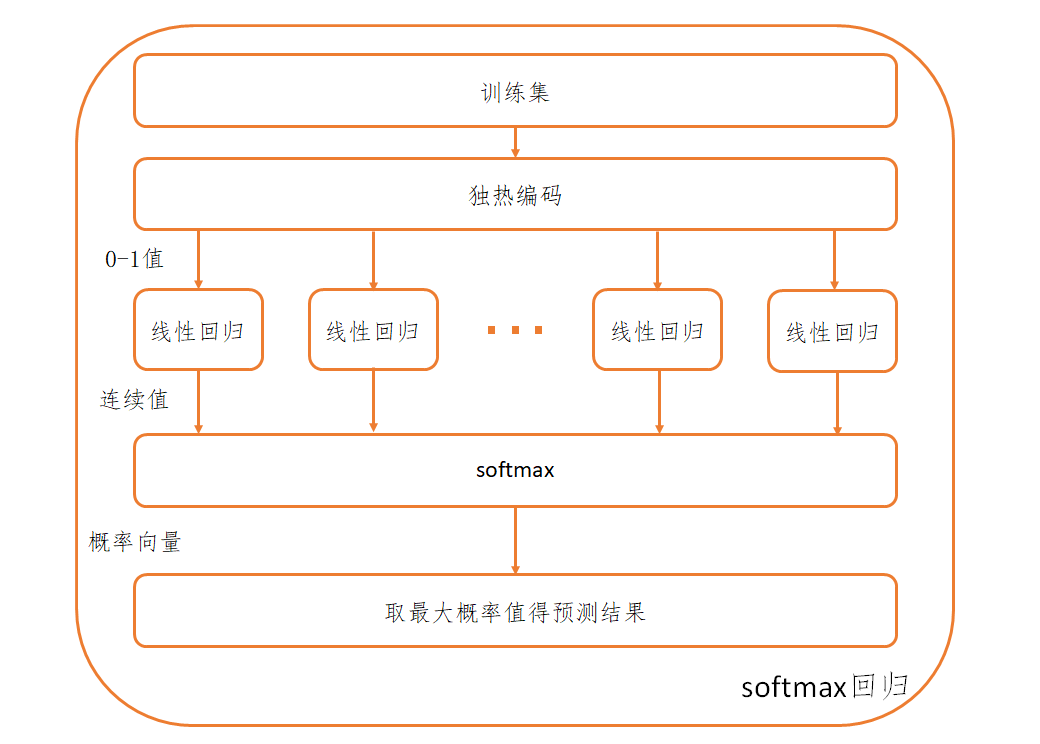
softmax回归
然后我们来看多分类问题,处理多分类问题的方法有很多,这里我们会简单介绍一下常用的方法,但是主要介绍softmax回归。这是因为,多元线性可以看作一个处理回归问题的单层神经网络,而softmax回归则可以看作一个处理分类问题的单层神经网络,可以说softmax回归是深度学习的重要基础。
多分类学习策略
经过logistic回归的学习,我们可以发现logistic回归只能处理二分类问题,那么遇到多分类问题应该如何处理呢。答案就是将其处理为多个二分类问题,而其处理方式就被称为多分类学习策略。
注1:有同学可能会想,为什么不能把多个分类进行编码,比如把三个类编码为1,2,3,然后训练一个输出1,2,3其中之一的模型呢。这是因为,将多个分类进行编码一定会出现类别之间关系的紊乱。就比如说三个类编码为1,2,3,本来这三个类的地位应该是平起平坐的,但是这么一编码,就凭空给他们创造了一个数学上的关系,比如第二个类比第一个类大1,第三个类比第一个类大2。我们当然可以看得出来这个关系是错误的,但是模型没有那么聪明,模型是分辨不出来的,这必然会导致最终模型的效果不佳。
注2:对比决策树算法 我们就会发现,决策树就没有这样的问题,这是因为决策树不需要把类别的编码用于计算 ,而线性回归是需要的(损失函数)。
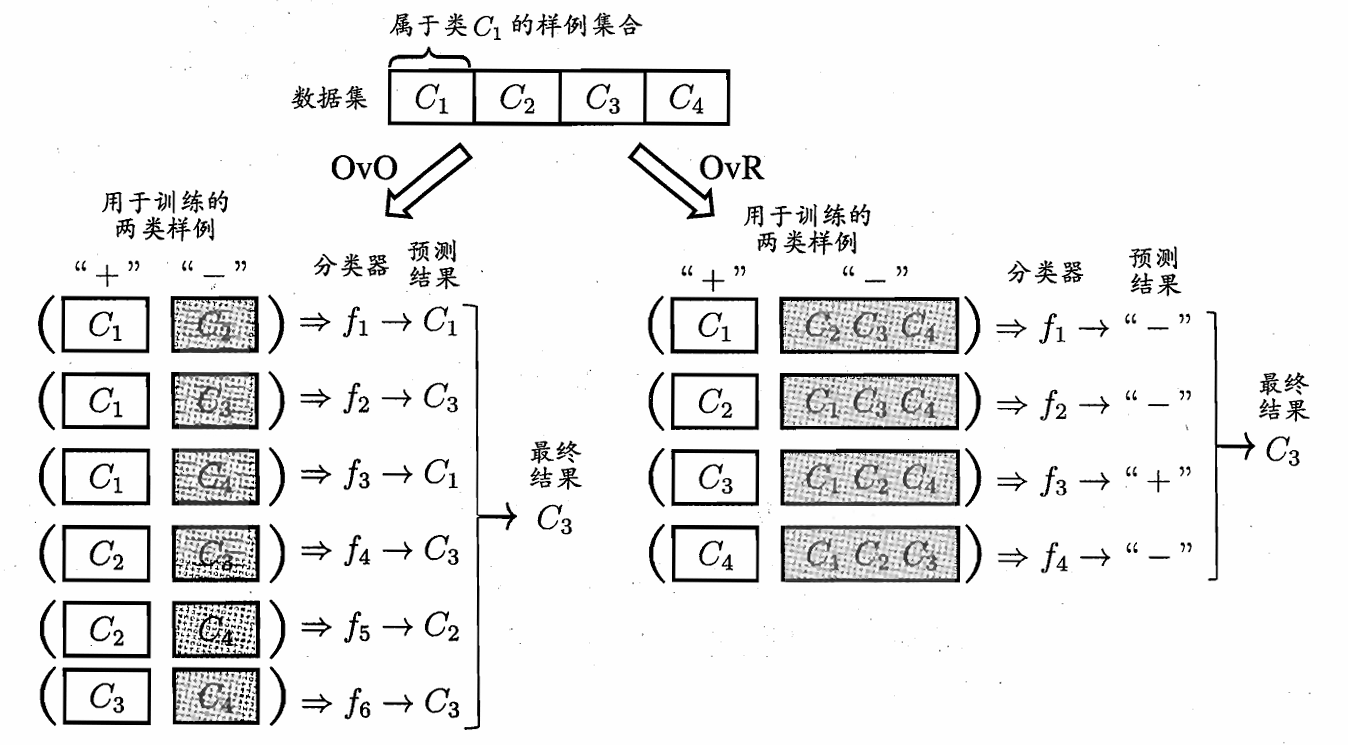
OvO策略
OvO(One vs One)策略是指,将所有类别(共n n n n ( n − 1 ) / 2 n(n-1)/2 n ( n − 1 ) /2 ( 1 , 2 ) , ( 1 , 3 ) , ( 2 , 3 ) (1,2),(1,3),(2,3) ( 1 , 2 ) , ( 1 , 3 ) , ( 2 , 3 ) ( 1 , 2 ) (1,2) ( 1 , 2 )
OvR策略
OvR(One vs Rest)策略是指,将所有类别(共n n n n n n ( 1 , 2 ) (1,2) ( 1 , 2 ) 这个样本属于第一类还是不属于第一类 ,或者说这个样本属于第一类还是属于其他类。还是拿三个类别1,2,3举例,三个类别分别做一次老大,比如说现在第一类做老大,跟OvO不一样,这里我们不用筛数据,而是说,现在的老大是第一类,我们给第一类编号为1(正类),剩下的第二类第三类统统编号为0(反类),然后做logistic回归。以此类推得到三个二分类器,经过上文的学习我们知道logistic回归会输出样本属于正类的概率,现在拿到一个新样本,第一个分类器输出0.9,第二个分类器输出0.3,第三个分类器输出0.4,第一个分类器的输出最高,也就是置信度最高,故这个样本属于第一类。OvR策略就是这样一个流程。下面我们用一个图再对比一下两种策略
注:从上述讲解中,我们可以发现,OvO策略的复杂度是比OvR策略要高的,但是在模型表现上,大多数情况下两者是差不多的,因此目前OvR策略可以说是主流。
MvM策略
当然在上述两种策略之上还有更为高级的MvM(Many vs Many)策略,就是将部分类别作为正类,剩余类别作为反类。可以看出OvO与OvR都是MvM的一种特殊情况。由于MvM策略较为复杂,因为如何进行划分是个大问题,目前也有多种MvM技术,因此这里只做简介,让大家知道有MvM策略这么个东西,而不去深究。
One-Hot编码
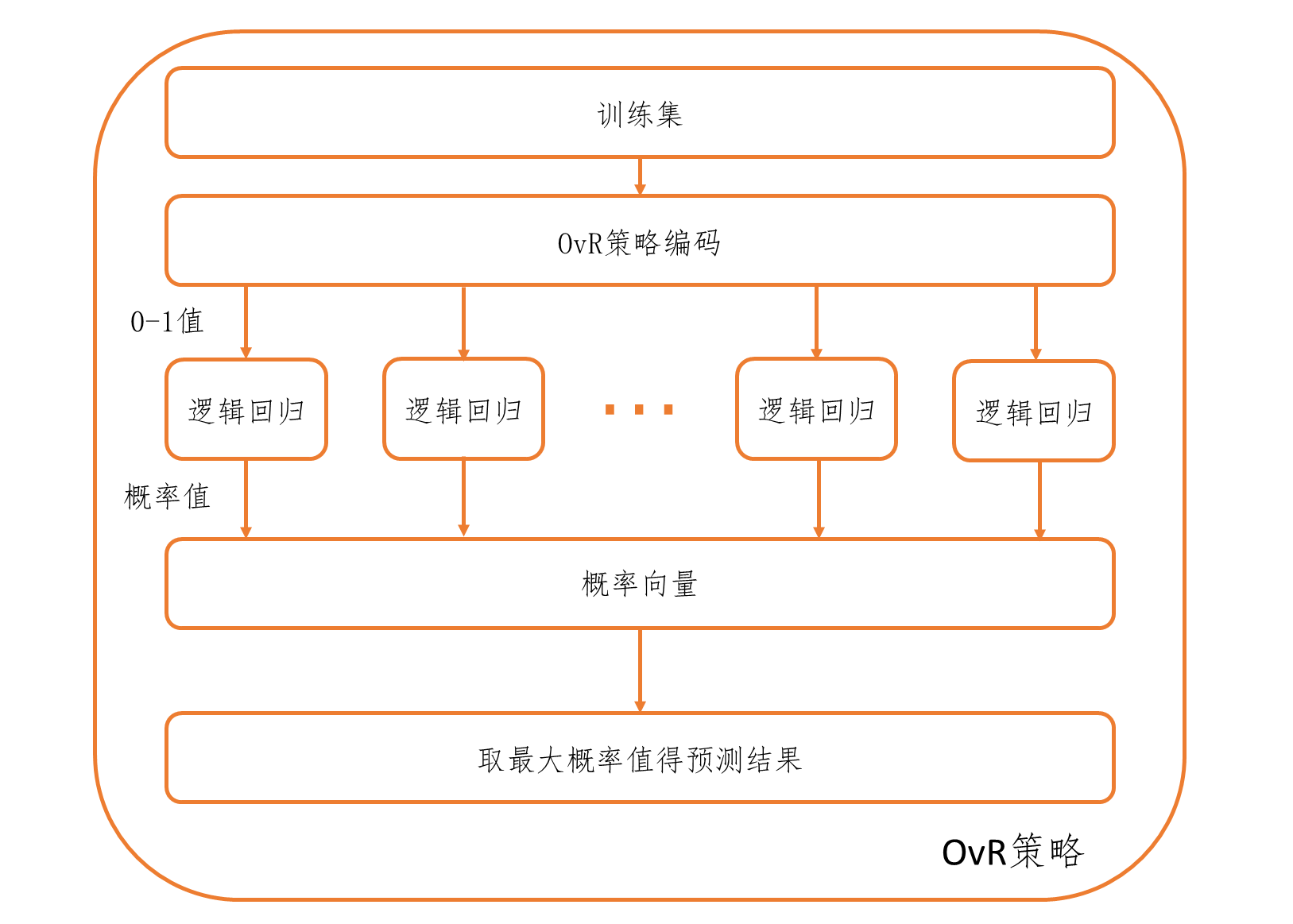
了解完多分类学习策略之后,我们正式开始讲softmax回归,这里可以先告诉大家,softmax回归可以被归类为使用OvR策略。首先,上文我们提到过对于多分类问题编码是一个大问题,不能用1,2,3这种编码。那既然一个数解决不了,那我们就用多个数不就好了,这也就是本节的主角,One-Hot编码(独热编码)。One-Hot编码使用一个m × 1 m \times 1 m × 1 m m m i i i i i i 1 1 1 0 0 0 ( 1 , 0 , 0 ) T (1, 0, 0)^T ( 1 , 0 , 0 ) T ( 0 , 1 , 0 ) T (0, 1, 0)^T ( 0 , 1 , 0 ) T ( 0 , 0 , 1 ) T (0, 0, 1)^T ( 0 , 0 , 1 ) T 1 1 1 One-Hot编码(独热编码)。
在改变编码方式之后,则会引出下一个问题,之前的模型输出是一个数,现在输出要改为一个向量,那模型结构连带着也会发生改变 。我们先不管sigmoid函数,就看内层的模型
y = f ( x ) = w 0 + w 1 x 1 + ⋯ + w p x p = w T x ~ y = f(\boldsymbol{x}) = w_0 + w_1 x_1 + \cdots + w_p x_p = \boldsymbol{w}^{T} \widetilde{\boldsymbol{x}}
y = f ( x ) = w 0 + w 1 x 1 + ⋯ + w p x p = w T x
其中w = ( w 0 , w 1 , w 2 , ⋯ , w p ) T \boldsymbol{w} = (w_0, w_1, w_2, \cdots, w_p)^T w = ( w 0 , w 1 , w 2 , ⋯ , w p ) T x = ( x 1 , x 2 , ⋯ , x p ) T \boldsymbol{x} = (x_1, x_2, \cdots, x_p)^T x = ( x 1 , x 2 , ⋯ , x p ) T x ~ = ( 1 , x 1 , x 2 , ⋯ , x p ) T \widetilde{\boldsymbol{x}} = (1, x_1, x_2, \cdots, x_p)^T x = ( 1 , x 1 , x 2 , ⋯ , x p ) T
现在将改为
y = f ( x ) = W T x ~ \boldsymbol{y} = f(\boldsymbol{x}) = W^{T} \widetilde{\boldsymbol{x}}
y = f ( x ) = W T x
其中y = ( y 1 , y 2 , ⋯ , y m ) T \boldsymbol{y} = (y_1, y_2, \cdots, y_m)^T y = ( y 1 , y 2 , ⋯ , y m ) T x = ( x 1 , x 2 , ⋯ , x p ) T \boldsymbol{x} = (x_1, x_2, \cdots, x_p)^T x = ( x 1 , x 2 , ⋯ , x p ) T x ~ = ( 1 , x 1 , x 2 , ⋯ , x p ) T \widetilde{\boldsymbol{x}} = (1, x_1, x_2, \cdots, x_p)^T x = ( 1 , x 1 , x 2 , ⋯ , x p ) T
W = [ w 01 w 02 w 03 … w 0 m w 11 w 12 w 13 … w 1 m w 21 w 22 w 23 … w 2 m ⋯ w p 1 w p 2 w p 3 … w p m ] W = \begin{bmatrix}
w_{01}&w_{02}&w_{03}&\ldots&w_{0m}\\
w_{11}&w_{12}&w_{13}&\ldots&w_{1m}\\
w_{21}&w_{22}&w_{23}&\ldots&w_{2m}\\
&&\cdots\\
w_{p1}&w_{p2}&w_{p3}&\ldots&w_{pm}\\
\end{bmatrix}
W = w 01 w 11 w 21 w p 1 w 02 w 12 w 22 w p 2 w 03 w 13 w 23 ⋯ w p 3 … … … … w 0 m w 1 m w 2 m w p m
softmax函数
内层的模型发生了变化,那logistic回归中使用的sigmoid函数也得有其替代品,这就是softmax函数。我们来回顾一下,原来的编码方式,输出被解释为属于正类的概率,因此我们用sigmoid函数把输出压到了( 0 , 1 ) (0,1) ( 0 , 1 ) i i i i i i ( 0.8 , 0.05 , 0.15 ) (0.8,0.05,0.15) ( 0.8 , 0.05 , 0.15 ) softmax函数,其函数表达式为
y ‾ = s o f t m a x ( y ) , y ‾ i = e y i ∑ j = 1 m e y j \overline{\boldsymbol{y}} = \mathrm{softmax}(\boldsymbol{y}) , \quad
\overline{y}_i = \frac{e^{y_i}}{ \displaystyle \sum_{j=1}^{m} e^{y_j} }
y = softmax ( y ) , y i = j = 1 ∑ m e y j e y i
其中y = ( y 1 , y 2 , ⋯ , y m ) T \boldsymbol{y} = (y_1, y_2, \cdots, y_m)^T y = ( y 1 , y 2 , ⋯ , y m ) T y ‾ = ( y ‾ 1 , y ‾ 2 , ⋯ , y ‾ m ) T \overline{\boldsymbol{y}} = (\overline{y}_1, \overline{y}_2, \cdots, \overline{y}_m)^T y = ( y 1 , y 2 , ⋯ , y m ) T
可能会有同学看着有点懵,这是因为softmax函数是一个向量值函数 ,大家可能对此接触不多。其实很简单,就是说softmax函数输入是一个向量,输出也是一个向量。输入为向量y \boldsymbol{y} y y ‾ \overline{\boldsymbol{y}} y y ‾ \overline{\boldsymbol{y}} y
y ‾ i = e y i ∑ j = 1 m e y j \overline{y}_i = \frac{e^{y_i}}{ \displaystyle \sum_{j=1}^{m} e^{y_j} }
y i = j = 1 ∑ m e y j e y i
