算法:
生成一个[0,1]上的均匀分布的随机数,再将[0,1]划分为两个区间,判断其落入哪个区间,确定其取值。
根据中心极限定理,当n足够大时,Yn∼N(np,np(1−p)),其中p=1/3,Yn/n=fn,对fn进行标准化,得
Zn=(fn−p)p(1−p)/n=(Yn−np)np(1−p)
Zn服从标准正态分布,故当n充分大时,fn的渐进分布为N∼(31,9n2)
R程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| rm(list=ls())
rng <- function(n){
xvec <- numeric(n)
for(i in 1:n){
U <- runif(1)
if(U <= 1/3){
xvec[i] <- 1
}else{
xvec[i] <- 2
}
}
xvec
}
x1 <- rng(100)
x2 <- rng(1000)
x3 <- rng(10000)
N1 <- sum(x1 == 1)/100
N2 <- sum(x2 == 1)/1000
N3 <- sum(x3 == 1)/10000
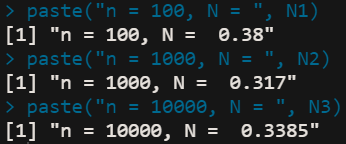
paste("n = 100, N = ", N1)
paste("n = 1000, N = ", N2)
paste("n = 10000, N = ", N3)
fn <- function(n, x){
result <- rng(n)
sum(result == x)/n
}
Central_Limit_Theorem <- function(N, n){
f_n <- replicate(N, fn(n, 1))
ks.test(f_n, "pnorm", mean = 1/3, sd = sqrt(2/(9*n)))
}
Central_Limit_Theorem(100, 100)
Central_Limit_Theorem(100, 1000)
Central_Limit_Theorem(100, 10000)
|
结果:
n=100,1000,10000的随机数X取1的百分比分别为
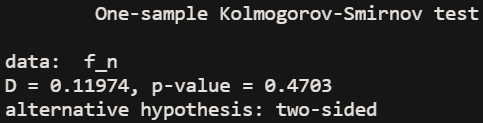
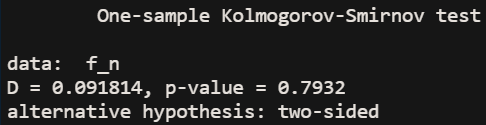
