一、理论阐述
中心极限定理
设随机变量X1,X2,...,Xn,...独立同分布,并存在有限的期望与方差E(Xi)=μ,D(Xi)=σ2(i=1,2,...),则对任意x,分布函数
Fn(x)=P{σn∑i=1nXi−nμ≤x}
满足
n→∞limFn(x)=n→∞limP{nσ∑i=1nXi−nμ≤x}=2π1∫−∞xe−2t2dt
中心极限定理推论
从上述定理可得,对随机变量X1,X2,...,Xn,...,存在E(Xi)=μ,D(Xi)=σ2(i=1,2,...),当n足够大时,满足
nσk=1∑nXk−nμ∼N(0,1)
由于
nσ∑k=1nXk−nμ=σ/nn1∑k=1nXk−μ=σ/nX−μ
故有
σ/nX−μ∼N(0,1),即X∼N(μ,σ2/n)
二、算法
根据上述理论,我们可以得到一个通用的中心极限定理模拟算法
-
生成N(N≫n)个随机数,将其作为后续算法抽样的集合,记为A
-
从集合A中抽取n个样本,并计算其均值,记为X1
-
将上述步骤重复k次,得到随机变量X1,X2,...,Xk
-
对上述随机变量进行检验,判断其是否符合N(μ,σ2/n)
三、R程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| rm(list=ls())
library(moments)
set.seed(0721)
Central_Limit_Theorem <- function(pop, m, n = c(1, 5, 20, 50)){
mean_pop <- mean(pop)
var_pop <- var(pop)
x_bar <- numeric(m)
par(mfrow = c(2, 4))
result <- matrix(0, nrow = 4, ncol = 7)
k <- 0
for (i in n) {
k <- k + 1
for (j in 1:m) {
x_bar[j] <- mean(sample(pop, size = i))
}
result[k, ] <- c(mean_pop, mean(x_bar), var_pop, var(x_bar), var_pop/i, skewness(x_bar), kurtosis(x_bar))
ks <- ks.test(x_bar, "pnorm", mean = mean (x_bar), sd = sd (x_bar))