我们也可以把y ‾ \overline{\boldsymbol{y}} y
y ‾ = ( y ‾ 1 , y ‾ 2 , ⋯ , y ‾ m ) T = ( e y 1 ∑ j = 1 m e y j , e y 2 ∑ j = 1 m e y j , ⋯ , e y m ∑ j = 1 m e y j ) T \overline{\boldsymbol{y}} = (\overline{y}_1, \overline{y}_2, \cdots, \overline{y}_m)^T
= ( \frac{e^{y_1}}{ \displaystyle \sum_{j=1}^{m} e^{y_j} }, \frac{e^{y_2}}{ \displaystyle \sum_{j=1}^{m} e^{y_j} }, \cdots, \frac{e^{y_m}}{ \displaystyle \sum_{j=1}^{m} e^{y_j} })^T
y = ( y 1 , y 2 , ⋯ , y m ) T = ( j = 1 ∑ m e y j e y 1 , j = 1 ∑ m e y j e y 2 , ⋯ , j = 1 ∑ m e y j e y m ) T
这样应该比较清晰了。不难看出,softmax函数的想法是,先用指数函数将所有值均映射为正,然后再对数据进行概率归一化,以此达到目的。当然,softmax函数也可以写作矩阵形式
s o f t m a x ( y ) = e y 1 T e y \mathrm{softmax}(\boldsymbol{y}) = \frac{ e^{\boldsymbol{y}} }{\boldsymbol{1}^T e^{\boldsymbol{y}}}
softmax ( y ) = 1 T e y e y
注:只有当输入为向量时,上述矩阵形式才是正确的
至此,我们就可以得到softmax回归的模型为
F ( x ) = s o f t m a x ( f ( x ) ) = s o f t m a x ( W T x ~ ) F(\boldsymbol{x}) = \mathrm{softmax}(f(\boldsymbol{x})) = \mathrm{softmax}(W^{T} \widetilde{\boldsymbol{x}})
F ( x ) = softmax ( f ( x )) = softmax ( W T x )
交叉熵损失函数
最后就是解决损失函数了,其推导过程与logistic回归的对数似然损失函数是类似的,我们可以对比着来看。在上述推导中,我们构造了一个函数p ( x ) p(\boldsymbol{x}) p ( x ) ,这里也是一样的。首先,我们来约定一下符号,模型的输出F ( x ) F(\boldsymbol{x}) F ( x ) y \boldsymbol{y} y m × 1 m \times 1 m × 1 F ( j ) ( x ) F^{(j)}(\boldsymbol{x}) F ( j ) ( x ) y ( j ) \boldsymbol{y}^{(j)} y ( j ) j j j j j j
p ( x ) = ∏ j = 1 m [ F ( j ) ( x ) ] y ( j ) p(\boldsymbol{x}) = \prod_{j=1}^m [F^{(j)}(\boldsymbol{x})]^{\boldsymbol{y}^{(j)}}
p ( x ) = j = 1 ∏ m [ F ( j ) ( x ) ] y ( j )
可以看出,当样本属于第j j j y ( j ) = 1 \boldsymbol{y}^{(j)} = 1 y ( j ) = 1 y \boldsymbol{y} y 0 0 0 p ( x ) = F ( j ) ( x ) p(\boldsymbol{x}) = F^{(j)}(\boldsymbol{x}) p ( x ) = F ( j ) ( x ) 函数p ( x ) p(\boldsymbol{x}) p ( x ) ,完美完成任务。
接下来的流程与对数似然损失函数的推导是相同的,将所有样本的p ( x ) p(\boldsymbol{x}) p ( x )
∏ i = 1 n p ( x i ) = ∏ i = 1 n ∏ j = 1 m [ F ( j ) ( x i ) ] y i ( j ) \prod_{i=1}^n p(\boldsymbol{x_i}) = \prod_{i=1}^n \prod_{j=1}^m [F^{(j)}(\boldsymbol{x}_i)]^{\boldsymbol{y}_{i}^{(j)}}
i = 1 ∏ n p ( x i ) = i = 1 ∏ n j = 1 ∏ m [ F ( j ) ( x i ) ] y i ( j )
最后取对数再取负,得到损失函数为
L ( W ) = − l n ( ∏ i = 1 n p ( x i ) ) = − l n ( ∏ i = 1 n ∏ j = 1 m [ F ( j ) ( x i ) ] y i ( j ) ) = − ∑ i = 1 n ∑ j = 1 m y i ( j ) l n [ F ( j ) ( x i ) ] L(W) = - \mathrm{ln} \left( \prod_{i=1}^n p(\boldsymbol{x_i}) \right)
= - \mathrm{ln} \left( \prod_{i=1}^n \prod_{j=1}^m [F^{(j)}(\boldsymbol{x}_i)]^{\boldsymbol{y}_{i}^{(j)}} \right)
= - \sum_{i=1}^{n} \sum_{j=1}^{m} {y}_{i}^{(j)} \mathrm{ln} [F^{(j)}(\boldsymbol{x}_i)]
L ( W ) = − ln ( i = 1 ∏ n p ( x i ) ) = − ln ( i = 1 ∏ n j = 1 ∏ m [ F ( j ) ( x i ) ] y i ( j ) ) = − i = 1 ∑ n j = 1 ∑ m y i ( j ) ln [ F ( j ) ( x i )]
也可以写作矩阵形式
L ( W ) = − ∑ i = 1 n ∑ j = 1 m y i ( j ) ln y ^ i ( j ) = − ∑ i = 1 n y i ln y ^ i = − t r ( Y T ln Y ^ ) L(W) =
- \sum_{i=1}^{n} \sum_{j=1}^{m} {y}_{i}^{(j)} \ln \hat{y}_{i}^{(j)} =
- \sum_{i=1}^{n} \boldsymbol{y}_{i} \ln \hat{\boldsymbol{y}}_{i} =
- \mathrm{tr} (Y^T \ln \hat{Y})
L ( W ) = − i = 1 ∑ n j = 1 ∑ m y i ( j ) ln y ^ i ( j ) = − i = 1 ∑ n y i ln y ^ i = − tr ( Y T ln Y ^ )
这个损失函数被称为交叉熵损失函数,与对数似然函数相同,交叉熵损失函数也是使用优化算法进行求解,并且也可以加入正则化项。
注:交叉熵是一个信息论中的概念,该损失函数的推导也可从信息论的角度出发。
softmax回归与OvR策略
刚才我们有提到,softmax回归可以被归类为使用OvR策略,这里我们展开讲讲。首先,我们来思考一个问题,One-Hot编码的每一个分量,以及softmax回归的输出的每一个分量代表什么,比如说样本真实值( 1 , 0 , 0 ) T (1, 0, 0)^T ( 1 , 0 , 0 ) T ( 0.9 , 0.07 , 0.03 ) T (0.9, 0.07, 0.03)^T ( 0.9 , 0.07 , 0.03 ) T 属于其他类的概率为0.1 。其他类 ,这与OvR策略的思想不谋而合,我们再来想想,如果一个三分类问题用OvR策略做,那对于一个属于第一类的样本,第一个模型的真实值是不是也应该是1,后面两个模型的真实值是不是也应该是0。到这里我们就可以发现,softmax回归本质上就是把OvR策略构建的多个二分类模型合并成了一个用矩阵表示的模型,我们这里反过来,把softmax回归的模型写开,上文说过softmax回归模型为
y = f ( x ) = W T x ~ \boldsymbol{y} = f(\boldsymbol{x}) = W^{T} \widetilde{\boldsymbol{x}}
y = f ( x ) = W T x
把矩阵全部展开就是
[ y 1 y 2 y 3 ⋯ y m ] = [ w 01 w 11 w 21 … w p 1 w 02 w 12 w 22 … w p 2 w 03 w 13 w 23 … w p 3 ⋯ w 0 m w 1 m w 2 m … w p m ] [ 1 x 1 x 2 ⋯ x p ] \begin{bmatrix}
y_{1}\\
y_{2}\\
y_{3}\\
\cdots\\
y_{m}
\end{bmatrix}
=
\begin{bmatrix}
w_{01}&w_{11}&w_{21}&\ldots&w_{p1}\\
w_{02}&w_{12}&w_{22}&\ldots&w_{p2}\\
w_{03}&w_{13}&w_{23}&\ldots&w_{p3}\\
&&\cdots\\
w_{0m}&w_{1m}&w_{2m}&\ldots&w_{pm}\\
\end{bmatrix}
\begin{bmatrix}
1\\
x_{1}\\
x_{2}\\
\cdots\\
x_{p}
\end{bmatrix}
y 1 y 2 y 3 ⋯ y m = w 01 w 02 w 03 w 0 m w 11 w 12 w 13 w 1 m w 21 w 22 w 23 ⋯ w 2 m … … … … w p 1 w p 2 w p 3 w p m 1 x 1 x 2 ⋯ x p
把y \boldsymbol{y} y