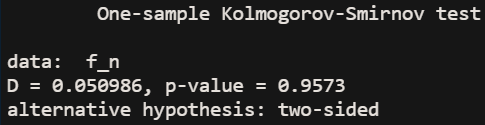
对于n=100,1000,10000,分别生成100组数据,并计算其百分比fn,再利用K-S检验,检验其是否符合渐进分布,其检验结果如下
(1)n=100
(2)n=1000
(3)n=10000

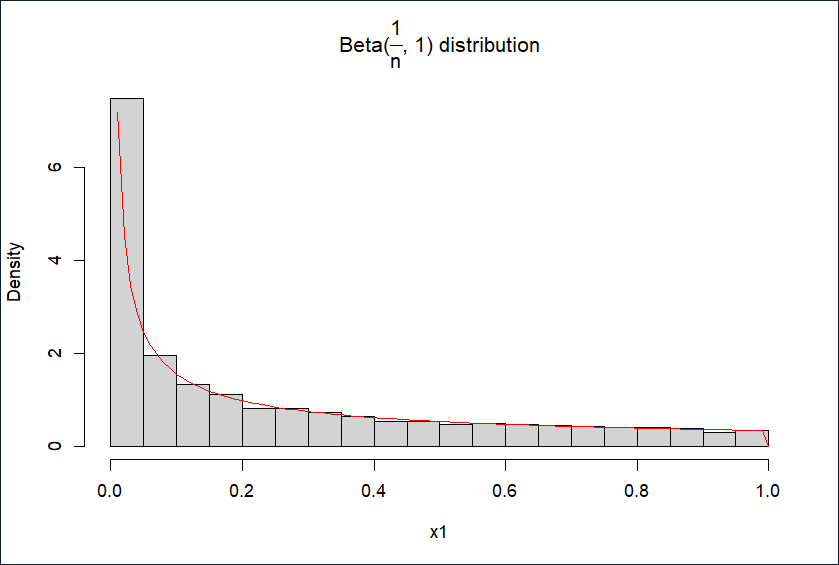
1.对分布函数p(x)=n1xn1−1,x∈[0,1]求积分,得F(x)=xn1,故反函数F−1(y)=yn
R程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
rm(list=ls())
set.seed(0721)
n <- 3
N <- 10000
rng.F1 <- function(N, n){
runif(N)^n
}
x1 <- rng.F1(N, n)
hist(x1, prob = TRUE, main = expression(paste("Beta(", frac(1,n), ", 1)", " distribution")))
curve(dbeta(x, 1/n, 1), add = TRUE, col = "red")
|
结果:
取n=3,模拟生成10000个服从Beta(n1,1)分布的随机数,直方图如下
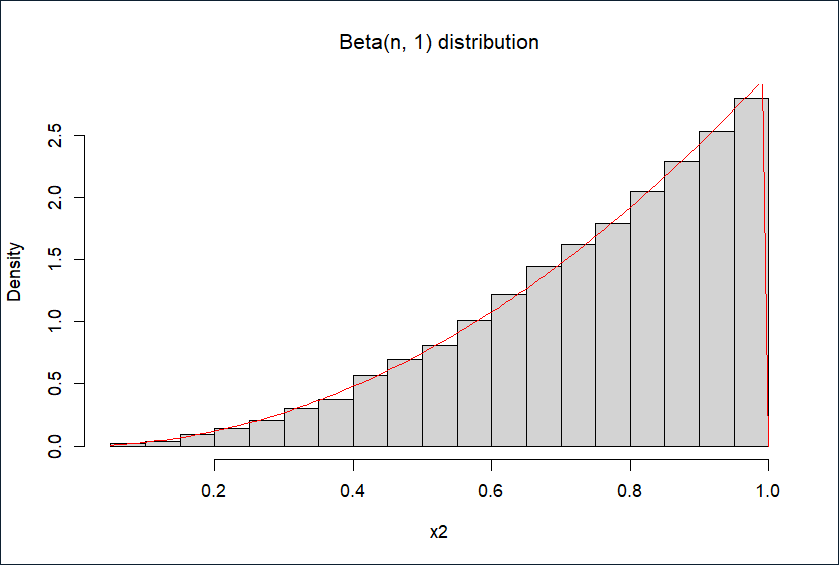
2.对分布函数p(x)=nxn−1,x∈[0,1],积分得F(x)=xn,故反函数F−1(y)=yn1
R程序:
1
2
3
4
5
6
7
8
9
10
11
12
|
n <- 3
N <- 10000
rng.F2 <- function(N, n){
runif(N)^(1/n)
}
x2 <- rng.F2(N, n)
hist(x2, prob = TRUE, main = expression(paste("Beta(n, 1)", " distribution")))
curve(dbeta(x, n, 1), add = TRUE, col = "red")
|
结果:
取n=3,模拟生成10000个服从Beta(n,1)分布的随机数,直方图如下
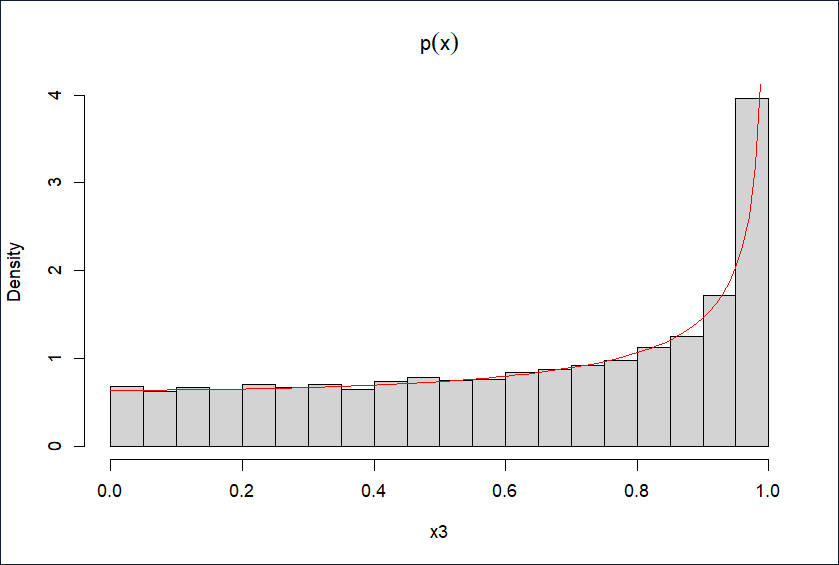