hist(x_bar, freq = FALSE, main = paste("n =", i), xlab = "Sample mean")
curve(dnorm(x, mean = mean(x_bar), sd = sd(x_bar)), add = TRUE, col = "red")
qqnorm (x_bar, main = paste("p.value =", round(ks$p.value, 3)))
qqline (x_bar)
}
M <- data.frame(mean_X = c(result[, 1]), x_mean = c(result[, 2]), var_X = c(result[, 3]), x_var = c(result[, 4]), var_X_n = c(result[, 5]), skewness = result[, 6], kurtosis = result[, 7])
return(M)
}
pop <- rnorm(10000, mean = 0, sd = 1)
M <- Central_Limit_Theorem(pop, 1000, c(1, 5, 10, 30))
pop <- rexp(10000, rate = 1)
M <- Central_Limit_Theorem(pop, 1000)
pop <- runif(10000, min = 0, max = 1)
M <- Central_Limit_Theorem(pop, 1000)
pop <- rpois(10000, lambda = 1)
M <- Central_Limit_Theorem(pop, 1000, c(1, 10, 30, 70))
pop <- rbinom(10000, size = 10, prob = 0.5)
M <- Central_Limit_Theorem(pop, 1000)
pop <- sample(c(-1, 1), size = 10000, replace = TRUE)
M <- Central_Limit_Theorem(pop, 1000, c(1, 30, 100, 200))
|
四、结果分析
分析方法
对于各个分布,每次抽样取n个样本用于计算均值,共取1000次,对于每个分布分别取4个不同的n值进行模拟,并各自进行检验,检验方法如下:
- 直方图与核密度估计曲线
- Q-Q图
- K-S检验,检验其是否符合理论上的正态分布(p值绘制于Q-Q图上方)