{ y 1 = w 01 + w 11 x 1 + w 21 x 2 + ⋯ + w p 1 x p y 2 = w 02 + w 12 x 1 + w 22 x 2 + ⋯ + w p 2 x p y 3 = w 03 + w 13 x 1 + w 23 x 2 + ⋯ + w p 3 x p ⋯ y m = w 0 m + w 1 m x 1 + w 2 m x 2 + ⋯ + w p m x p \begin{cases}
y_1 = w_{01} + w_{11} x_1 + w_{21} x_2 + \cdots + w_{p1} x_p \\
y_2 = w_{02} + w_{12} x_1 + w_{22} x_2 + \cdots + w_{p2} x_p \\
y_3 = w_{03} + w_{13} x_1 + w_{23} x_2 + \cdots + w_{p3} x_p \\
\qquad \qquad \qquad \qquad \cdots\\
y_m = w_{0m} + w_{1m} x_1 + w_{2m} x_2 + \cdots + w_{pm} x_p \\
\end{cases}
⎩ ⎨ ⎧ y 1 = w 01 + w 11 x 1 + w 21 x 2 + ⋯ + w p 1 x p y 2 = w 02 + w 12 x 1 + w 22 x 2 + ⋯ + w p 2 x p y 3 = w 03 + w 13 x 1 + w 23 x 2 + ⋯ + w p 3 x p ⋯ y m = w 0 m + w 1 m x 1 + w 2 m x 2 + ⋯ + w p m x p
我们可以发现整个softmax回归的内层模型被拆分成了m m m m m m
sklearn代码实现
最后我们来介绍一下线性回归的sklearn代码实现,运行环境为jupyter notebook
注1:sklearn是机器学习中常用的python库,其封装了大多数常见的机器学习算法,使得复杂的机器学习算法可以在短短几行代码中被实现,俗称“调包”(bushi。下面的内容会建立在对sklearn有简单了解的基础上,没有接触过sklearn的读者可移步sklearn快速入门 作简单了解。
注2:以下内容会介绍实现算法的函数及其重要参数,并且用sklearn中自带的小型数据集跑一个简单的demo。主要目的是将sklearn中的参数跟理论部分做一个对照,知道理论部分中讲到的参数在sklearn中是哪个,怎么调。还有就是简单把这个算法跑一遍,不过由于机器学习是一门以实践为主的学科,我们用sklearn中自带的小型数据集做的demo的作用也就仅此而已了,其对实际工程中的调参没有任何参考意义,仅仅是告诉你这个算法怎么跑起来。
注3:本文并不会把函数的细节讲得面面俱到,甚至参数都只是调重要或常用的讲,想要详细了解的可以参考sklearn官方文档 或者sklearn中文文档 。
我们先做一些前期工作,导入依赖库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom sklearn.linear_model import LinearRegression from sklearn.linear_model import Ridge from sklearn.linear_model import Lasso from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_wine from sklearn.datasets import load_diabetes from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_score import warningswarnings.filterwarnings("ignore" )
我们使用红酒数据集与糖尿病数据集作为示例数据,这里我们使用sklearn自带的数据模块,读取数据代码为
1 2 3 wine = load_wine() diabetes = load_diabetes()
1 2 3 4 5 data_c = pd.DataFrame(wine.data) data_c.columns = wine.feature_names target_c = pd.DataFrame(wine.target) target_c.columns = ['class' ]
1 2 3 4 5 data_r = pd.DataFrame(diabetes.data) data_r.columns = diabetes.feature_names target_r = pd.DataFrame(diabetes.target) target_r.columns = ['Y' ]
好,做完准备工作我们正式开始讲算法实现
多元线性回归
首先是多元线性回归,该算法用于解决回归问题,因此我们使用糖尿病数据集作为示例数据集,对糖尿病数据集进行训练集与测试集的划分
1 2 Xtrain, Xtest, Ytrain, Ytest = train_test_split(data_r, target_r, test_size=0.2 )
在sklearn中,实现多元线性回归的函数为LinearRegression(),由于模型简单且sklearn中使用解析解,所以其参数非常少,只有四个参数,并且大多数时候全默认就可以,参数列表如下
参数
说明
fit_intercept 是否计算此模型的截距。默认为True,如果设置为False,则在计算中将不使用截距(即,数据应中心化)。
normalize 默认为False,如果为True,则在回归之前通过减去均值并除以L2-范数来对回归变量X进行归一化。
copy_X 默认为True,将复制X,否则X可能会被覆盖。
n_jobs 用于计算的核心数。
可以看到,线性回归的参数简单,而且是真的没什么可以调的,下面是sklearn经典建模步骤
1 2 3 4 clf = LinearRegression() clf.fit(Xtrain, Ytrain) clf.score(Xtest, Ytest)
如果想要获知确切的参数,线性回归算法还有两个属性可以用
1 2 clf.coef_ clf.intercept_
岭回归与Lasso回归
在sklearn中,实现岭回归与Lasso回归的函数为Ridge()与Lasso(),其重要的参数只有一个,就是正则化系数alpha
1 2 3 4 5 6 7 8 9 clf = Ridge(alpha=0.02 ) clf.fit(Xtrain, Ytrain) clf.score(Xtest, Ytest) clf = Lasso(alpha=0.02 ) clf.fit(Xtrain, Ytrain) clf.score(Xtest, Ytest)
而该参数的调整方法与众多机器学习算法的调整方法是一样的,就是暴力搜索,找到效果最好的,一般会画个超参数图像看看模型效果在不同参数下是怎么样的,下面是绘制超参数图像的兼用卡代码
1 2 3 4 5 6 7 8 9 10 11 12 13 test = [] for i in range (100 ): clf = Lasso(alpha=i*0.01 ) score = cross_val_score(clf, Xtrain, Ytrain, cv=10 ).mean() test.append(score) plt.plot(np.arange(0.01 , 1.01 , 0.01 ),test,color="red" ,label="alpha" ) plt.legend() test_max = max (test) print ("最高准确率:" , test_max)print ("最佳参数" , test.index(test_max)*0.02 )
注:如果是一些调整范围比较大的参数,例如需要从1到200进行暴力搜索,为了节省算力与时间一般会使用变步长搜索。很简单,就是先设置一个比较大的步长,比如5,然后假如搜索出来最佳参数是45,那我们就缩小范围,例如30到60,再缩小步长,例如1,做更高精度的搜索,这就是所谓“变步长”,一般来个一次也就差不多了。
logistic回归与softmax回归
最后是logistic回归与softmax回归,这两个算法均用于解决分类问题,因此我们使用红酒数据集作为示例数据集,对红酒数据集划分训练集与测试集
1 2 Xtrain, Xtest, Ytrain, Ytest = train_test_split(data_c, target_c, test_size=0.2 )
在sklearn中,实现logistic回归与softmax回归的函数为LogisticRegression(),这个函数参数就比较多了,我们分类来看
正则化
参数
说明
penalty 正则化方法,可填{‘L1’, ‘L2’, ‘elasticnet’, ‘none’},分别代表L1正则化,L2正则化,同时使用L1正则化与L2正则化,以及不使用正则化。默认为使用L2正则化。
C 正则化系数的倒数 ,注意是倒数 ,也就是数值越小,正则化强度越高。
多分类
参数
说明
multi_class 多分类策略,可填{‘auto’, ‘ovr’, ‘multinomial’},分别表示自动选择,OvR策略与MvM策略。
优化算法
参数
说明
solver 优化算法,可填{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’},默认为‘lbfgs’。
max_iter 优化算法的最大迭代轮次,可以用参数曲线调出效果最好的迭代轮次。
random_state 随机数种子,用于确保优化算法每次运行结果一致。
虽然参数挺多的,但是需要调的并不是很多,大多数参数还是根据数据集的情况做选择就好了,真正需要调的也就是正则化系数,调整方法跟上面的线性回归一样,照例放一组兼用卡代码
1 2 3 4 clf = LogisticRegression(multi_class='ovr' , penalty='l1' , solver='saga' , C=1.0 , random_state=1008 , max_iter=10000 ) clf.fit(Xtrain, Ytrain) clf.score(Xtest, Ytest)