3.对分布函数p(x)=π1−x22,x∈[0,1],积分得F(x)=π2arcsinx,故反函数F−1(y)=sin(2πy)
R程序:
1
2
3
4
5
6
7
8
9
10
|
N <- 10000
rng.F3 <- function(N){
sin( pi/2*runif(N) )
}
x3 <- rng.F3(N)
hist(x3, prob = TRUE, main = expression(paste(p(x))))
curve(2/(pi*sqrt(1-x^2)), add = TRUE, col = "red")
|
结果:
模拟生成10000个服从p(x)的随机数,直方图如下
4.对分布函数p(x)=π(1+x2)1,x∈(−∞,∞),积分得F(x)=π1arctanx,故反函数F−1(y)=sin(πy)
R程序:
1
2
3
4
5
6
7
8
9
|
N <- 10000
rng.F4 <- function(N){
tan( pi*runif(N) )
}
x4 <- rng.F4(N)
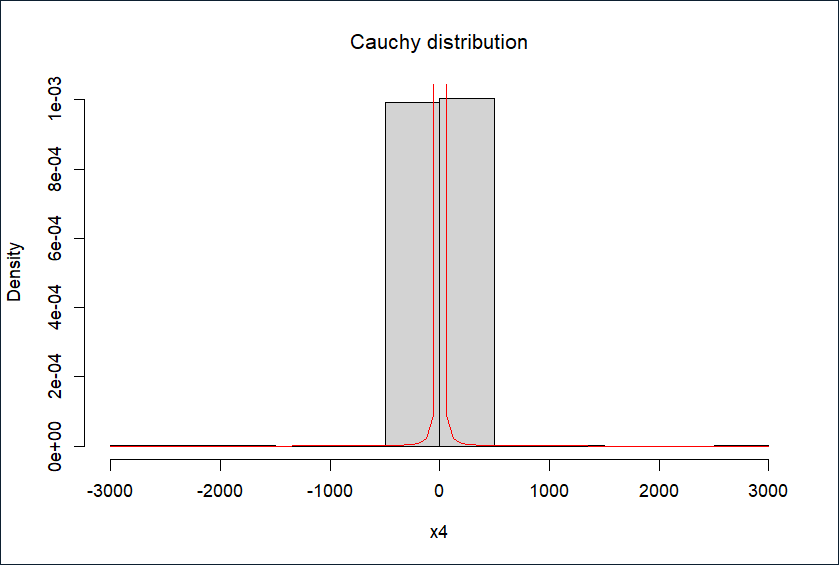
hist(x4, prob = TRUE, main = expression(paste("Cauchy distribution")))
curve(1/(pi*(1+x^2)), add = TRUE, col = "red")
|
结果:
模拟生成10000个服从柯西分布的随机数,直方图如下
5.对分布函数p(x)=cos(x),x∈[0,2π],积分得F(x)=sinx,故反函数F−1(y)=arcsiny
R程序:
1
2
3
4
5
6
7
8
9
10
|
N <- 10000
rng.F5 <- function(N){
asin( runif(N) )
}
x5 <- rng.F5(N)
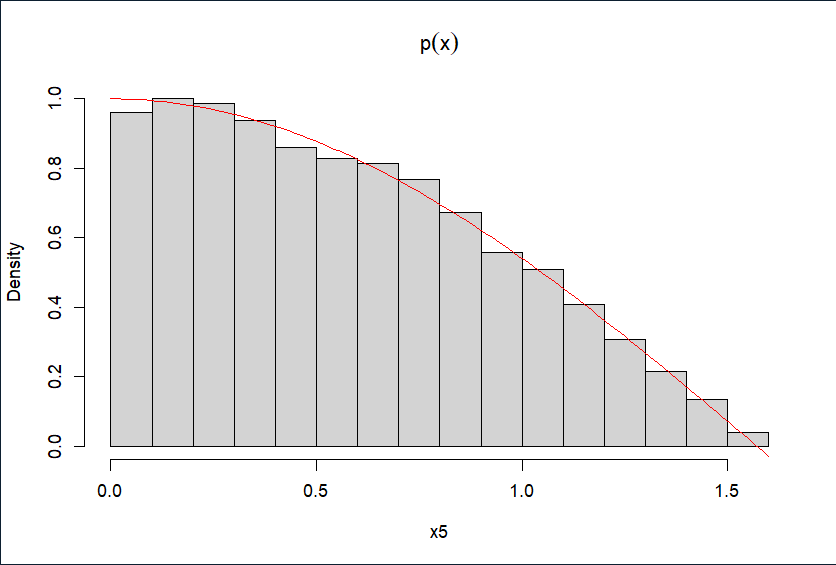
hist(x5, prob = TRUE, main = expression(paste(p(x))))
curve(cos(x), add = TRUE, col = "red")
|
结果:
模拟生成10000个服从p(x)的随机数,直方图如下