- 描述性统计,包括分布均值方差,理论方差,样本的均值,方差
正态分布
直方图,Q-Q图与K-S检验结果
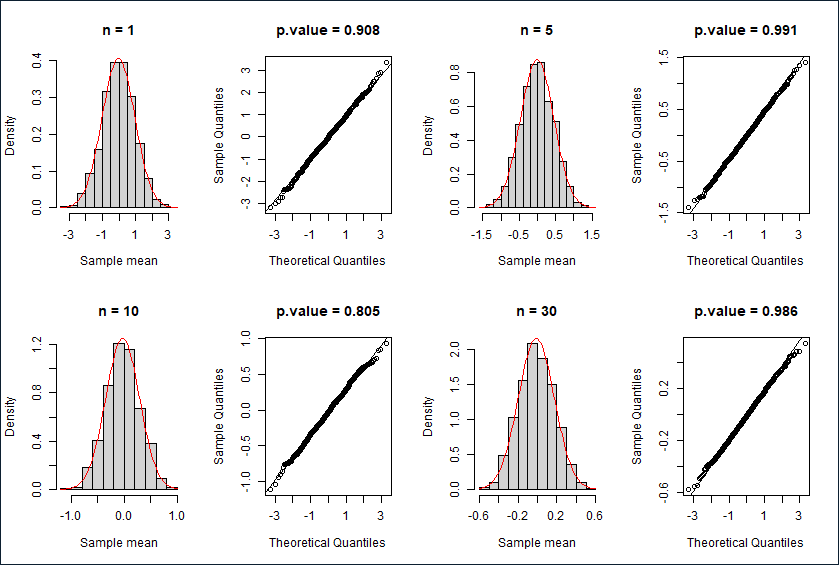
描述性统计
| n |
原分布均值 |
样本均值 |
原分布方差 |
样本方差 |
理论样本方差 |
| 1 |
-0.0186 |
-0.0293 |
0.9902 |
0.9663 |
0.9902 |
| 5 |
-0.0186 |
-0.0092 |
0.9902 |
0.2081 |
0.198 |
| 10 |
-0.0186 |
-0.0313 |
0.9902 |
0.1015 |
0.099 |
| 30 |
-0.0186 |
-0.0125 |
0.9902 |
0.0343 |
0.033 |
指数分布
直方图,Q-Q图与K-S检验结果
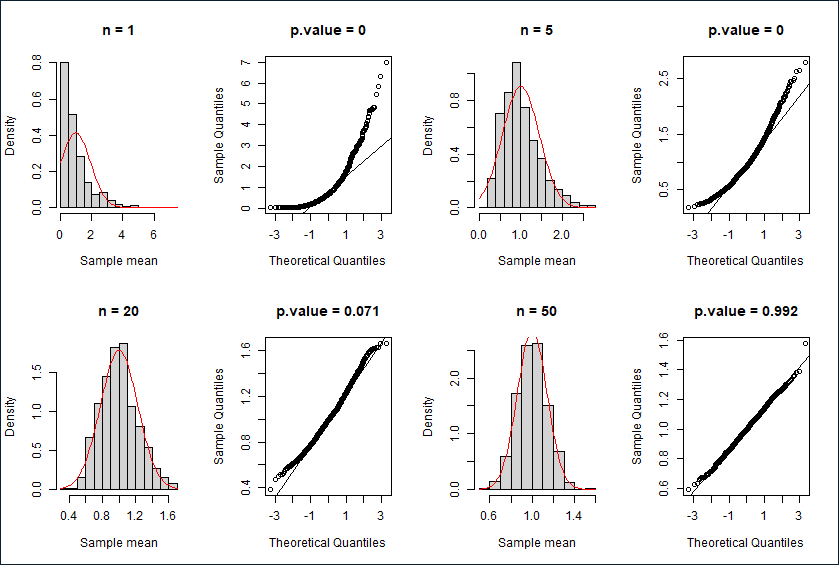
描述性统计
| n |
原分布均值 |
样本均值 |
原分布方差 |
样本方差 |
理论样本方差 |
| 1 |
0.9998 |
0.9586 |
0.9822 |
0.9291 |
0.9822 |
| 5 |
0.9998 |
1.0008 |
0.9822 |
0.1954 |
0.1964 |
| 20 |
0.9998 |
1.0013 |
0.9822 |
0.0503 |
0.0491 |
| 50 |
0.9998 |
1.0002 |
0.9822 |
0.0195 |
0.0196 |
均匀分布
直方图,Q-Q图与K-S检验结果
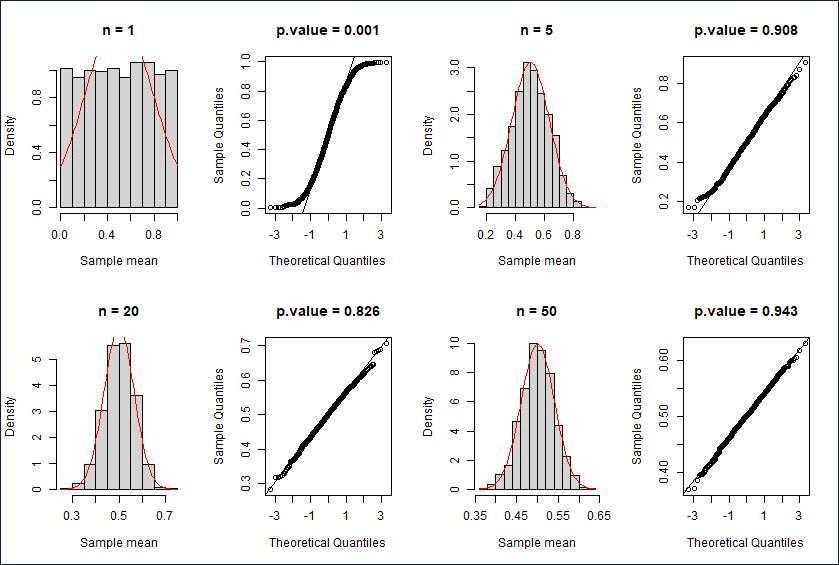
描述性统计
| n |
原分布均值 |
样本均值 |
原分布方差 |
样本方差 |
理论样本方差 |
| 1 |
0.5001 |
0.5018 |
0.0842 |
0.0831 |
0.0842 |
| 5 |
0.5001 |
0.5026 |
0.0842 |
0.0165 |
0.0168 |
| 20 |
0.5001 |
0.5004 |
0.0842 |
0.0041 |
0.0042 |
| 50 |
0.5001 |
0.5007 |
0.0842 |
0.0016 |
0.0017 |
泊松分布
直方图,Q-Q图与K-S检验结果
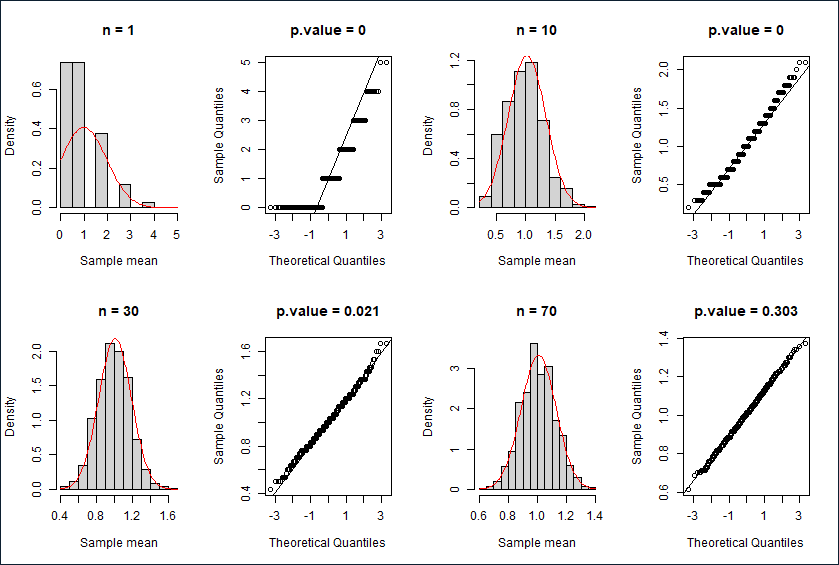