补充:从零实现线性回归
随着机器学习与深度学习的发展,许多常用的机器学习算法都有非常好用的依赖库可以进行调用,这对于我们运用机器学习算法解决实际问题自然是十分方便的,但是这也导致长时间以来,对于在学习机器学习算法时是否需要从零实现算法这个问题,一直有着两派观点。一派认为学习机器学习算法只需要理解原理即可,而另一派则认为从零实现算法有助于更好的理解算法本身,因此,笔者选择将这部分内容放入补充,以上。
准备工作
虽然说我们要从零实现算法,但这并不代表我们不会使用任何的第三方库,我认为实现算法就是一个将数学语言翻译为计算机编程语言的过程 ,在上文中,我们应该可以感受到线性回归中存在大量的矩阵运算,而python对矩阵运算的原生支持是很差的,因此,我们会大量依赖numpy这个第三方库。
注:如R语言,MATLAB等对矩阵运算的支持就非常好而且自然,写起来非常舒服,而python毕竟还是计算机语言,即使用上了numpy也有一些在学数学的人看来很奇怪的地方,在后续实现中我会提到,不过这都不是什么大问题。
numpy是一个科学计算库,其对矩阵运算有着很好的支持,对于从零实现算法是合适的选择,同时我们还会使用sklearn库中的数据生成器,生成数据用于验证算法是否正确实现。下面是导入依赖库的代码,运行环境为jupyter notebook
1 2 3 4 5 6 7 import numpy as npfrom sklearn.datasets import make_regression from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split
注:对numpy不熟悉的读者可以移步NumPy官方快速入门 ,也有对应的NumPy官方快速入门中文版 。在后文中,所有实现过程都将使用numpy中的array数据类型。
梯度下降
然后是梯度下降 的实现,在本站的梯度下降博客 中已经给出了小批量梯度下降的numpy实现,这里就直接挪用,代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def LR_train (features, labels, criterion, epochs_num, batch_size=10 , alpha=0.01 ): def data_iter (batch_size, features, labels ): data_size = np.size(features, 0 ) index = np.random.permutation(data_size) for i in range (0 , data_size, batch_size): batch_index = index[i: min (i + batch_size, data_size)] X, y = features[batch_index], labels[batch_index] X, y = X.reshape(np.size(batch_index), -1 ), y.reshape(np.size(batch_index), -1 ) yield X, y def gradient_descent (w, gradient, alpha ): w = w - alpha * gradient return w w = np.random.normal(loc=0 , scale=0.1 , size=(np.size(features, 1 )+1 , 1 )) for epoch in range (epochs_num): for X, y in data_iter(batch_size=batch_size, features=features, labels=labels): gradient = criterion.gradient(w, X, y) w = gradient_descent(w, gradient, alpha) train_l = criterion(w, features, labels) print (f'epoch {epoch + 1 } , loss {float (train_l):f} ' ) return w
当然也进行了一些小改动,由于本章节后续需要实现多个算法,每一个算法都是一个不同的损失函数,因此将损失函数改为了参数。
多元线性回归numpy实现
数据集生成
使用sklearn.datasets中的make_regression函数生成用于回归问题的样本数据,生成数据的代码如下
1 2 3 4 5 6 7 8 9 10 11 bias = 8 X, y, coef = make_regression( n_samples=1008 , n_features=3 , n_informative=3 , n_targets=1 , bias=bias, coef=True , noise=1 , random_state=1008 )
具体各参数的含义已经写在注释中了,这里重点说几个参数,首先是bias与coef=True,这两个吃饭时代表了该数据集的“正确答案”,后续实现的算法计算得到的权重越接近返回的coef,偏置越接近bias,则说明其效果越好。然后是n_informative有效特征数,其代表参与计算y的特征数量,如果其小于特征数n_features,则代表有特征与y无关,是无效特征,其权重的“正确答案”应该为0,这里为简单起见,设定所有特征均有效。
解析解实现
现在,我们正式进入多元线性回归的实现,我们先从解析解开始。解析解的实现及其的简单,简单到其核心只有一行代码,就是
1 w = np.linalg.inv(X.T @ X) @ X.T @ y
回顾上述所讲,虽然我们说求解线性回归等价于求解损失函数的最小值,但是解析解已经把这个最小值表示出来了 ,这代表着我们根本就不需要管什么损失函数,只需要把解析解这个式子算出来就行了 ,就这么简单。线性回归的解析解数学上写为
w ^ = ( X T X ) − 1 X T y \hat{\boldsymbol{w}} = (X^T X)^{-1} X^T \boldsymbol{y}
w ^ = ( X T X ) − 1 X T y
numpy中可以用运算符@实现矩阵乘法,用.T代表转置,逆矩阵可以使用np.linalg.inv()函数实现,现在我们就可以把上面的式子翻译成代码了,也就是刚才那一行核心代码,将其封装成函数。需要注意,上述公式中的X X X X X X
1 2 3 4 5 6 7 def LR_compute (X, y ): X = np.hstack((np.ones((np.size(X, 0 ), 1 )), X)) w = np.linalg.inv(X.T @ X) @ X.T @ y w = w.reshape(-1 , 1 ) return w
再写一个函数用于预测,核心就是计算y = X w \boldsymbol{y} = X\boldsymbol{w} y = X w
1 2 3 4 5 6 def LR_predict (X, w ): X = X.reshape(-1 , len (w)-1 ) X = np.hstack((np.ones((np.size(X, 0 ), 1 )), X)) y_hat = X @ w return y_hat
注:在线性代数中,向量与矩阵都是二维的,但是在numpy中常常会使用一维的array来储存向量,例如上述生成数据集中生成的y就是一个一维array。在使用numpy实现算法的过程中,一维的array就像一个幽灵,容易在不经意间让你的代码报错。
因此,我们会常常使用.reshape方法来保证array有正确的形状。例如上述代码中的X = X.reshape(-1, len(w)-1),其中-1代表由程序指定,例如X本身的形状是(504, 2),那就会被转化为(1, 1008),如果X的形状是(1008,),那就会被转化为(1, 1008),这也是reshape方法常用的写法。
数值解与正则化实现
损失函数及其梯度
然后来到了多元线性回归的数值解,梯度下降上面已经实现好了,现在需要做的就是两件事,第一,实现损失函数的计算,第二,实现损失函数梯度的计算。对于多元线性回归来说,损失函数为
L ( w ) = ∣ ∣ y − X w ∣ ∣ 2 = ( y − X w ) T ( y − X w ) L(\boldsymbol{w}) = ||\boldsymbol{y} - X\boldsymbol{w}||^2 = (\boldsymbol{y} - X\boldsymbol{w})^{T} (\boldsymbol{y} - X\boldsymbol{w})
L ( w ) = ∣∣ y − X w ∣ ∣ 2 = ( y − X w ) T ( y − X w )
损失函数的梯度为
∂ L ∂ w = 2 X T ( X w − y ) \frac{ \partial L }{ \partial \boldsymbol{w} } = 2 X^{T} (X \boldsymbol{w} - y)
∂ w ∂ L = 2 X T ( X w − y )
将上述两个计算公式翻译为代码,我们就得到了两行核心代码
1 2 3 4 l = (y - X @ w).T @ (y - X @ w) lg = 2 * (X.T @ (X @ w - y))
正则化
由于岭回归与Lasso回归,即正则化的实现,就是给损失函数添加正则项,故在此一并做实现。正则化的实现其实也非常简单,由于正则项是加在损失函数后面的,因此,其梯度也是直接加在损失函数的梯度上,故我们只需要实现两种正则项以及其梯度的计算,再根据需要加在损失值与梯度值上即可。L 1 L_1 L 1 L 2 L_2 L 2
∣ ∣ w ∣ ∣ 1 = ∣ w 1 ∣ + ∣ w 2 ∣ + ⋯ + ∣ w p ∣ || \boldsymbol{w} ||_1 = |w_1| + |w_2| + \cdots + |w_p|
∣∣ w ∣ ∣ 1 = ∣ w 1 ∣ + ∣ w 2 ∣ + ⋯ + ∣ w p ∣