6.对分布函数p(x)=ηαxα−1e−ηxα, x>0 (α>0,η>0),积分得F(x)=1−e−ηxα,故反函数F−1(y)=[−ηln(1−y)]α1
R程序:
1
2
3
4
5
6
7
8
9
10
11
12
|
alpha <- 2
lambda <- 1
N <- 10000
rng.F6 <- function(N, alpha, lambda){
( (-1)*lambda*log(1 - runif(N)) )^(1/alpha)
}
x6 <- rng.F6(N, alpha, lambda)
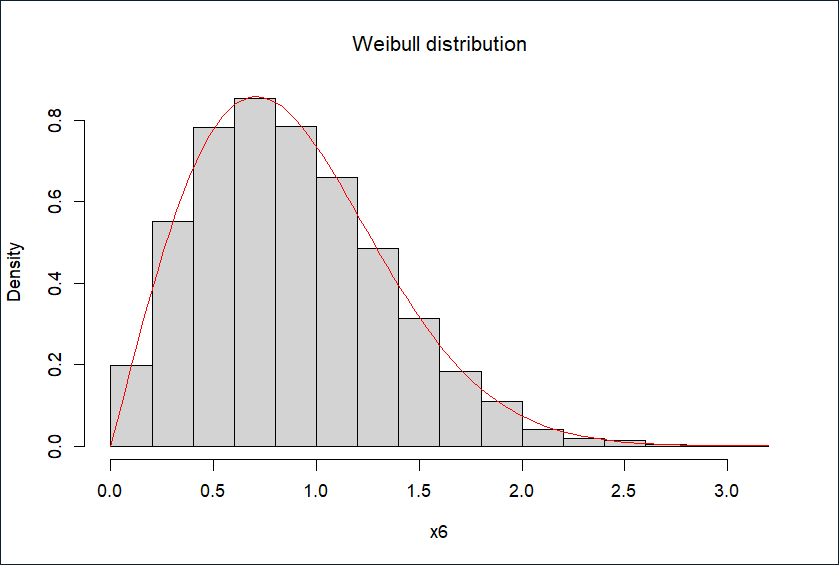
hist(x6, prob = TRUE, main = expression(paste("Weibull distribution")))
curve((alpha/lambda)*(x^(alpha-1))*exp((-1)*x^(alpha)/lambda), add = TRUE, col = "red")
|
结果:
取α=2,η=1,模拟生成10000个服从分威布尔布的随机数,直方图如下

算法:
将[0,1]区间划分为10段,生成一个服从[0,1]上的均匀分布的随机数,判断其落入哪个区间,确定其取值
R程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| rm(list=ls())
set.seed(0721)
rng <- function(x, prob) {
F <- cumsum(prob)
U1 <- runif(1)
i <- which(F > U1)[1]
X <- x[i]
return(X)
}
x <- 1:10
prob <- c(0.06, 0.06, 0.06, 0.06, 0.06, 0.15, 0.13, 0.14, 0.15, 0.13)
result <- replicate(10000, rng(x, prob))
table(result)
|
结果:

模拟生成10000个随机数,可以看出,各个取值频率基本与概率一致

算法:
1.逆变换法
对分布密度函数p(x)=21e−∣x∣, −∞<x<∞积分,得到累积密度函数
F(x)={1−21e−x,21ex,x≥0x<0
则反函数为
F−1(u)={−ln[2(1−u)],ln(2u),u≥0u<0.