描述性统计
| n |
原分布均值 |
样本均值 |
原分布方差 |
样本方差 |
理论样本方差 |
| 1 |
1.0137 |
0.992 |
1.0192 |
0.9609 |
1.0192 |
| 10 |
1.0137 |
1.0205 |
1.0192 |
0.1041 |
0.1019 |
| 30 |
1.0137 |
1.0062 |
1.0192 |
0.0334 |
0.034 |
| 70 |
1.0137 |
1.0077 |
1.0192 |
0.0143 |
0.0146 |
二项分布
直方图,Q-Q图与K-S检验结果
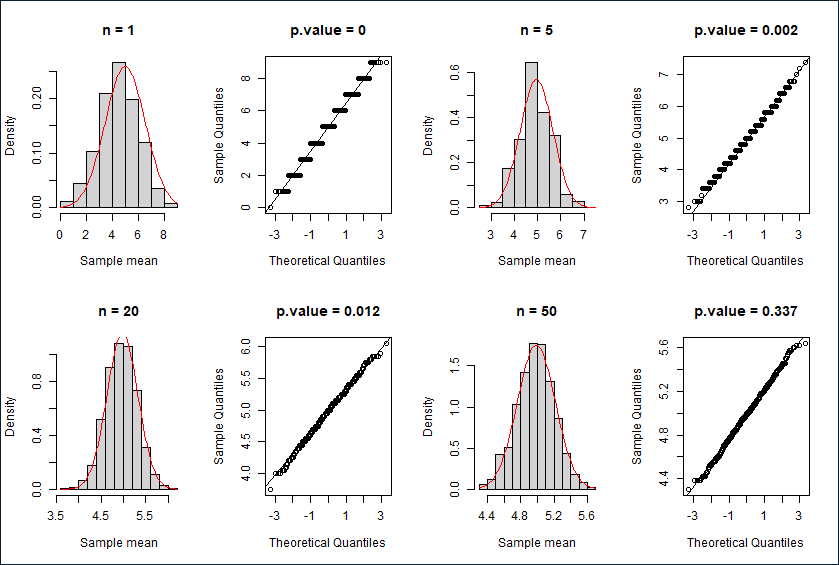
描述性统计
| n |
原分布均值 |
样本均值 |
原分布方差 |
样本方差 |
理论样本方差 |
| 1 |
4.9825 |
4.981 |
2.4702 |
2.379 |
2.4702 |
| 5 |
4.9825 |
4.9592 |
2.4702 |
0.4893 |
0.494 |
| 20 |
4.9825 |
4.977 |
2.4702 |
0.1198 |
0.1235 |
| 50 |
4.9825 |
4.9865 |
2.4702 |
0.0519 |
0.0494 |
两点分布
直方图,Q-Q图与K-S检验结果
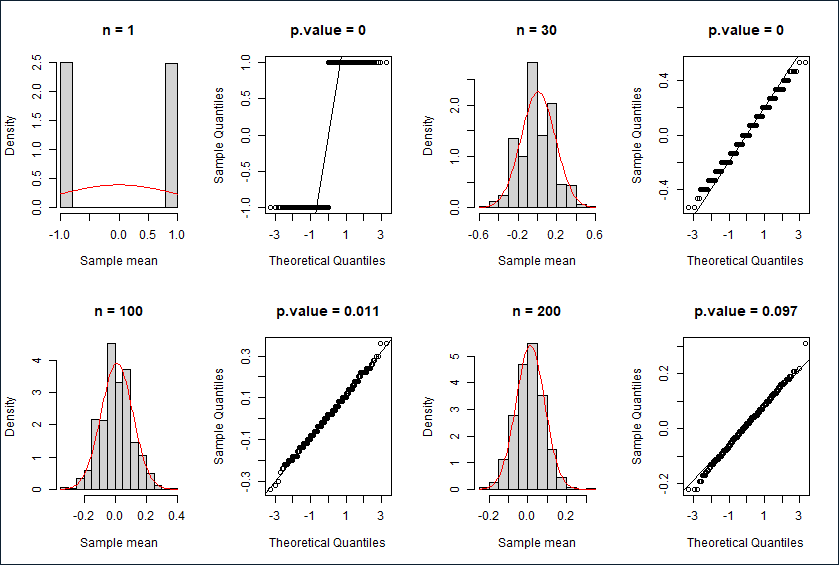
描述性统计
| n |
原分布均值 |
样本均值 |
原分布方差 |
样本方差 |
理论样本方差 |
| 1 |
0.0146 |
-0.006 |
0.9999 |
1.001 |
0.9999 |
| 30 |
0.0146 |
0.0073 |
0.9999 |
0.0311 |
0.0333 |
| 100 |
0.0146 |
0.0119 |
0.9999 |
0.0104 |
0.01 |
| 200 |
0.0146 |
0.0132 |
0.9999 |
0.0054 |
0.005 |
总结
从上述结果来看,随着n的增大,各个样本会越来越趋近于正态分布,从直方图与核密度估计曲线可以看到直方图与曲线越来越接近,而且Q-Q图上的点也逐渐分布于参考线上,且在n值足够大时,所有的分布均可以通过K-S检验。而从描述性统计中可以看出,随着n的增大,样本的均值越来越接近分布均值,方差也越来越接近理论方差。