∣ ∣ w ∣ ∣ 2 2 = w 1 2 + w 2 2 + ⋯ + w p 2 = w T w || \boldsymbol{w} ||_2^2 = w_1^2 + w_2^2 + \cdots + w_p^2 = \boldsymbol{w}^T \boldsymbol{w}
∣∣ w ∣ ∣ 2 2 = w 1 2 + w 2 2 + ⋯ + w p 2 = w T w
可以看到L 1 L_1 L 1 L 2 L_2 L 2 numpy中也提供了linalg.norm()函数用于计算范数,因此,实现L 1 L_1 L 1 L 2 L_2 L 2
1 2 3 4 5 6 7 L1 = np.sum (np.abs (w)) L1 = np.linalg.norm(w, ord =1 ) L2 = np.sum (w ** 2 ) L2 = w.T @ w L2 = np.linalg.norm(w, ord =2 ) ** 2
而L 1 L_1 L 1 L 2 L_2 L 2
∂ ∣ ∣ w ∣ ∣ 1 ∂ w = s i g n ( w ) \frac{ \partial || \boldsymbol{w} ||_1 }{ \partial \boldsymbol{w} } = \mathrm{sign}(\boldsymbol{w})
∂ w ∂ ∣∣ w ∣ ∣ 1 = sign ( w )
∂ ∣ ∣ w ∣ ∣ 2 2 ∂ w = 2 w \frac{ \partial || \boldsymbol{w} ||_2^2 }{ \partial \boldsymbol{w} } = 2\boldsymbol{w}
∂ w ∂ ∣∣ w ∣ ∣ 2 2 = 2 w
翻译为代码则为
1 2 3 4 L1_g = np.sign(w) L2_g = 2 * w
封装
最后,我们选择将上面的成果封装为类,代码有点长,我们先看完整代码再来讲,完整代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 class MSELoss (): def __init__ (self, regularization='none' , weight_decay=1 ): valid_regularizations = ['none' , 'L1' , 'L2' ] if regularization not in valid_regularizations: raise ValueError(f"Invalid regularization type. Expected one of {valid_regularizations} , but got '{regularization} '" ) self.regularization = regularization self.weight_decay = weight_decay def __call__ (self, w, X, y ): I = np.ones((np.size(X, 0 ), 1 )) X = np.hstack((I, X)) w = np.array(w) w = w.reshape(-1 , 1 ) y = np.array(y) y = y.reshape(-1 , 1 ) l = (y - X @ w).T @ (y - X @ w) l = l / np.size(X, 0 ) if self.regularization == 'L1' : coef = np.delete(w, 0 , axis=0 ) l = l + self.weight_decay * np.linalg.norm(coef, ord =1 ) elif self.regularization == 'L2' : coef = np.delete(w, 0 , axis=0 ) l = l + self.weight_decay * (np.linalg.norm(coef, ord =2 ) ** 2 ) return l def gradient (self, w, X, y ): I = np.ones((np.size(X, 0 ), 1 )) X = np.hstack((I, X)) w = np.array(w) w = w.reshape(-1 , 1 ) y = np.array(y) y = y.reshape(-1 , 1 ) lg = 2 * (X.T @ (X @ w - y)) lg = lg / np.size(X, 0 ) if self.regularization == 'L1' : coef = w coef[0 ] = 0 lg = lg + self.weight_decay * np.sign(coef) if self.regularization == 'L2' : coef = w coef[0 ] = 0 lg = lg + self.weight_decay * 2 * coef return lg
首先,由于考虑了正则化,我们需要定义变量来控制是否使用正则化,以及正则化系数是多少,这部分在类的初始化中实现。然后,计算损失值与计算梯度被写成了类的两个方法,计算损失值的部分使用了__call__方法,这是python类中的一个魔法方法,其作用是让类实例可以像调用函数一样被调用,计算梯度的部分则被写入了gradient方法。接着,在计算损失值与梯度前的代码,实现了对X X X w \boldsymbol{w} w y y y
最后,是正则化的实现部分,这里有两个需要注意的点,第一,损失值与梯度不包含正则项的部分,需要先除以样本数,再与正则项相加,以损失值的计算为例,使用L 2 L_2 L 2
L ( w ) = ∣ ∣ y − X w ∣ ∣ 2 + α ∣ ∣ w ∣ ∣ 2 L(\boldsymbol{w}) = ||\boldsymbol{y} - X\boldsymbol{w}||^2 + \alpha ||\boldsymbol{w}||^2
L ( w ) = ∣∣ y − X w ∣ ∣ 2 + α ∣∣ w ∣ ∣ 2
不难发现,前面一项是与样本量有关的,因为y \boldsymbol{y} y X X X batch_size参数对正则化强度无影响,也就是
L ( w ) = 1 n ∣ ∣ y − X w ∣ ∣ 2 + α ∣ ∣ w ∣ ∣ 2 L(\boldsymbol{w}) = \frac{1}{n} ||\boldsymbol{y} - X\boldsymbol{w}||^2 + \alpha ||\boldsymbol{w}||^2
L ( w ) = n 1 ∣∣ y − X w ∣ ∣ 2 + α ∣∣ w ∣ ∣ 2
如果不这样处理,那么在训练调参时,将batch_size调大,则前一项会变大,这其实相当于将weight_decay调小(在损失函数中,数值越大就越有话语权,想想为什么正则化系数越大,正则化强度越高,应该不难理解吧)。
第二,偏置项w 0 w_0 w 0 w \boldsymbol{w} w w 0 w_0 w 0 w 0 w_0 w 0 0 0 0 0 0 0
解析解与数值解测试
最后,我们需要测试一下上述实现代码,由于回归问题是有所谓的”正确答案“的,对于两种求解方式,我们的测试方法就是看求解出来的参数结果是否接近”正确答案“,这里我们先把”正确答案“定义出来,以便后续使用
1 w_true = np.insert(coef, 0 , bias).reshape(-1 , 1 )
先从解析解开始测试,使用上述实现的函数进行求解出w,并与w_true相减
1 2 w = LR_compute(X, y) w - w_true
输出结果为
1 2 3 4 array([[ 0.00714635], [-0.04096568], [ 0.03152433], [ 0.01598949]])
然后是数值解,代码与输出结果如下
1 2 criterion = MSELoss() w = LR_train(X, y, criterion, epochs_num=10 , batch_size=64 , alpha=0.05 )
1 2 3 4 5 6 7 8 9 10 epoch 1, loss 474.756124 epoch 2, loss 16.673691 epoch 3, loss 1.520759 epoch 4, loss 0.959252 epoch 5, loss 0.949348 epoch 6, loss 0.946817 epoch 7, loss 0.946365 epoch 8, loss 0.947011 epoch 9, loss 0.946535 epoch 10, loss 0.946679
1 2 3 4 array([[-0.00812155], [-0.03824893], [ 0.02039796], [ 0.02474028]])
可以看出两种求解方式的效果都非常理想。
正则化测试
然后是正则化的测试,上文就提到,正则化是用于防止过拟合的一项技术,因此,我们先将数据集变得复杂一些,主要是加入一些无效特征,使得数据集更容易过拟合,然后将数据集划分为训练集与测试集
1 2 3 4 5 6 7 8 9 10 11 12 X, y, coef = make_regression( n_samples=1008 , n_features=30 , n_informative=3 , n_targets=1 , bias=8 , coef=True , noise=10 , random_state=1008 ) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25 , random_state=1008 )
使用多元线性回归与岭回归,在训练集上分别计算出结果
1 2 criterion = MSELoss() w = LR_train(X_train, y_train, criterion, epochs_num=10 , batch_size=64 , alpha=0.05 )
1 2 3 4 5 6 7 8 9 10 epoch 1, loss 366.210005 epoch 2, loss 121.428784 epoch 3, loss 99.172641 epoch 4, loss 97.034523 epoch 5, loss 96.523046 epoch 6, loss 96.505926 epoch 7, loss 96.980217 epoch 8, loss 96.564764 epoch 9, loss 96.713952 epoch 10, loss 96.512866
1 2 criterion_r = MSELoss(regularization='L2' , weight_decay=0.01 ) w_r = LR_train(X_train, y_train, criterion_r, epochs_num=10 , batch_size=64 , alpha=0.05 )
1 2 3 4 5 6 7 8 9 10 epoch 1, loss 401.374109 epoch 2, loss 155.507344 epoch 3, loss 135.353584 epoch 4, loss 133.308615 epoch 5, loss 132.809783 epoch 6, loss 132.812304 epoch 7, loss 132.908994 epoch 8, loss 132.649182 epoch 9, loss 132.956535 epoch 10, loss 132.915263
再分别计算两者在测试集上的损失值
1 criterion(w, X_test, y_test)
1 criterion(w_r, X_test, y_test)
可以看到,在复杂的数据集上,使用了正则化的模型,在测试集上的表现要优于不使用正则化的模型。
logistic回归numpy实现
数据集生成
然后,我们来到logistic回归的实现,作为处理分类问题的模型,我们自然不能继续使用上面的数据集了。使用sklearn.datasets中的make_classification函数生成用于分类问题的样本数据,生成数据的代码如下
1 2 3 4 5 6 7 8 9 10 X, y = make_classification( n_samples=1008 , n_features=3 , n_informative=3 , n_redundant=0 , n_classes=2 , class_sep=1 , flip_y=0.1 , random_state=1008 )
这里重点说两个参数,首先是class_sep样本分离度,由于生成分类数据的原理是,先生成几个类别中心,再在类别中心周围生成数据,而class_sep代表了类别中心的分离度,class_sep越大不同的类别中心距离越远,则数据的划分会变得更容易。然后是flip_y标签噪声,其代表有一定比例的样本会被随机赋予标签,同理,噪声越大,数据集越难。
sigmoid函数实现
搞定了数据集,按理说可以进入模型的实现了,但是在此之前,我们需要先实现sigmoid函数,后面的实现过程会多次用上,sigmoid函数的表达式为
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}}
σ ( x ) = 1 + e − x 1
翻译为代码就是
但是事情并没有那么简单,这涉及到计算机中的算术溢出 问题,这里我们不详细解释,仅作简单说明。
算术溢出问题
简单来说,计算机中的所有变量都是有表示范围的 ,如果学习过如C语言这类比较传统的计算机语言的读者,对此应该并不陌生,例如32位有符号整数的表示范围为-2147483648至2147483647,当变量的数值超过其表示范围时,就会出现各种各样的bug,例如著名的2147483647 + 1 = -2147483648。
而浮点数的情况会更复杂一点,例如,深度学习常用32位有符号浮点数,其表示范围约为1.17 × 1 0 − 38 1.17 \times 10^{-38} 1.17 × 1 0 − 38 3.4 × 1 0 38 3.4 \times 10^{38} 3.4 × 1 0 38 − 3.4 × 1 0 38 -3.4 \times 10^{38} − 3.4 × 1 0 38 − 1.17 × 1 0 − 38 -1.17 \times 10^{-38} − 1.17 × 1 0 − 38 0 0 0 0 0 0
最后,在python中,情况又会有一些不同,毕竟python在设计之初就是面向不熟悉计算机底层的使用者,其设计时也考虑了算术溢出问题。python的处理是对发生了算术溢出的变量赋予零或无穷,python中使用符号inf代表数学中的无穷符号,当变量数值超过表示范围的最大值时,变量会被赋值inf,同理,变量数值小于表示范围时则赋值-inf,而当变量数值落入0 0 0 0。
现在,让我们回到sigmoid函数,不难发现,由于指数函数的存在,不需要很大的x就会引发算术溢出的问题,例如,np.exp(1000) = inf,np.exp(-1000) = 0。而解决办法也很简单,就是截断,例如设定输入范围为[ − 15 , 15 ] [-15, 15] [ − 15 , 15 ] 15 15 15 − 15 -15 − 15
1 2 3 4 def fun_sigmoid (x, clip_threshold=15 ): x = np.clip(x, -clip_threshold, clip_threshold) return 1 / (1 + np.exp(-x))
注:有读者可能会疑惑,即便产生了数值问题,sigmoid函数的函数值也就是为0或1,虽然对sigmoid函数来说这是不可能的输出,但是也不会造成什么问题吧。非也,问题出在后面的对数似然损失函数,如果sigmoid函数的函数值为0或1,则会出现ln 0 \ln0 ln 0
损失函数与梯度计算
现在正式进入logistic回归的实现,经过前面多元线性回归的铺垫,我们只需要实现logistic回归损失函数及其梯度的计算即可,剩下的东西都是一样的,损失函数及其梯度的表达式为
L ( w ) = − ∑ i = 1 n y i l n y ^ i + ( 1 − y i ) l n ( 1 − y ^ i ) = − y T ln y ^ − ( 1 − y ) T ln ( 1 − y ^ ) L(\boldsymbol{w}) =
- \sum_{i=1}^{n} y_i \mathrm{ln} \hat{y}_i + (1 - y_i)\mathrm{ln} (1 - \hat{y}_i)
= - \boldsymbol{y}^T \ln \hat{\boldsymbol{y}} - (\boldsymbol{1} - \boldsymbol{y})^T \ln (\boldsymbol{1} - \hat{\boldsymbol{y}})
L ( w ) = − i = 1 ∑ n y i ln y ^ i + ( 1 − y i ) ln ( 1 − y ^ i ) = − y T ln y ^ − ( 1 − y ) T ln ( 1 − y ^ )
∂ L ∂ w = − X T [ ( y ⊙ ( 1 − y ^ ) ) + ( ( 1 − y ) ⊙ y ^ ) ] \frac{ \partial L }{ \partial \boldsymbol{w} } = - X^{T} [ (\boldsymbol{y} \odot (\boldsymbol{1} - \hat{\boldsymbol{y}})) + ((\boldsymbol{1} - \boldsymbol{y}) \odot \hat{\boldsymbol{y}}) ]
∂ w ∂ L = − X T [( y ⊙ ( 1 − y ^ )) + (( 1 − y ) ⊙ y ^ )]
其中
y ^ = σ ( X w ) \hat{\boldsymbol{y}} = \sigma(X \boldsymbol{w})
y ^ = σ ( X w )
注:⊙ \odot ⊙ Hadamard积 ,其表示两个形状相同的向量或矩阵逐元素相乘,在numpy中直接使用*运算符即可实现
将上述表达式翻译为代码
1 2 3 4 5 y_hat = fun_sigmoid(X @ w).reshape(-1 , 1 ) l = - (y.T @ np.log(y_hat)) - ((1 - y).T @ np.log(1 - y_hat)) lg = X.T @ ((1 - y) * y_hat - y * (1 - y_hat))
最后封装为类,完整代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 class NLLLoss (): def __init__ (self, regularization='none' , weight_decay=1 , clip_threshold=15 ): valid_regularizations = ['none' , 'L1' , 'L2' ] if regularization not in valid_regularizations: raise ValueError(f"Invalid regularization type. Expected one of {valid_regularizations} , but got '{regularization} '" ) self.regularization = regularization self.weight_decay = weight_decay self.clip_threshold = clip_threshold def __call__ (self, w, X, y ): I = np.ones((np.size(X, 0 ), 1 )) X = np.hstack((I, X)) w = np.array(w) w = w.reshape(-1 , 1 ) y = np.array(y) y = y.reshape(-1 , 1 ) y_hat = self.__fun_sigmoid(X @ w).reshape(-1 , 1 ) l = - (y.T @ np.log(y_hat)) - ((1 - y).T @ np.log(1 - y_hat)) l = l / np.size(X, 0 ) if self.regularization == 'L1' : coef = np.delete(w, 0 , axis=0 ) l = l + self.weight_decay * np.linalg.norm(coef, ord =1 ) elif self.regularization == 'L2' : coef = np.delete(w, 0 , axis=0 ) l = l + self.weight_decay * (np.linalg.norm(coef, ord =2 ) ** 2 ) return l def gradient (self, w, X, y ): I = np.ones((np.size(X, 0 ), 1 )) X = np.hstack((I, X)) w = np.array(w) w = w.reshape(-1 , 1 ) y = np.array(y) y = y.reshape(-1 , 1 ) y_hat = self.__fun_sigmoid(X @ w).reshape(-1 , 1 ) lg = X.T @ ((1 - y) * y_hat - y * (1 - y_hat)) lg = lg / np.size(X, 0 ) if self.regularization == 'L1' : coef = w coef[0 ] = 0 lg = lg + self.weight_decay * np.sign(coef) if self.regularization == 'L2' : coef = w coef[0 ] = 0 lg = lg + self.weight_decay * 2 * coef return lg def __fun_sigmoid (self, x ): x = np.clip(x, -self.clip_threshold, self.clip_threshold) return 1 / (1 + np.exp(-x))
代码就是上面多元线性回归的代码,改了损失函数跟梯度的计算公式,再加了个sigmoid函数,这里就不多赘述了。
测试
最后,我们对上面实现的代码简单做个测试,由于分类问题的数据集没有所谓的“正确答案”,因此我们直接看准确率,写一个简单的函数用于测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def logistic_regression_test (w, X, y ): def fun_sigmoid (x, clip_threshold=15 ): x = np.clip(x, -clip_threshold, clip_threshold) return 1 / (1 + np.exp(-x)) I = np.ones((np.size(X, 0 ), 1 )) X = np.hstack((I, X)) y_hat = fun_sigmoid(X @ w).reshape(-1 ) y_hat = (y_hat >= 0.5 ).astype(int ) return np.sum (y == y_hat) / np.size(X, 0 )
1 2 criterion = NLLLoss() w = LR_train(X, y, criterion, epochs_num=10 , batch_size=64 , alpha=0.01 )
1 2 3 4 5 6 7 8 9 10 epoch 1, loss 0.735997 epoch 2, loss 0.693674 epoch 3, loss 0.657632 epoch 4, loss 0.626926 epoch 5, loss 0.600610 epoch 6, loss 0.578014 epoch 7, loss 0.558276 epoch 8, loss 0.541183 epoch 9, loss 0.526265 epoch 10, loss 0.513075
1 logistic_regression_test(w, X, y)
softmax回归实现
数据集生成
最后,我们来到了softmax回归的实现,经过了前面的铺垫,到这里基本上没有什么特别要讲的了,分类数据集的生成同logistic回归,使用make_classification函数,只需将类别数改为多类即可
1 2 3 4 5 6 7 8 9 10 X, y = make_classification( n_samples=1008 , n_features=3 , n_informative=3 , n_redundant=0 , n_classes=3 , class_sep=1.1 , flip_y=0.15 , random_state=1008 )
softmax函数实现
然后是softmax函数的实现,其相比于sigmoid函数还是要复杂一点,在此之前我们还是先来看看表达式
s o f t m a x ( x ) = e x 1 T e x \mathrm{softmax}(\boldsymbol{x}) = \frac{ e^{\boldsymbol{x}} }{\boldsymbol{1}^T e^{\boldsymbol{x}}}
softmax ( x ) = 1 T e x e x
在numpy中,由于广播机制的存在,我们并不需要严格按照数学表达式来,代码实现如下
1 np.exp(x) / np.sum (np.exp(x), 0 )
好,现在我们来解决softmax函数的问题,首先,由于softmax函数是一个向量值函数,而我们需要考虑小批量的情况,也就是说,输入可能为一个向量,也可能是多个向量组成的矩阵,无论何种情况都需要保证正确的输出,对于向量值函数,这两种输入是有区别的,而对于sigmoid函数来说就没有这个问题。
其次,sigmoid函数中提到的算术溢出问题,在softmax函数中依然存在,不过解决方法稍有不同,softmax函数中的解决方法是,将输入向量均减去向量最大值,也就是对向量数值作一个平移,这并不会改变softmax函数的函数值,非常优雅,读者可以自行验证。综上,完整实现代码如下
1 2 3 4 5 6 7 8 9 10 def fun_softmax (x ): if np.ndim(x) == 1 : axis = 0 else : axis = 1 x = x - np.max (x, axis=axis, keepdims=True ) return np.exp(x) / np.sum (np.exp(x), axis).reshape(-1 , 1 )
损失函数与梯度计算
最后是损失函数及其梯度计算,交叉熵损失函数的表达式及其梯度表达式为
L ( W ) = − t r ( Y T ln Y ^ ) L(W) = - \mathrm{tr} (Y^T \ln \hat{Y})
L ( W ) = − tr ( Y T ln Y ^ )
∂ L ∂ W = − X T ( Y ^ − Y ) \frac{ \partial L }{ \partial W } = - X^{T} (\hat{Y} - Y)
∂ W ∂ L = − X T ( Y ^ − Y )
其中
Y ^ = s o f t m a x ( X W ) \hat{Y} = \mathrm{softmax}(XW)
Y ^ = softmax ( X W )
将上述公式翻译为代码
1 2 3 4 5 Y_hat = fun_softmax(X @ W) l = - np.trace(Y @ np.log(Y_hat.T)) lg = X.T @ (Y_hat - Y)
再将其封装为类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 class CrossEntropyLoss (): def __init__ (self, regularization='none' , weight_decay=1 ): valid_regularizations = ['none' , 'L1' , 'L2' ] if regularization not in valid_regularizations: raise ValueError(f"Invalid regularization type. Expected one of {valid_regularizations} , but got '{regularization} '" ) self.regularization = regularization self.weight_decay = weight_decay def __call__ (self, W, X, Y ): I = np.ones((np.size(X, 0 ), 1 )) X = np.hstack((I, X)) num_classes = np.max (Y) + 1 Y = np.eye(num_classes)[Y].reshape(-1 , num_classes) Y_hat = self.__fun_softmax(X @ W) l = - np.trace(Y @ np.log(Y_hat.T)) l = l / np.size(X, 0 ) if self.regularization == 'L1' : coef = np.delete(W, 0 , axis=0 ) l = l + self.weight_decay * np.sum (np.abs (coef)) elif self.regularization == 'L2' : coef = np.delete(W, 0 , axis=0 ) l = l + self.weight_decay * np.sum (coef ** 2 ) return l def gradient (self, W, X, Y ): I = np.ones((np.size(X, 0 ), 1 )) X = np.hstack((I, X)) num_classes = np.max (Y) + 1 Y = np.eye(num_classes)[Y].reshape(-1 , num_classes) Y_hat = self.__fun_softmax(X @ W) lg = X.T @ (Y_hat - Y) lg = lg / np.size(X, 0 ) if self.regularization == 'L1' : coef = np.delete(W, 0 , axis=0 ) J = np.zeros((1 , np.size(W, 1 ))) coef = np.vstack((J, coef)) lg = lg + self.weight_decay * np.sign(coef) if self.regularization == 'L2' : coef = np.delete(W, 0 , axis=0 ) J = np.zeros((1 , np.size(W, 1 ))) coef = np.vstack((J, coef)) lg = lg + self.weight_decay * 2 * coef return lg def __fun_softmax (self, x ): if np.ndim(x) == 1 : axis = 0 else : axis = 1 x = x - np.max (x, axis=axis, keepdims=True ) return np.exp(x) / np.sum (np.exp(x), axis).reshape(-1 , 1 )
补充
关于上述softmax回归的实现,这里再补充两点,首先是关于正则化,在上文中我们讲到,L 1 L_1 L 1 L 1 L_1 L 1 L 2 L_2 L 2 L 2 L_2 L 2 softmax回归中,这种说法是错的。这是因为softmax回归中的使用的是参数矩阵,矩阵的范数计算跟向量是不一样的,而参数矩阵计算正则项与向量矩阵一样,L 1 L_1 L 1 L 2 L_2 L 2 numpy提供的linalg.norm()函数,这样计算出来的是矩阵范数,是错误的。
然后是关于计算性能,虽然将损失函数与梯度写作矩阵形式从数学上看非常的优雅,并且用代码写出来也非常简单,但是对于softmax回归来说,这里面其实有很多的性能优化空间。首先就是计算损失函数时,矩阵形式的表达式中使用了迹(trace)运算 ,这相当于Y T ln Y ^ Y^T \ln \hat{Y} Y T ln Y ^ One-Hot编码,由于One-Hot编码产生的矩阵是一个稀疏矩阵,其本身就会浪费一定的内存空间,再者,由于矩阵中多为0 0 0 r r r ln y ^ ( r ) \ln \hat{y}^{(r)} ln y ^ ( r ) y ( j ) y^{(j)} y ( j ) 0 0 0 ln y ^ ( j ) \ln \hat{y}^{(j)} ln y ^ ( j ) 0 0 0 y ( r ) y^{(r)} y ( r ) 1 1 1 ln y ^ ( r ) \ln \hat{y}^{(r)} ln y ^ ( r )
1 2 3 4 5 6 7 8 9 n = X.shape[0 ] Y_hat = fun_softmax(X @ W) correct_probs = Y_hat[np.arange(n), Y.ravel()] l = -np.sum (np.log(correct_probs)) error = Y_hat.copy() error[np.arange(n), Y.ravel()] -= 1 lg = X.T @ error
用上述实现替代原实现,完整代码为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 class CrossEntropyLossOptimization (): def __init__ (self, regularization='none' , weight_decay=1 ): valid_regularizations = ['none' , 'L1' , 'L2' ] if regularization not in valid_regularizations: raise ValueError(f"Invalid regularization type. Expected one of {valid_regularizations} , but got '{regularization} '" ) self.regularization = regularization self.weight_decay = weight_decay def __call__ (self, W, X, Y ): I = np.ones((np.size(X, 0 ), 1 )) X = np.hstack((I, X)) n = X.shape[0 ] Y_hat = self.__fun_softmax(X @ W) correct_probs = Y_hat[np.arange(n), Y.ravel()] l = -np.sum (np.log(correct_probs)) l = l / np.size(X, 0 ) if self.regularization == 'L1' : coef = np.delete(W, 0 , axis=0 ) l = l + self.weight_decay * np.sum (np.abs (coef)) elif self.regularization == 'L2' : coef = np.delete(W, 0 , axis=0 ) l = l + self.weight_decay * np.sum (coef ** 2 ) return l def gradient (self, W, X, Y ): I = np.ones((np.size(X, 0 ), 1 )) X = np.hstack((I, X)) n = X.shape[0 ] Y_hat = self.__fun_softmax(X @ W) error = Y_hat.copy() error[np.arange(n), Y.ravel()] -= 1 lg = X.T @ error lg = lg / np.size(X, 0 ) if self.regularization == 'L1' : coef = np.delete(W, 0 , axis=0 ) J = np.zeros((1 , np.size(W, 1 ))) coef = np.vstack((J, coef)) lg = lg + self.weight_decay * np.sign(coef) if self.regularization == 'L2' : coef = np.delete(W, 0 , axis=0 ) J = np.zeros((1 , np.size(W, 1 ))) coef = np.vstack((J, coef)) lg = lg + self.weight_decay * 2 * coef return lg def __fun_softmax (self, x ): if np.ndim(x) == 1 : axis = 0 else : axis = 1 x = x - np.max (x, axis=axis, keepdims=True ) return np.exp(x) / np.sum (np.exp(x), axis).reshape(-1 , 1 )
测试
最后我们来测试一下上述代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def softmax_regressor_test (W, X, y ): def fun_softmax (x ): if np.ndim(x) == 1 : axis = 0 else : axis = 1 x = x - np.max (x, axis=axis, keepdims=True ) return np.exp(x) / np.sum (np.exp(x), axis).reshape(-1 , 1 ) I = np.ones((np.size(X, 0 ), 1 )) X = np.hstack((I, X)) Y_hat = fun_softmax(X @ W) Y_hat = np.argmax(Y_hat, axis=1 ).reshape(-1 ) return np.sum (y == Y_hat) / np.size(X, 0 )
1 2 criterion = CrossEntropyLoss() W = LR_train(X, y, criterion, epochs_num=10 , batch_size=64 , alpha=0.1 )
1 2 3 4 5 6 7 8 9 10 epoch 1, loss 0.773139 epoch 2, loss 0.714879 epoch 3, loss 0.694765 epoch 4, loss 0.686554 epoch 5, loss 0.682150 epoch 6, loss 0.679736 epoch 7, loss 0.678368 epoch 8, loss 0.677144 epoch 9, loss 0.676270 epoch 10, loss 0.675807
1 softmax_regressor_test(W, X, y)
总结
本文从机器学习与深度学习的角度介绍了常用的线性回归算法,从最简单的多元线性回归出发,到引入了正则化的岭回归与Lasso回归,再到结合sigmoid函数与softmax算子实现使用线性回归模型解决分类问题。虽然,在现如今,线性回归模型只能在少数及其适合他的环境中发光发热,但是其深刻的算法思想,以及其作为神经网络基础的重要地位,使得其仍旧是广大学习者无法绕过的一环。