2.复合法
将p(x)拆分为g1(x)=e−x,x≥0,g2(x)=ex,x<0,即p(x)=0.5∗g1(x1)+0.5∗g2(x2)。又通过逆变换法,求得g1−1(x)=−ln(2y),g2−1(x)=ln(2y),通此函数可生成g1(x),g2(x)的随机数,再设置随机数,依概率生成即可
R程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| rm(list=ls())
set.seed(0721)
N <- 10000
rng.F1 <- function(N){
U <- runif(N)
ifelse(U >= 0.5, (-1)*log(2*(1 - U)), log(2*U))
}
x1 <- rng.F1(N)
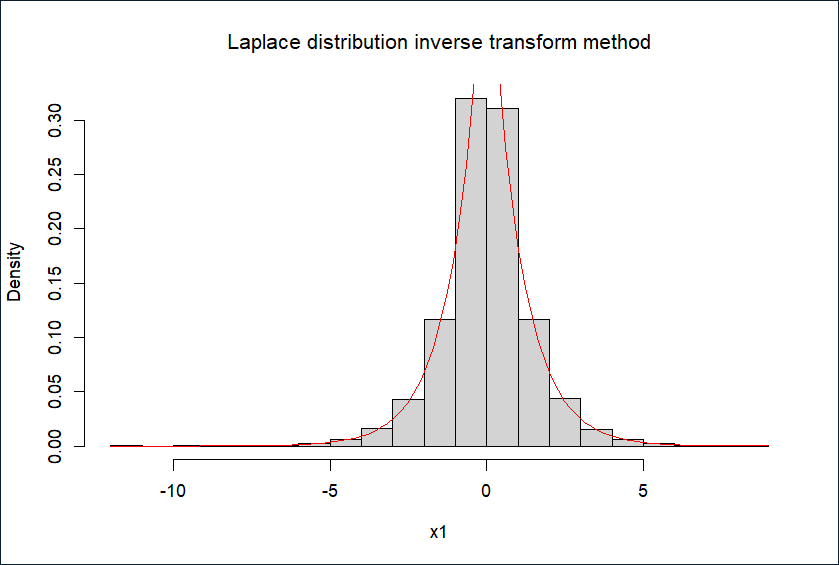
hist(x1, prob = TRUE, main = expression(paste("Laplace distribution inverse transform method")))
curve(exp(-abs(x))/2, add = TRUE, col = "red")
rng.F2 <- function(n){
xvec <- numeric(n)
for(i in 1:n){
U <- runif(1)
if(U <= 0.5){
xvec[i] <- -log(2*runif(1))
}else{
xvec[i] <- log(2*runif(1))
}
}
xvec
}
x2 <- rng.F2(N)
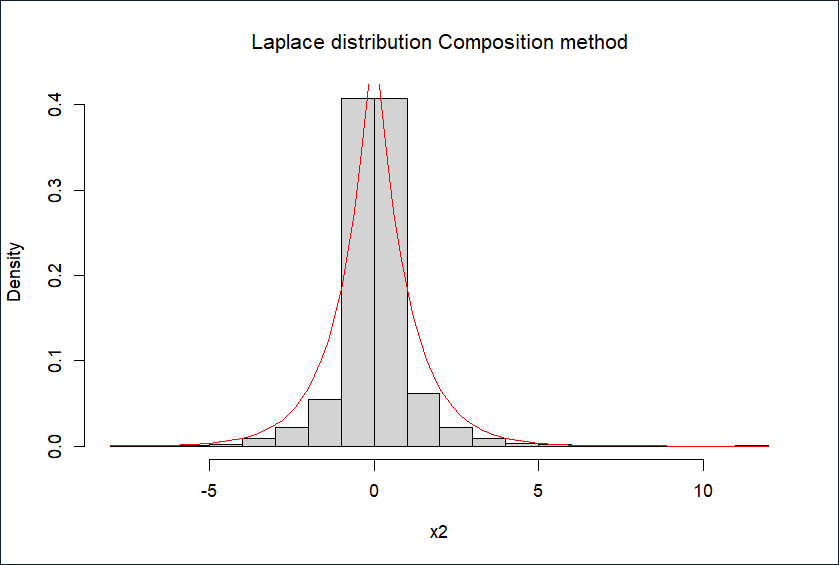
hist(x2, prob = TRUE, main = expression(paste("Laplace distribution Composition method")))
curve(exp(-abs(x))/2, add = TRUE, col = "red")
|
结果:
1.逆变换法
2.复合法
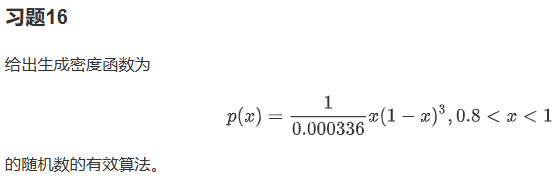
算法:
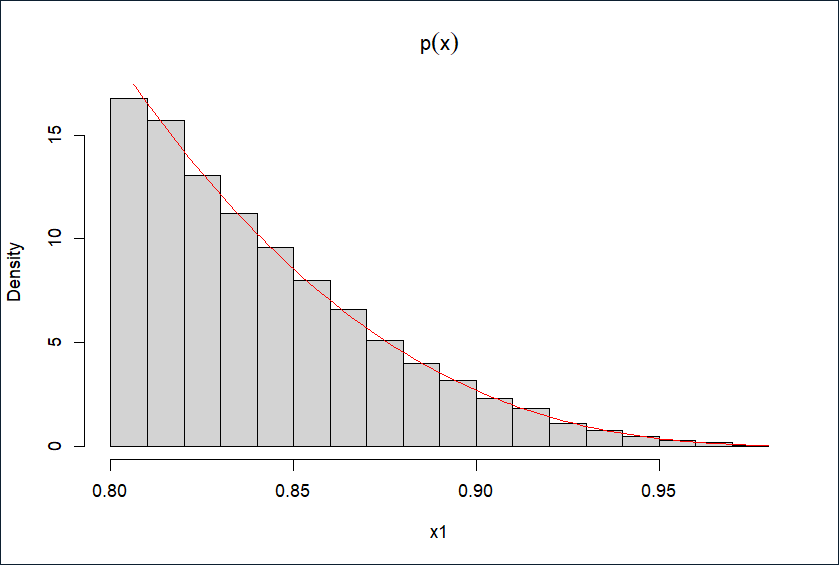
采用舍选法,根据分析,p(x)在定义域内单调递减,故最大值M=p(0,8),再根据舍选法I的算法,如下图

即可模拟得随机数
R程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| rm(list=ls())
set.seed(0721)
N <- 10000
rng.F1 <- function(n){
xvec <- numeric(n)
for(i in 1:n){
repeat{
U1 <- runif(1)
U2 <- runif(1)
X <- 0.8 + 0.2*U1
Y <- (1/0.000336)*0.8*0.2^3*U2
if(Y <= 1/0.000336*X*(1 - X)^3) break
}
xvec[i] <- X
}
xvec
}
x1 <- rng.F1(N)
hist(x1, prob = TRUE, main = expression(paste(p(x))))
curve(1/0.000336*x*(1 - x)^3, add = TRUE, col = "red")
|
结果: