前言
感知机可以说是一个跨越了人工智能发展历史的模型,其提出之时引起了非常大的关注,但是随后,大家很快发现其存在严重的局限性,这也导致了AI的第一次寒冬。而经过十几年的停滞,多层感知机的出现解决了感知机存在的问题,并且至今仍在被广泛应用,甚至许多前沿的模型架构中都不乏MLP的身影,这也使得感知机成为了学习深度学习一定绕不开的模型,许多经典的深度学习课程与教材都会将感知机作为第一个模型讲解。本文将顺着感知机的发展历史,讲到目前被广泛使用的多层感知机,并介绍与此相关的一些问题,以及相关的一些技术。
注:本文会涉及到梯度下降与线性回归模型的部分内容,对此不了解的读者可以移步本站的梯度下降博客 以及线性回归模型博客 。
感知机的发展历史
神经元模型
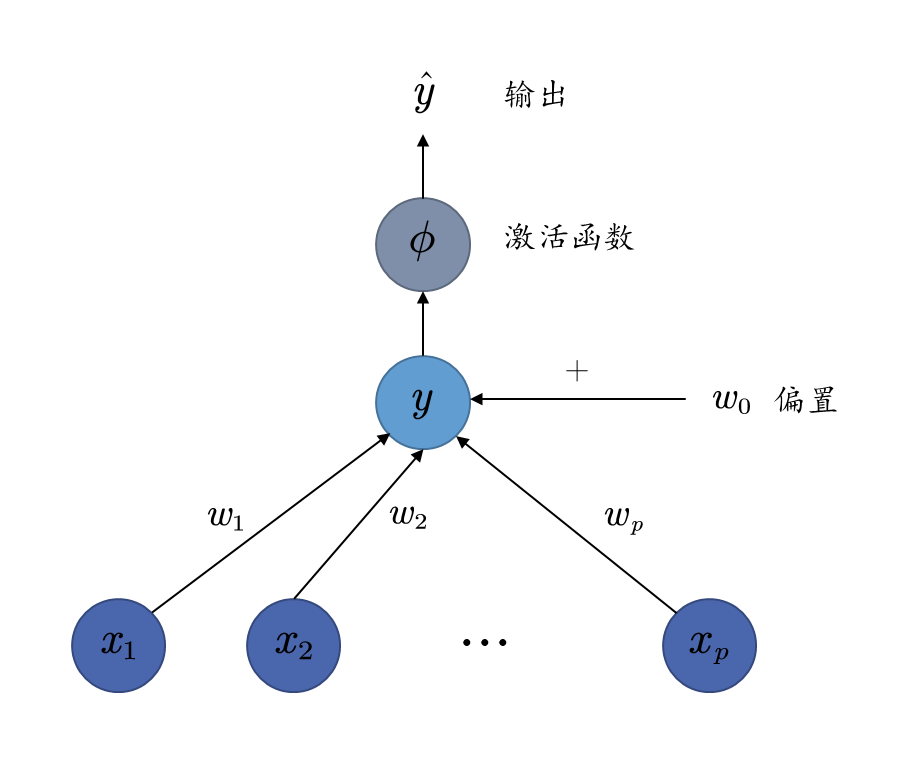
1943年,心理学家McCulloch和数学家Pitts根据生物神经元的结构,提出了MP神经元模型,模型结构如下图
简单来说就是人类的神经元会接受其他神经元的信号,当信号强度超过某一个阈值之后,该神经元被激活。从数学上模拟这个过程就是,多个输入x 1 , x 2 , ⋯ , x p x_1, x_2, \cdots, x_p x 1 , x 2 , ⋯ , x p x > 0 x > 0 x > 0 1 1 1 − 1 -1 − 1 激活函数 。整个模型写出来就是
y = ϕ ( w 0 + w 1 x 1 + ⋯ + w p x p ) ϕ ( x ) = { 1 x ≥ 0 − 1 x < 0 y = \phi(w_0 + w_1 x_1 + \cdots + w_p x_p) \\
\phi(x) =
\begin{cases}
1 & x \ge 0 \\
-1 & x < 0 \\
\end{cases}
y = ϕ ( w 0 + w 1 x 1 + ⋯ + w p x p ) ϕ ( x ) = { 1 − 1 x ≥ 0 x < 0
由于模型只有一个输出,且激活函数会将输出从连续值映射到{ − 1 , 1 } \{-1, 1\} { − 1 , 1 } logistic回归 中使用sigmoid函数 将连续值映射到( 0 , 1 ) (0, 1) ( 0 , 1 )
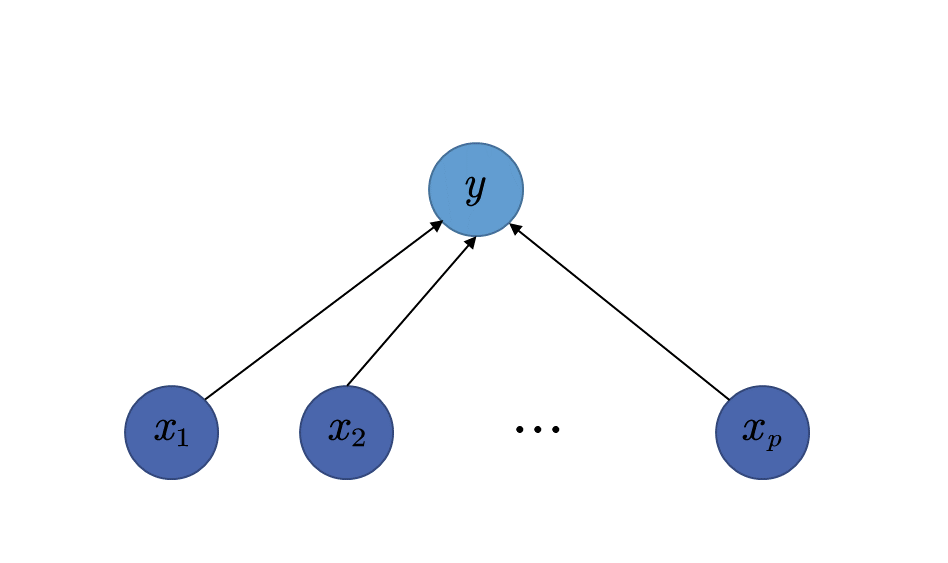
最后,上面的模型结构图是详细版本,后续的模型随着结构的复杂化,一般都会省略偏置以及损失函数,如下图
感知机模型
在神经元模型的基础上,Frank Roseblatt于1957年提出感知机模型,其模型结构与神经元模型完全相同 。
此时大家可能会疑惑,模型结构完全不变,这也能算提出一个新模型?其实不然,感知机的贡献在于其给出了一套机器自主学习参数的算法。生活在机器学习与深度学习盛行年代的我们,可能会先入为主的认为模型自主学习参数是一件很平常的事情,但这种操作最早就是由感知机模型提出的,我们来看看当年感知机模型所设计的算法。
感知机的训练方法为,首先初始化 所有参数为0 0 0 ( x 1 , x 2 , ⋯ , x p , y ) (x_1, x_2, \cdots, x_p, y) ( x 1 , x 2 , ⋯ , x p , y ) y ^ \hat{y} y ^ y y ^ ≤ 0 y\hat{y} \le 0 y y ^ ≤ 0
w i ← w i − y ^ x i i = 1 , 2 , ⋯ , p w 0 ← w 0 − y ^ w_i \gets w_i - \hat{y} x_i \quad i = 1, 2, \cdots, p \\
w_0 \gets w_0 - \hat{y}
w i ← w i − y ^ x i i = 1 , 2 , ⋯ , p w 0 ← w 0 − y ^
否则不更新参数,循环往复。
这个训练方法的想法也很简单,首先,如果预测值是正确的,那么不更新参数,如果预测值是错误的,例如正确值为1 1 1 − 1 -1 − 1 w 0 + w 1 x 1 + ⋯ + w p x p w_0 + w_1 x_1 + \cdots + w_p x_p w 0 + w 1 x 1 + ⋯ + w p x p 1 1 1 w 0 + w 1 x 1 + ⋯ + w p x p w_0 + w_1 x_1 + \cdots + w_p x_p w 0 + w 1 x 1 + ⋯ + w p x p w 0 + w 1 x 1 + ⋯ + w p x p w_0 + w_1 x_1 + \cdots + w_p x_p w 0 + w 1 x 1 + ⋯ + w p x p w i x i w_i x_i w i x i w 0 w_0 w 0 w 0 w_0 w 0 w i w_i w i x i x_i x i w i x i w_i x_i w i x i
看完感知机的训练算法,大家可能又会疑惑,模型训练不应该是先选个损失函数,再求解损失函数的最小值吗?而且这个算法怎么看着总有一种梯度下降的既视感?这又是生活在现在的我们先入为主了,在当时是没有把模型训练转化为求解损失函数最小值这种想法的,从算法的设计思路也可以看出来,作者当时就是从结果倒推设计出的这套算法。而看着像梯度下降其实是没错的,从我们现在的角度来看,感知机的这套训练算法等价于定义损失函数 为L ( w ) = m a x ( 0 , − y y ^ ) L(\boldsymbol{w}) = \mathrm{max}(0, -y\hat{y}) L ( w ) = max ( 0 , − y y ^ ) 随机梯度下降 进行优化。
XOR问题
可以进行自主学习的感知机在当时引起了大量关注,不少人因此认为人工智能时代要来了。但是,1969年,Marvin Minsky和Seymour Papert在《Perceptrons》一书中指出,感知机无法解决线性不可分问题 ,例如XOR问题,即异或问题。XOR问题非常简单,假设有两个输入x 1 x_1 x 1 x 2 x_2 x 2
x 1 x_1 x 1 x 2 x_2 x 2 y y y
+ + + + + + 1 1 1
+ + + − - − − 1 -1 − 1
− - − + + + − 1 -1 − 1
− - − − - − 1 1 1
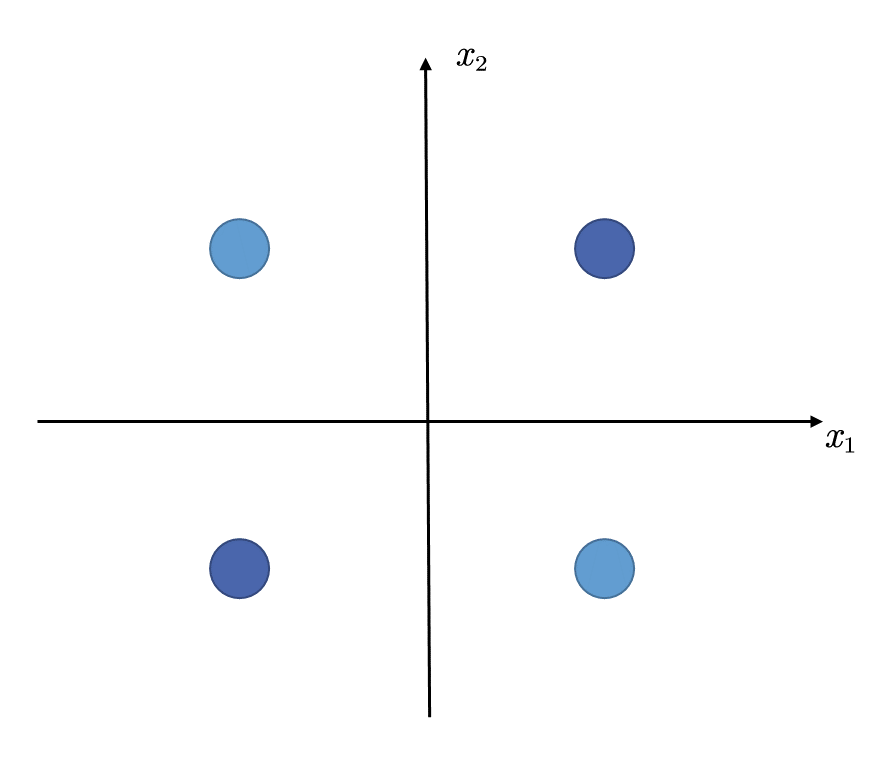
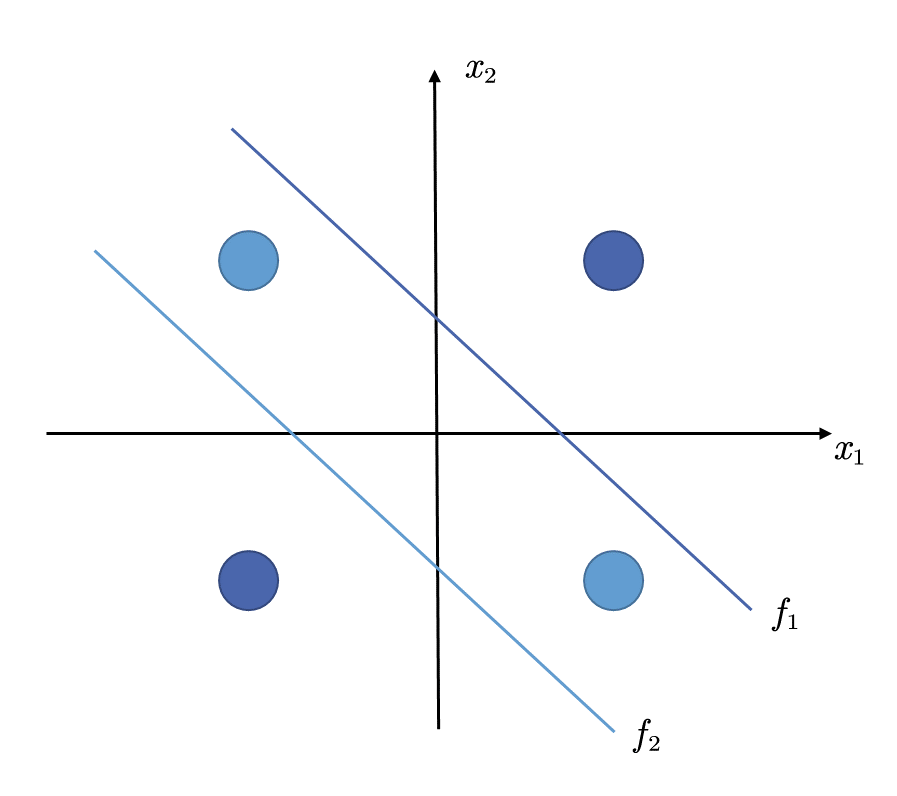
一个最简单的XOR数据集只包含四个样本,如下图
其中,不同颜色代表不同类别。现在,我们需要训练一个感知机模型,用于将这四个样本分开。但是,这是做不到的,因为感知机模型本质上还是一个线性模型,因此,这个问题就相当于,找到一条直线,将上图中的四个点分开,很显然这是无法做到的。
XOR问题的解决思路
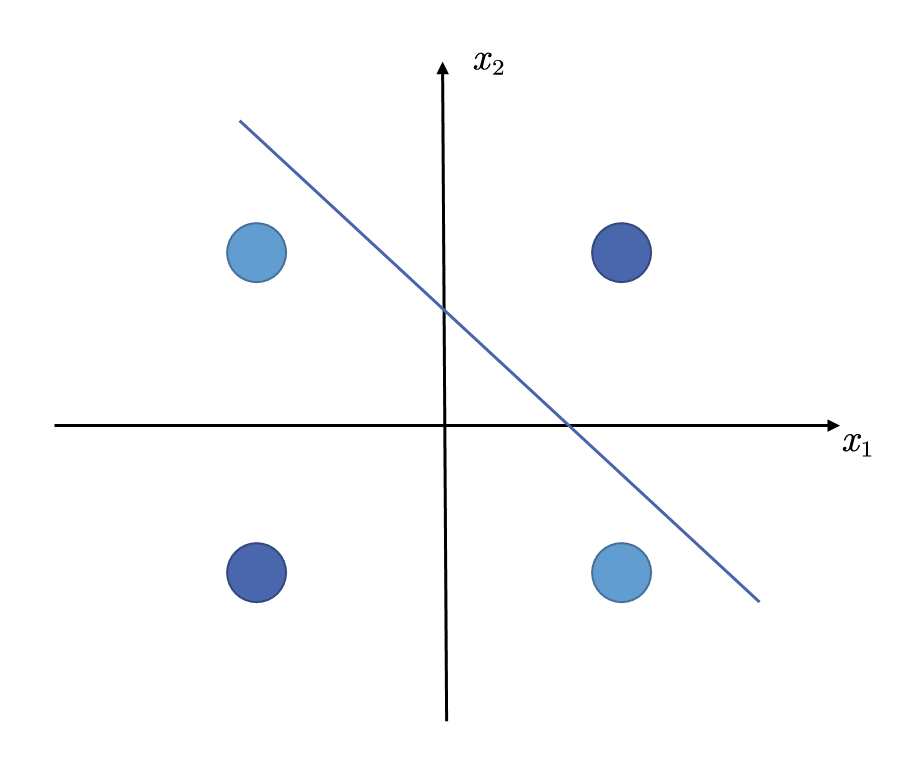
历史的车轮滚滚向前,在感知机模型被冷落了十几年之后,19世纪80年代,XOR问题也迎来了解决方法。思路很简单,既然一条直线无法将四个点分开,那么就用两个
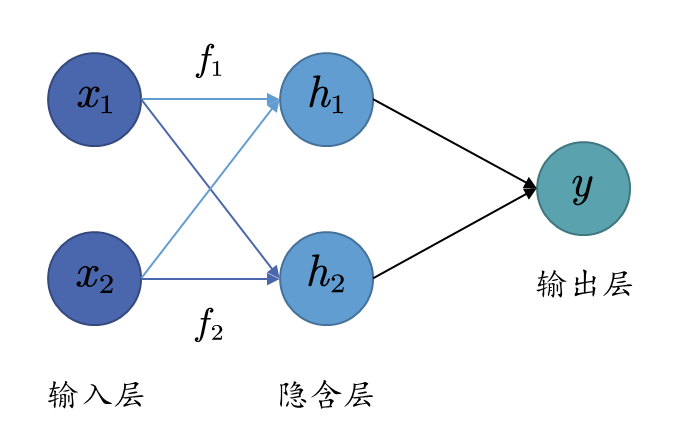
如上图,如果我们有两个线性模型,那么就可以将XOR问题的四个样本完美的分开。我们来详细看看其决策过程,输入样本( x 1 , x 2 ) (x_1, x_2) ( x 1 , x 2 ) f 1 f_1 f 1 f 2 f_2 f 2 1 1 1 f 1 f_1 f 1 f 2 f_2 f 2 − 1 -1 − 1 f 1 f_1 f 1 f 2 f_2 f 2 整合f 1 f_1 f 1 f 2 f_2 f 2 ,得到分类结果。因此,我们就得到了下面的模型结构
构建两个线性模型f 1 f_1 f 1 f 2 f_2 f 2 h 1 h_1 h 1 h 2 h_2 h 2 y y y 隐含层 ,而引入了隐含层的感知机就被称为多层感知机 。
注:XOR问题只是线性不可分问题中的一个代表,因为其足够简单,只要能够解决XOR问题,那么其他的线性不可分问题也可以被解决。例如,对于多层感知机来说,通过增加隐含层的神经元数量,就可以解决更复杂的线性不可分问题。
多层感知机
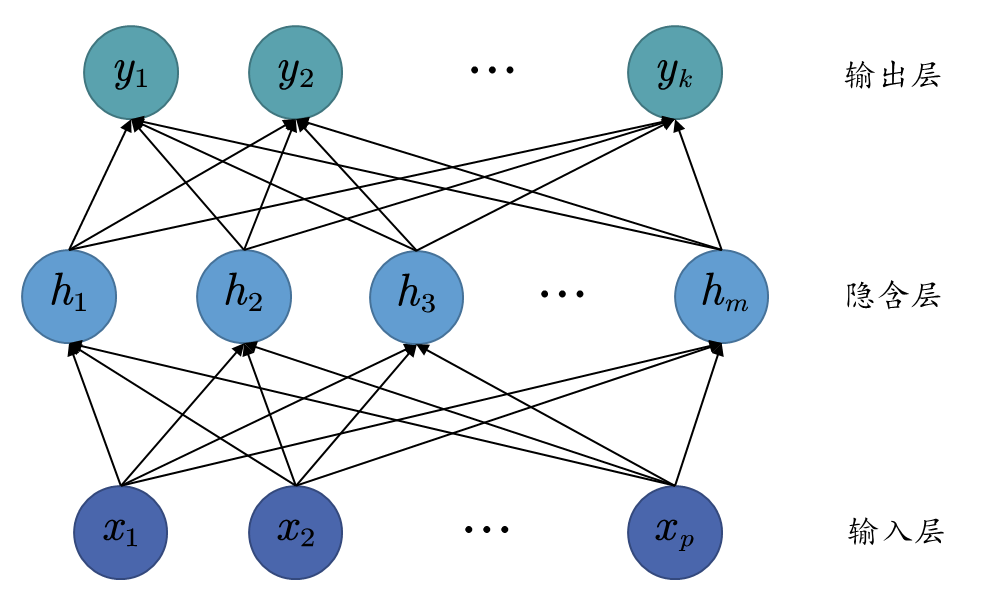
感知机的发展历史就先告有一段落,现在我们来详细看看多层感知机 (Multi-Layer Perceptron,MLP)模型,模型结构如下图
其中,输入层的节点数由数据的特征数决定,输出层的节点数由具体的问题类型决定,而隐含层的层数与每层的节点数均为超参数 ,一般均为人为设定。跟上文感知机的模型结构图相同,每一条连接线均代表一个可以学习的参数,且上述结构图中省略了偏置与损失函数。
注1:关于隐含层超参数的设定,初学者常常会困惑:隐含层的神经元数量为什么是256 256 256 2 2 2 128 128 128 256 256 256 100 100 100 10 10 10 128 128 128 64 64 64 32 32 32
注2:多层感知机还有很多名字,例如前馈神经网络(Feedforward Neural Network,FNN) ,在神经网络中常常被叫做全连接层,稠密层,线性层,英文中会叫dense layer,大家基本都是按习惯叫法来,在各种资料中看到这些名称的时候知道跟MLP是一个东西就可以了。
注3:感知机模型扩展至多分类 问题的方法与softmax回归 是一样的OvR策略 ,将多层感知机的最后一层隐含层到输出层看作是一个softmax回归就很显然了。
激活函数的作用
在感知机模型以及logistic回归中,损失函数的作用是,在处理分类问题中,将连续值映射为离散值或概率值。而在多层感知机中,对于新引入的隐含层,是否需要使用损失函数?为什么要使用损失函数?这是我们这一小节要讲的问题。
先说结论,在多层感知机中,每一层隐含层都必须使用损失函数 。至于原因,我们可以反过来想,如果隐含层不使用损失函数会带来什么问题?就用上面所展示的单隐含层的多层感知机,记x = ( x 1 , x 2 , ⋯ , x p ) T \boldsymbol{x} = (x_1, x_2, \cdots, x_p)^T x = ( x 1 , x 2 , ⋯ , x p ) T h = ( h 1 , h 2 , ⋯ , y m ) T \boldsymbol{h} = (h_1, h_2, \cdots, y_m)^T h = ( h 1 , h 2 , ⋯ , y m ) T y = ( y 1 , y 2 , ⋯ , y k ) T \boldsymbol{y} = (y_1, y_2, \cdots, y_k)^T y = ( y 1 , y 2 , ⋯ , y k ) T W ( 1 ) W^{(1)} W ( 1 ) m × p m \times p m × p w 0 ( 1 ) \boldsymbol{w_{0}^{(1)}} w 0 ( 1 ) m × 1 m \times 1 m × 1 W ( 2 ) W^{(2)} W ( 2 ) k × m k \times m k × m w 0 ( 2 ) \boldsymbol{w_{0}^{(2)}} w 0 ( 2 ) k × 1 k \times 1 k × 1
h = W ( 1 ) x + w 0 ( 1 ) y = W ( 2 ) h + w 0 ( 2 ) \boldsymbol{h} = W^{(1)} \boldsymbol{x} + \boldsymbol{w_{0}^{(1)}} \\
\boldsymbol{y} = W^{(2)} \boldsymbol{h} + \boldsymbol{w_{0}^{(2)}}
h = W ( 1 ) x + w 0 ( 1 ) y = W ( 2 ) h + w 0 ( 2 )
将上式代入下式可以得到
y = W ( 2 ) ( W ( 1 ) x + w 0 ( 1 ) ) + w 0 ( 2 ) = W ( 2 ) W ( 1 ) x + ( W ( 2 ) w 0 ( 1 ) + w 0 ( 2 ) ) \boldsymbol{y} = W^{(2)} (W^{(1)} \boldsymbol{x} + \boldsymbol{w_{0}^{(1)}}) + \boldsymbol{w_{0}^{(2)}} = W^{(2)} W^{(1)} \boldsymbol{x} + (W^{(2)} \boldsymbol{w_{0}^{(1)}} + \boldsymbol{w_{0}^{(2)}})
y = W ( 2 ) ( W ( 1 ) x + w 0 ( 1 ) ) + w 0 ( 2 ) = W ( 2 ) W ( 1 ) x + ( W ( 2 ) w 0 ( 1 ) + w 0 ( 2 ) )
不难发现,即使添加了隐含层,拟合出的模型依旧是一个线性模型,权重为W ( 2 ) W ( 1 ) W^{(2)} W^{(1)} W ( 2 ) W ( 1 ) W ( 2 ) w 0 ( 1 ) + w 0 ( 2 ) W^{(2)} \boldsymbol{w_{0}^{(1)}} + \boldsymbol{w_{0}^{(2)}} W ( 2 ) w 0 ( 1 ) + w 0 ( 2 )
到这里,我们就可以引出损失函数的另一个作用,为模型增加非线性性 。由于单层的感知机是一个线性模型,无法解决线性不可分问题,因此我们选择使用添加隐含层的方法来解决,但是隐含层本身并不具有非线性性,所以隐含层需要使用激活函数来为提供非线性性,隐含层不使用激活函数的多层感知机会退化为单层感知机 。
常用激活函数
现在,让我们来总结一下损失函数的作用,第一,在输出层中将连续值映射为离散值或概率值,第二,在隐含层中为模型提供非线性变换。基于此,我们可以得到损失函数需要满足的几个条件
非线性函数
连续可导,但也允许在少数点上不可导
函数尽可能简单
导函数值域在一个合适的区间内,不可过大也不可过小
上述条件中,前两个条件很好理解,用于提供非线性性的函数肯定是非线性的,而连续可导是为了方便模型使用梯度下降进行训练。至于后两个条件,在后文我们会详细讲到,现在,让我们来看几个最常见的损失函数。
sigmoid函数
首先是sigmoid函数,就是logistic回归中使用的激活函数,其表达式为
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}}
σ ( x ) = 1 + e − x 1
这也是最经典的损失函数,满足了上述的所有要求,既可以用在隐含层也可以用在输出层,早期的神经网络模型基本均使用sigmoid函数作为损失函数,不过随着技术的发展,现在也逐渐被淘汰了,只会在二分类问题的输出层有所出场。
注:至于softmax函数,基本是为了输出层量身定制的,并不能用在隐含层上,一般做多分类问题的话,输出层就使用softmax函数,这里就顺带提一句了。
tanh函数
然后是tanh函数,这是一个反三角函数,其表达式为
t a n h ( x ) = e x − e − x e x + e − x \mathrm{tanh}(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}
tanh ( x ) = e x + e − x e x − e − x
tanh函数可以看作放大并平移的sigmoid函数,由于其值域为( − 1 , 1 ) (-1, 1) ( − 1 , 1 )
ReLU函数
最后是ReLU(Rectified Linear Unit)函数,也被称为线性整流函数,这是目前使用最广泛的损失函数,没有之一 。其表达式为
R e L U ( x ) = { x x ≥ 0 0 x < 0 = m a x ( 0 , x ) \mathrm{ReLU}(x) =
\begin{cases}
x & x \ge 0 \\
0 & x < 0 \\
\end{cases} \\
= \mathrm{max}(0, x)
ReLU ( x ) = { x 0 x ≥ 0 x < 0 = max ( 0 , x )
这是一个非常简单的分段函数,而且在x = 0 x = 0 x = 0 用ReLU函数效果就是好 ,就这么简单,深度学习很多时候就是这样的。至于效果好的原因,目前普遍认为是因为其x ≥ 0 x \ge 0 x ≥ 0 1 1 1 x < 0 x < 0 x < 0 0 0 0
注:其实还有大量的基于上述三个损失函数的变体,但是就笔者的个人经历来说,这些变体都属于只在书本上见过,从来没有在实际中用过,因此这里就不讲了,感兴趣的读者可以自行搜索学习。
损失函数与优化算法
最后,就是多层感知机的训练了,到了多层感知机的年代,已经有了将把模型训练转化为求解损失函数最小值的思路了,所以多层感知机的训练与求解线性回归的数值解 使用的算法并无二致。
在损失函数的选用上,对于回归问题选用均方误差损失函数(MSE),表达式为
L ( W ) = ∑ i = 1 n ( y i − y ^ ) 2 L(W) = \sum_{i=1}^{n} (y_i - \hat{y})^2
L ( W ) = i = 1 ∑ n ( y i − y ^ ) 2
对于分类问题选用交叉熵损失函数,表达式为
L ( W ) = − ∑ i = 1 n ∑ j = 1 m y i ( j ) l n y ^ i ( j ) L(W)
= - \sum_{i=1}^{n} \sum_{j=1}^{m} {y}_{i}^{(j)} \mathrm{ln} {\hat{y}}_{i}^{(j)}
L ( W ) = − i = 1 ∑ n j = 1 ∑ m y i ( j ) ln y ^ i ( j )
在优化算法的选择上,均选用梯度下降算法及其变体。
补充:反向传播算法
注:反向传播算法母庸置疑是一个非常重要的算法,但是由于其作用是优化梯度的计算,就是让梯度下降跑得更快,而现在成熟的深度学习框架,如Pytorch,均实现了反向传播算法并将其细节隐藏起来,因此如果是以使用深度学习为目的进行学习,不了解反向传播算法并不影响使用深度学习模型,因此笔者选择将该部分放入补充。但是反向传播算法真的很重要,建议还是看一看 。
在学习反向传播算法之前,我们肯定要先知道反向传播算法是干什么的。反向传播算法并不是什么新的优化算法,而是一种用于在深度神经网络中加速梯度计算的算法 。上一小节我们就讲到,多层感知机依旧是使用梯度下降及其变体进行优化求解的,那这当中自然会产生大量的梯度计算,而感知机或者说神经网络的层数堆叠,除了带来参数量的剧增,梯度的计算复杂度也会随着增加,尤其是越靠近输入层的参数,其梯度计算越复杂 。
而反向传播算法就是说,我们发现参数的梯度计算之间是存在相互依赖的,具体表现为层数靠前的参数的梯度计算会用到层数靠后的参数的梯度计算的中间结果 ,因此,我们在算梯度的时候,可以从后往前算,然后计算靠后层数的梯度时,将靠前层数需要用到的中间结果储存起来,传给靠前层数使用 ,这样就可以减少大量的重复计算 ,由于这种算法需要从后往前计算梯度,因此得名反向传播算法 ,相对的,计算模型输出的过程则被称之为前向传播 。
总结一下就是,原来在梯度下降中算梯度的时候,就是按照每一个参数的梯度计算公式算,但是在深度神经网络中,梯度的计算公式会变得很复杂,计算量会变得很大,而这时候就有人发现,算梯度的过程中是存在很多重复计算的,因此设计了一套算法,然那些被重复计算的结果只需要算一遍,然后存起来复用,这样就大大减少了计算量,这就是反向传播算法。下面,我们会使用一个简单的多层感知机作为例子,从推导每一个参数的梯度计算公式,到发现重复计算的部分,再到最后的反向传播算法。
准备工作
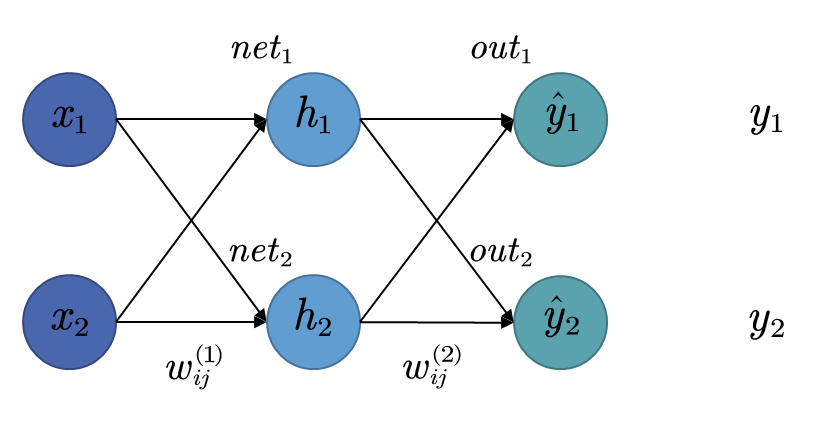
现在,让我们从一个简单的多层感知机模型入手,模型结构与符号标识如下图
从图中可以看到,该模型是一个只有一个隐含层的多层感知机,每一层都只有两个神经元,由于隐含层与输出层都需要经过激活函数,因此使用两个符号分别表示,在隐含层中,用n e t i net_i n e t i h i h_i h i n e t i net_i n e t i
n e t 1 = w 01 ( 1 ) + w 11 ( 1 ) x 1 + w 21 ( 1 ) x 2 h 1 = σ ( n e t 1 ) net_1 = w_{01}^{(1)} + w_{11}^{(1)} x_1 + w_{21}^{(1)} x_2 \\
h_1 = \sigma(net_1)
n e t 1 = w 01 ( 1 ) + w 11 ( 1 ) x 1 + w 21 ( 1 ) x 2 h 1 = σ ( n e t 1 )
在输出层中同理,用o u t i out_i o u t i y ^ i \hat{y}_i y ^ i w i j ( 1 ) w_{ij}^{(1)} w ij ( 1 ) i i i i = 0 i=0 i = 0 j j j x 1 x_1 x 1 h 1 h_1 h 1 w 11 ( 1 ) w_{11}^{(1)} w 11 ( 1 ) n e t 1 net_1 n e t 1 w i j ( 2 ) w_{ij}^{(2)} w ij ( 2 ) i i i j j j
最后,为简单起见,我们暂时不考虑小批量的情况,假设只有一个输入样本( ( x 1 , x 2 ) , ( y 1 , y 2 ) ) ((x_1, x_2),(y_1, y_2)) (( x 1 , x 2 ) , ( y 1 , y 2 )) ( y ^ 1 , y ^ 2 ) (\hat{y}_1, \hat{y}_2) ( y ^ 1 , y ^ 2 )
梯度计算式推导
准备工作结束,接下来我们尝试使用一般的方法来计算参数的梯度,这当中会大量的使用到链式法则 。在此之前,我们先把损失函数以及激活函数的导数先算好,以便后续取用
L = − ∑ i = 1 2 y i ln y ^ i , ∂ L ∂ y ^ i = − y i y ^ i σ ( x ) = 1 1 + e − x , σ ′ ( x ) = σ ( x ) ( 1 − σ ( x ) ) s o f t m a x ( x i ) = e x i ∑ k e x k , s o f t m a x ′ ( x i ) = s o f t m a x ( x i ) ( 1 − s o f t m a x ( x i ) ) L = - \sum_{i=1}^{2} y_i \ln \hat{y}_i, \quad \frac{\partial L}{\partial \hat{y}_i} = -\frac{y_i}{\hat{y}_i} \\
\sigma(x) = \frac{1}{1 + e^{-x}}, \quad \sigma^\prime(x) = \sigma(x)(1 - \sigma(x)) \\
\mathrm{softmax}(x_i) = \frac{e^{x_i}}{\sum\limits_{k} e^{x_k}}, \quad \mathrm{softmax}^\prime(x_i) = \mathrm{softmax}(x_i)(1 - \mathrm{softmax}(x_i))
L = − i = 1 ∑ 2 y i ln y ^ i , ∂ y ^ i ∂ L = − y ^ i y i σ ( x ) = 1 + e − x 1 , σ ′ ( x ) = σ ( x ) ( 1 − σ ( x )) softmax ( x i ) = k ∑ e x k e x i , softmax ′ ( x i ) = softmax ( x i ) ( 1 − softmax ( x i ))
我们先从靠后层数的参数开始计算,以参数w 11 ( 2 ) w_{11}^{(2)} w 11 ( 2 )
o u t 1 = w 01 ( 2 ) + w 11 ( 2 ) h 1 + w 21 ( 2 ) h 2 y ^ 1 = s o f t m a x ( o u t 1 ) out_1 = w_{01}^{(2)} + w_{11}^{(2)} h_1 + w_{21}^{(2)} h_2 \\
\hat{y}_1 = \mathrm{softmax}(out_1)
o u t 1 = w 01 ( 2 ) + w 11 ( 2 ) h 1 + w 21 ( 2 ) h 2 y ^ 1 = softmax ( o u t 1 )
根据链式法则
∂ L ∂ w 11 ( 2 ) = ∂ L ∂ y ^ 1 ∂ y ^ 1 ∂ o u t 1 ∂ o u t 1 ∂ w 11 ( 2 ) = − y 1 y ^ 1 y ^ 1 ( 1 − y ^ 1 ) h 1 = − y 1 ( 1 − y ^ 1 ) h 1 \frac{\partial L}{\partial w_{11}^{(2)}} = \frac{\partial L}{\partial \hat{y}_1}\frac{\partial \hat{y}_1}{\partial out_1}\frac{\partial out_1}{\partial w_{11}^{(2)}}
= -\frac{y_1}{\hat{y}_1} \hat{y}_1(1 - \hat{y}_1) h_1 = -y_1 (1 - \hat{y}_1) h_1
∂ w 11 ( 2 ) ∂ L = ∂ y ^ 1 ∂ L ∂ o u t 1 ∂ y ^ 1 ∂ w 11 ( 2 ) ∂ o u t 1 = − y ^ 1 y 1 y ^ 1 ( 1 − y ^ 1 ) h 1 = − y 1 ( 1 − y ^ 1 ) h 1
同理,其余w i j ( 2 ) w_{ij}^{(2)} w ij ( 2 ) w 11 ( 1 ) w_{11}^{(1)} w 11 ( 1 )
n e t 1 = w 01 ( 1 ) + w 11 ( 1 ) x 1 + w 21 ( 1 ) x 2 , h 1 = σ ( n e t 1 ) o u t 1 = w 01 ( 2 ) + w 11 ( 2 ) h 1 + w 21 ( 2 ) h 2 , y ^ 1 = s o f t m a x ( o u t 1 ) o u t 2 = w 02 ( 2 ) + w 12 ( 2 ) h 1 + w 22 ( 2 ) h 2 , y ^ 2 = s o f t m a x ( o u t 2 ) net_1 = w_{01}^{(1)} + w_{11}^{(1)} x_1 + w_{21}^{(1)} x_2, \quad h_1 = \sigma(net_1) \\
out_1 = w_{01}^{(2)} + w_{11}^{(2)} h_1 + w_{21}^{(2)} h_2, \quad \hat{y}_1 = \mathrm{softmax}(out_1) \\
out_2 = w_{02}^{(2)} + w_{12}^{(2)} h_1 + w_{22}^{(2)} h_2, \quad \hat{y}_2 = \mathrm{softmax}(out_2)
n e t 1 = w 01 ( 1 ) + w 11 ( 1 ) x 1 + w 21 ( 1 ) x 2 , h 1 = σ ( n e t 1 ) o u t 1 = w 01 ( 2 ) + w 11 ( 2 ) h 1 + w 21 ( 2 ) h 2 , y ^ 1 = softmax ( o u t 1 ) o u t 2 = w 02 ( 2 ) + w 12 ( 2 ) h 1 + w 22 ( 2 ) h 2 , y ^ 2 = softmax ( o u t 2 )
这里我们可以看到,参数w 11 ( 1 ) w_{11}^{(1)} w 11 ( 1 ) x 1 x_1 x 1 h 1 h_1 h 1 h 1 h_1 h 1 后续的所有层的所有中间结果都有关 ,这也就造成了计算复杂度的剧增,这里的使用的例子还算简单,大家可以尝试一下多加一些层,每一层多加一些神经元,那么除了输出层参数,其余层的参数推导出的梯度计算式都将巨长无比。言归正传,我们还是来看看参数w 11 ( 1 ) w_{11}^{(1)} w 11 ( 1 )
∂ L ∂ w 11 ( 1 ) = ∂ L ∂ h 1 ∂ h 1 ∂ n e t 1 ∂ n e t 1 ∂ w 11 ( 1 ) = ∂ L ∂ h 1 h 1 ( 1 − h 1 ) x 1 ∂ L ∂ h 1 = ∂ L ∂ y ^ 1 ∂ y ^ 1 ∂ o u t 1 ∂ o u t 1 ∂ h 1 + ∂ L ∂ y ^ 2 ∂ y ^ 2 ∂ o u t 2 ∂ o u t 2 ∂ h 1 = − y 1 ( 1 − y ^ 1 ) w 11 ( 2 ) − y 2 ( 1 − y ^ 2 ) w 12 ( 2 ) ∂ L ∂ w 11 ( 1 ) = ( y 1 ( 1 − y ^ 1 ) w 11 ( 2 ) + y 2 ( 1 − y ^ 2 ) w 12 ( 2 ) ) h 1 ( h 1 − 1 ) x 1 \frac{\partial L}{\partial w_{11}^{(1)}}
= \frac{\partial L}{\partial h_1}\frac{\partial h_1}{\partial net_1}\frac{\partial net_1}{\partial w_{11}^{(1)}}
= \frac{\partial L}{\partial h_1} h_1 (1 - h_1) x_1 \\
\frac{\partial L}{\partial h_1} = \frac{\partial L}{\partial \hat{y}_1}\frac{\partial \hat{y}_1}{\partial out_1}\frac{\partial out_1}{\partial h_1} + \frac{\partial L}{\partial \hat{y}_2}\frac{\partial \hat{y}_2}{\partial out_2}\frac{\partial out_2}{\partial h_1}
= - y_1 (1 - \hat{y}_1) w_{11}^{(2)} - y_2 (1 - \hat{y}_2) w_{12}^{(2)} \\
\frac{\partial L}{\partial w_{11}^{(1)}} = (y_1 (1 - \hat{y}_1) w_{11}^{(2)} + y_2 (1 - \hat{y}_2) w_{12}^{(2)}) h_1 (h_1 - 1) x_1
∂ w 11 ( 1 ) ∂ L = ∂ h 1 ∂ L ∂ n e t 1 ∂ h 1 ∂ w 11 ( 1 ) ∂ n e t 1 = ∂ h 1 ∂ L h 1 ( 1 − h 1 ) x 1 ∂ h 1 ∂ L = ∂ y ^ 1 ∂ L ∂ o u t 1 ∂ y ^ 1 ∂ h 1 ∂ o u t 1 + ∂ y ^ 2 ∂ L ∂ o u t 2 ∂ y ^ 2 ∂ h 1 ∂ o u t 2 = − y 1 ( 1 − y ^ 1 ) w 11 ( 2 ) − y 2 ( 1 − y ^ 2 ) w 12 ( 2 ) ∂ w 11 ( 1 ) ∂ L = ( y 1 ( 1 − y ^ 1 ) w 11 ( 2 ) + y 2 ( 1 − y ^ 2 ) w 12 ( 2 ) ) h 1 ( h 1 − 1 ) x 1
同理,其余w i j ( 1 ) w_{ij}^{(1)} w ij ( 1 )
∂ L ∂ w i j ( 2 ) = ∂ L ∂ y ^ j ∂ y ^ j ∂ o u t j ∂ o u t j ∂ w i j ( 2 ) ∂ L ∂ w i j ( 1 ) = ( ∑ k ∂ L ∂ y ^ k ∂ y ^ k ∂ o u t k ∂ o u t k ∂ h j ) ∂ h j ∂ n e t j ∂ n e t j ∂ w i j ( 1 ) \frac{\partial L}{\partial w_{ij}^{(2)}} = \frac{\partial L}{\partial \hat{y}_j}\frac{\partial \hat{y}_j}{\partial out_j}\frac{\partial out_j}{\partial w_{ij}^{(2)}} \\
\frac{\partial L}{\partial w_{ij}^{(1)}}
= \left( \sum_{k} \frac{\partial L}{\partial \hat{y}_k}\frac{\partial \hat{y}_k}{\partial out_k}\frac{\partial out_k}{\partial h_j} \right)
\frac{\partial h_j}{\partial net_j}\frac{\partial net_j}{\partial w_{ij}^{(1)}}
∂ w ij ( 2 ) ∂ L = ∂ y ^ j ∂ L ∂ o u t j ∂ y ^ j ∂ w ij ( 2 ) ∂ o u t j ∂ w ij ( 1 ) ∂ L = ( k ∑ ∂ y ^ k ∂ L ∂ o u t k ∂ y ^ k ∂ h j ∂ o u t k ) ∂ n e t j ∂ h j ∂ w ij ( 1 ) ∂ n e t j
梯度计算优化
观察两层参数的计算式,我们不难发现有一些重复计算的部分,例如∂ L ∂ y ^ i ∂ y ^ i ∂ o u t i \frac{\partial L}{\partial \hat{y}_i}\frac{\partial \hat{y}_i}{\partial out_i} ∂ y ^ i ∂ L ∂ o u t i ∂ y ^ i
δ i ( 2 ) = ∂ L ∂ y ^ i ∂ y ^ i ∂ o u t i \delta_{i}^{(2)} = \frac{\partial L}{\partial \hat{y}_i}\frac{\partial \hat{y}_i}{\partial out_i}
δ i ( 2 ) = ∂ y ^ i ∂ L ∂ o u t i ∂ y ^ i
并且不难观察到
∂ o u t j ∂ w i j ( 2 ) = h i , i ≠ 0 ∂ o u t j ∂ w i j ( 2 ) = 1 , i = 0 \frac{\partial out_j}{\partial w_{ij}^{(2)}} = h_i, \quad i \ne 0 \\
\frac{\partial out_j}{\partial w_{ij}^{(2)}} = 1, \quad i = 0
∂ w ij ( 2 ) ∂ o u t j = h i , i = 0 ∂ w ij ( 2 ) ∂ o u t j = 1 , i = 0
故w i j ( 2 ) w_{ij}^{(2)} w ij ( 2 )
∂ L ∂ w i j ( 2 ) = δ i ( 2 ) h i , i ≠ 0 ∂ L ∂ w i j ( 2 ) = δ i ( 2 ) , i = 0 \frac{\partial L}{\partial w_{ij}^{(2)}} = \delta_{i}^{(2)} h_i, \quad i \ne 0 \\
\frac{\partial L}{\partial w_{ij}^{(2)}} = \delta_{i}^{(2)}, \quad i = 0
∂ w ij ( 2 ) ∂ L = δ i ( 2 ) h i , i = 0 ∂ w ij ( 2 ) ∂ L = δ i ( 2 ) , i = 0
于是我们可以换一种计算方法,先算出所有的δ i ( 2 ) \delta_{i}^{(2)} δ i ( 2 ) h i h_i h i w i j ( 2 ) w_{ij}^{(2)} w ij ( 2 ) δ i ( 2 ) \delta_{i}^{(2)} δ i ( 2 ) j + 1 j+1 j + 1 w i j ( 2 ) w_{ij}^{(2)} w ij ( 2 )
我们继续来看w i j ( 1 ) w_{ij}^{(1)} w ij ( 1 ) w i j ( 2 ) w_{ij}^{(2)} w ij ( 2 )
∂ n e t j ∂ w i j ( 1 ) = x i , i ≠ 0 ∂ n e t j ∂ w i j ( 1 ) = 1 , i = 0 \frac{\partial net_j}{\partial w_{ij}^{(1)}} = x_i, \quad i \ne 0 \\
\frac{\partial net_j}{\partial w_{ij}^{(1)}} = 1, \quad i = 0
∂ w ij ( 1 ) ∂ n e t j = x i , i = 0 ∂ w ij ( 1 ) ∂ n e t j = 1 , i = 0
于是,我们也想将w i j ( 1 ) w_{ij}^{(1)} w ij ( 1 )
∂ L ∂ w i j ( 1 ) = δ i ( 1 ) x i , i ≠ 0 ∂ L ∂ w i j ( 1 ) = δ i ( 1 ) , i = 0 \frac{\partial L}{\partial w_{ij}^{(1)}} = \delta_{i}^{(1)} x_i, \quad i \ne 0 \\
\frac{\partial L}{\partial w_{ij}^{(1)}} = \delta_{i}^{(1)}, \quad i = 0
∂ w ij ( 1 ) ∂ L = δ i ( 1 ) x i , i = 0 ∂ w ij ( 1 ) ∂ L = δ i ( 1 ) , i = 0
其中
δ i ( 1 ) = ( ∑ k ∂ L ∂ y ^ k ∂ y ^ k ∂ o u t k ∂ o u t k ∂ h i ) ∂ h i ∂ n e t i \delta_{i}^{(1)} = \left( \sum_{k} \frac{\partial L}{\partial \hat{y}_k}\frac{\partial \hat{y}_k}{\partial out_k}\frac{\partial out_k}{\partial h_i} \right)
\frac{\partial h_i}{\partial net_i}
δ i ( 1 ) = ( k ∑ ∂ y ^ k ∂ L ∂ o u t k ∂ y ^ k ∂ h i ∂ o u t k ) ∂ n e t i ∂ h i
观察发现
∂ L ∂ y ^ k ∂ y ^ k ∂ o u t k = δ k ( 2 ) ∂ o u t k ∂ h i = w i k ( 2 ) \frac{\partial L}{\partial \hat{y}_k}\frac{\partial \hat{y}_k}{\partial out_k} = \delta_{k}^{(2)} \\
\frac{\partial out_k}{\partial h_i} = w_{ik}^{(2)}
∂ y ^ k ∂ L ∂ o u t k ∂ y ^ k = δ k ( 2 ) ∂ h i ∂ o u t k = w ik ( 2 )
而∂ h i ∂ n e t i \frac{\partial h_i}{\partial net_i} ∂ n e t i ∂ h i
∂ h i ∂ n e t i = ϕ ′ ( n e t i ) \frac{\partial h_i}{\partial net_i} = \phi^\prime(net_i)
∂ n e t i ∂ h i = ϕ ′ ( n e t i )
故
δ i ( 1 ) = ( ∑ k δ k ( 2 ) w i k ( 2 ) ) ϕ ′ ( n e t i ) \delta_{i}^{(1)} = \left( \sum_{k} \delta_{k}^{(2)} w_{ik}^{(2)} \right)
\phi^\prime(net_i)
δ i ( 1 ) = ( k ∑ δ k ( 2 ) w ik ( 2 ) ) ϕ ′ ( n e t i )
到这里我们就可以发现,正如上文所说,靠前层数的梯度计算是会使用到靠后层数的梯度计算的中间结果的 。到了这一层,对比原计算方法,单就δ k ( 2 ) \delta_{k}^{(2)} δ k ( 2 )
最后,如果再加一层隐含层,梯度计算式会更复杂吗?尝试推导一下就会发现,如果是直接推导计算式,那确实会更复杂,而如果使用上述计算方法,其计算式形式是类似的,假设有一个δ i ( 0 ) \delta_{i}^{(0)} δ i ( 0 )
δ i ( 0 ) = ( ∑ k δ k ( 1 ) w i k ( 1 ) ) ϕ ′ ( x i ) \delta_{i}^{(0)} = \left( \sum_{k} \delta_{k}^{(1)} w_{ik}^{(1)} \right)
\phi^\prime(x_i)
δ i ( 0 ) = ( k ∑ δ k ( 1 ) w ik ( 1 ) ) ϕ ′ ( x i )
所以,上面提出的这套算法是可以被应用到任意层数的多层感知机中的,并且δ \delta δ ,因此,这套算法的计算需要从后往前算 ,故得名反向传播算法 。
反向传播算法
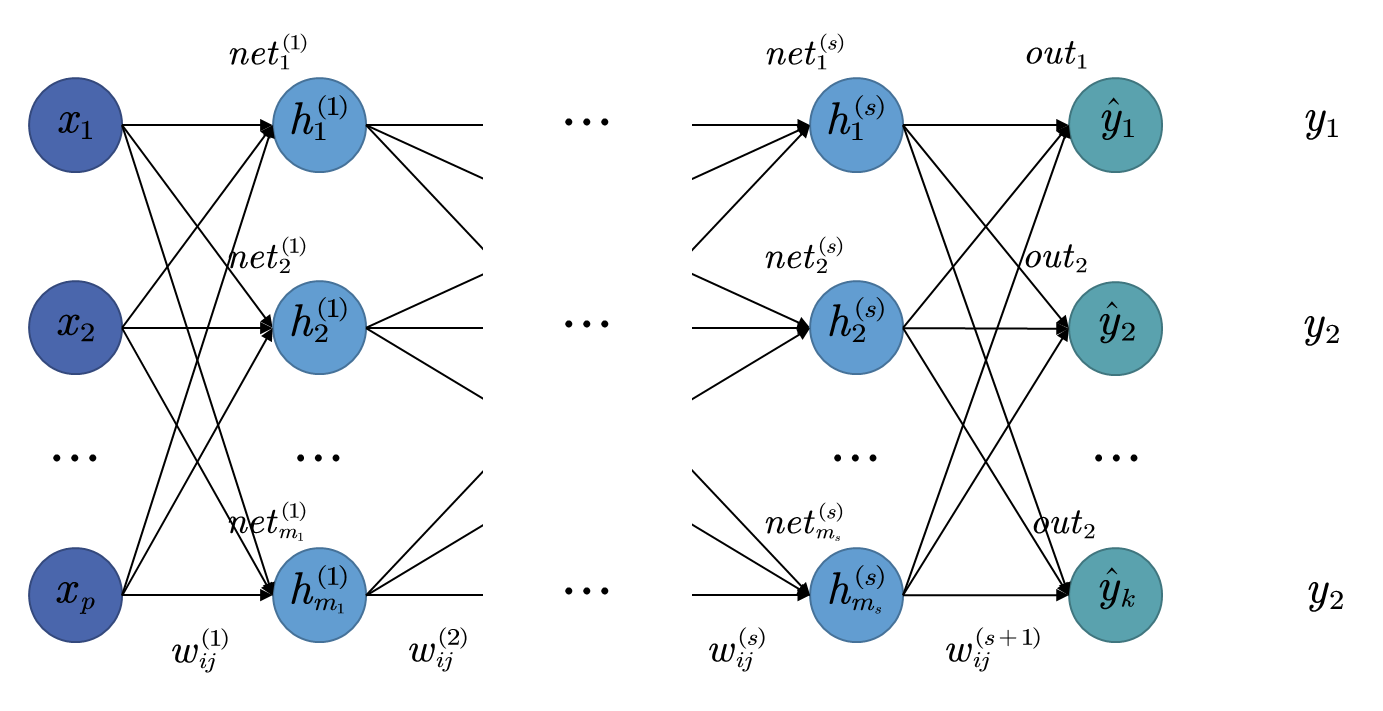
至此,我们已经通过一个简单的模型了解了反向传播算法是如何优化梯度计算的效率的,现在,我们就给出一般多层感知机模型下的反向传播算法,模型结构图与符号标识如下图
记输出层神经元数量为p p p s s s m i m_{i} m i n e t j ( i ) net^{(i)}_{j} n e t j ( i ) h j ( i ) h^{(i)}_{j} h j ( i ) o u t i out_i o u t i y ^ i \hat{y}_i y ^ i w i j ( l ) w_{ij}^{(l)} w ij ( l ) l l l i i i j j j L L L ϕ i \phi_{i} ϕ i ϕ o u t \phi_{out} ϕ o u t
则使用反向传播算法计算该多层感知机模型的梯度的计算公式为
∂ L ∂ w i j ( l ) = { δ i ( l ) h i i ≠ 0 , l ≠ 1 δ i ( l ) x i i ≠ 0 , l = 1 δ i ( l ) i = 0 δ i ( l ) = { ( ∑ k δ k ( l + 1 ) w i k ( l + 1 ) ) ϕ l + 1 ′ ( n e t i ( l + 1 ) ) l ≠ s + 1 ∂ L ∂ y ^ i ϕ e n d ′ ( n e t i ( l + 1 ) ) l = s + 1 \frac{\partial L}{\partial w_{ij}^{(l)}} =
\begin{cases}
\delta_{i}^{(l)} h_i & i \ne 0, \ l \ne 1 \\
\delta_{i}^{(l)} x_i & i \ne 0, \ l = 1 \\
\delta_{i}^{(l)} & i = 0 \\
\end{cases}
\\
\delta_{i}^{(l)} =
\begin{cases}
\left( \sum\limits_{k} \delta_{k}^{(l+1)} w_{ik}^{(l+1)} \right)
\phi^\prime_{l+1}(net_i^{(l+1)}) & l \ne s+1 \\
\frac{\partial L}{\partial \hat{y}_i}\phi^\prime_{end}(net_i^{(l+1)}) & l = s+1 \\
\end{cases}
∂ w ij ( l ) ∂ L = ⎩ ⎨ ⎧ δ i ( l ) h i δ i ( l ) x i δ i ( l ) i = 0 , l = 1 i = 0 , l = 1 i = 0 δ i ( l ) = ⎩ ⎨ ⎧ ( k ∑ δ k ( l + 1 ) w ik ( l + 1 ) ) ϕ l + 1 ′ ( n e t i ( l + 1 ) ) ∂ y ^ i ∂ L ϕ e n d ′ ( n e t i ( l + 1 ) ) l = s + 1 l = s + 1
Pytorch代码实现
现在,我们来介绍一下多层感知机的Pytorch代码实现,运行环境为jupyter notebook
注1:Pytorch是目前最主流的深度学习框架,以下内容将基于此框架实现深度学习算法,对Pytorch不熟悉的读者可以移步Pytorch快速入门 作简单了解。
注2:以下内容会介绍如何使用Pytorch框架构建深度学习模型,以及介绍常用的参数,并与上述理论部分相对照,再用Pytorch中自带的小型数据集跑一个简单的demo。
注3:本文并不会将代码讲得面面俱到,在学习Pytorch的过程中建议多多参考PyTorch官方文档 或者PyTorch中文文档 。
首先,我们需要导入依赖库
1 2 3 4 5 import torchfrom torch import nnfrom torch.utils.data import DataLoader from torchvision import transforms from torchvision.datasets import FashionMNIST
然后,我们需要读取本小节使用的示例数据集,我们将使用FashionMNIST数据集,相信稍微了解深度学习的读者应该都知道MNIST数据集,这是一个经典的手写数字数据集,数据均为灰度图像,类别为10类。但是MNIST数据集对于现代的深度学习模型来说已经过于简单了,因此,FashionMNIST数据集就是为此而生的,其数据为与MNIST数据集形状相同的灰度图像,且也为10个类别的分类问题,可以直接替代MNIST数据集作为图像分类问题的基准数据集。
1 2 3 4 5 6 7 8 data_FashionMNIST_train = FashionMNIST('.\Data\fashion_mnist_data' , train=True , download=True , transform=transforms.ToTensor()) data_FashionMNIST_test = FashionMNIST('.\Data\fashion_mnist_data' , train=False , download=True , transform=transforms.ToTensor()) FashionMNIST_train = DataLoader(data_FashionMNIST_train, batch_size=64 , shuffle=True ) FashionMNIST_test = DataLoader(data_FashionMNIST_test, batch_size=64 , shuffle=True )
接着,我们正式介绍多层感知机的实现,首先我们要明白,神经网络模型是由多个网络层堆叠而成,比方说我的第一层是一个线性层,第二层是一个卷积层等等,然后这些层各自会有不同的输入输出神经元数量,常常有人将做神经网络模型比喻为搭积木。Pytorch作为一个深度学习框架,其逻辑就是将常用的网络层一一封装,供用户自行堆叠组装。
前面提到过,多层感知机的每一层在神经网络中通常被称为线性层,那从神经网络的角度来说,多层感知机就是一个由多个线性层堆叠而成的神经网络。Pytorch中用nn.Linear()函数实现线性层,其参数也非常简单,第一个参数为输入神经元数量,第二个参数为输出神经元数量,以FashionMNIST数据集为例,假设我们构建一个两层的多层感知机,由于FashionMNIST数据集中的图像大小为28 × 28 28 \times 28 28 × 28 784,而该数据集是一个十个类别的多分类问题,因此第二层的输出为10,再设隐含层大小为256,则第一层的输出与第二层的输入均为256,至此,我们得到了模型的所有参数,构建模型的代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class MLP (nn.Module): def __init__ (self ): super ().__init__() self.input = nn.Flatten() self.L1 = nn.Linear(784 , 256 ) self.L2 = nn.Linear(256 , 10 ) self.ReLU = nn.ReLU() def forward (self, x ): x = self.input (x) x = self.L1(x) x = self.ReLU(x) x = self.L2(x) return x
将模型实例化,并读取计算设备
1 2 MLP = MLP() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu" )
而后,我们还要解决损失函数,优化算法以及训练,分类问题自然是选用交叉熵损失函数,优化算法选择梯度下降,Pytorch的训练流程相对固定,此处将其封装为一个训练函数,以便重复调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 def model_train (model, train_data, test_data, num_epoch, lr, device ): criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=lr) model.to(device) train_loss = [] train_accuracy = [] test_accuracy = [] for epoch in range (num_epoch): model.train() train_run_loss = 0.0 true_total = 0 data_size = 0 for data, target in train_data: data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() optimizer.step() train_run_loss += loss.item() predicted = torch.argmax(output, 1 ) true_batch = (predicted == target).sum ().item() true_total += true_batch data_size += target.size(0 ) train_epoch_loss = train_run_loss / len (train_data) train_loss.append(train_epoch_loss) print ('Epoch: {} \tTraining Loss: {:.6f}' .format (epoch+1 , train_epoch_loss)) train_epoch_accuracy = true_total / data_size train_accuracy.append(train_epoch_accuracy) print ('Epoch: {} \tTraining Accuracy: {:.2f}%' .format (epoch+1 , 100 * train_epoch_accuracy)) model.eval () true_total = 0 data_size = 0 with torch.no_grad(): for data, target in test_data: data, target = data.to(device), target.to(device) output = model(data) predicted = torch.argmax(output, 1 ) true_batch = (predicted == target).sum ().item() true_total += true_batch data_size += target.size(0 ) test_epoch_accuracy = true_total / data_size test_accuracy.append(test_epoch_accuracy) print ('Epoch: {} \tTesting Accuracy: {:.2f}%' .format (epoch+1 , 100 * test_epoch_accuracy)) import matplotlib.pyplot as plt plt.figure() plt.xlabel("Epoch" ) plt.plot(range (1 , num_epoch+1 ), train_loss, '-' , label="Training Loss" ) plt.plot(range (1 , num_epoch+1 ), train_accuracy, '--' , label="Training Acc" ) plt.plot(range (1 , num_epoch+1 ), test_accuracy, '-.' , label="Testing Accuracy" ) plt.legend() torch.cuda.empty_cache()
最后,运行训练函数即可
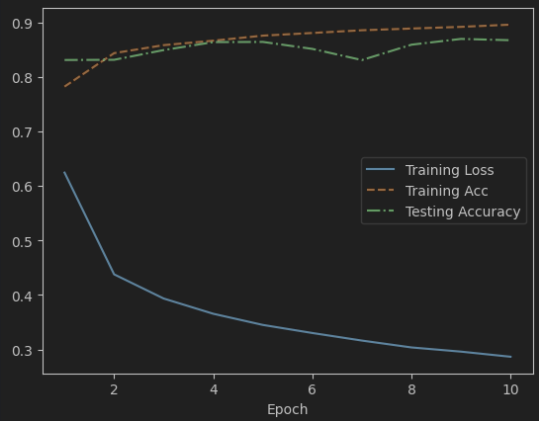
1 model_train(MLP, FashionMNIST_train, FashionMNIST_test, num_epoch=10 , lr=0.1 , device=device)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Epoch: 1 Training Loss: 0.624402 Epoch: 1 Training Accuracy: 78.22% Epoch: 1 Testing Accuracy: 83.09% Epoch: 2 Training Loss: 0.437807 Epoch: 2 Training Accuracy: 84.35% Epoch: 2 Testing Accuracy: 83.13% Epoch: 3 Training Loss: 0.393465 Epoch: 3 Training Accuracy: 85.82% Epoch: 3 Testing Accuracy: 84.91% Epoch: 4 Training Loss: 0.365517 Epoch: 4 Training Accuracy: 86.64% Epoch: 4 Testing Accuracy: 86.37% Epoch: 5 Training Loss: 0.345038 Epoch: 5 Training Accuracy: 87.56% Epoch: 5 Testing Accuracy: 86.41% Epoch: 6 Training Loss: 0.330205 Epoch: 6 Training Accuracy: 88.05% Epoch: 6 Testing Accuracy: 85.13% Epoch: 7 Training Loss: 0.316345 Epoch: 7 Training Accuracy: 88.55% Epoch: 7 Testing Accuracy: 83.08% Epoch: 8 Training Loss: 0.303760 Epoch: 8 Training Accuracy: 88.86% Epoch: 8 Testing Accuracy: 85.90% Epoch: 9 Training Loss: 0.296070 Epoch: 9 Training Accuracy: 89.17% Epoch: 9 Testing Accuracy: 86.96% Epoch: 10 Training Loss: 0.286688 Epoch: 10 Training Accuracy: 89.58% Epoch: 10 Testing Accuracy: 86.72%
正则化与丢弃法
了解完多层感知机后,现在我们来介绍一下在多层感知机的训练中可能会遇到的问题,以及相关的一些技术,例如本小节我们将讨论的过拟合 问题,以及相关的技术正则化与丢弃法 。
正则化
对于正则化,相信接触过线性回归的读者应该并不陌生,其通过在损失函数中添加正则化项 ,以限制模型的复杂度,从而实现防止过拟合的目的。常用的正则化项有L 1 L_1 L 1 L 2 L_2 L 2 L 1 L_1 L 1 模型的所有参数的绝对值之和 ,而L 2 L_2 L 2 模型的所有参数的平方和 ,最后,正则化项还会乘以一个正则化系数α \alpha α L 2 L_2 L 2
L ( W ) = − ∑ i = 1 n ∑ j = 1 m y i ( j ) l n y ^ i ( j ) + α Ω ( W ) L(W)
= - \sum_{i=1}^{n} \sum_{j=1}^{m} {y}_{i}^{(j)} \mathrm{ln} {\hat{y}}_{i}^{(j)} + \alpha \Omega(W)
L ( W ) = − i = 1 ∑ n j = 1 ∑ m y i ( j ) ln y ^ i ( j ) + α Ω ( W )
其中,Ω ( W ) \Omega(W) Ω ( W )
丢弃法
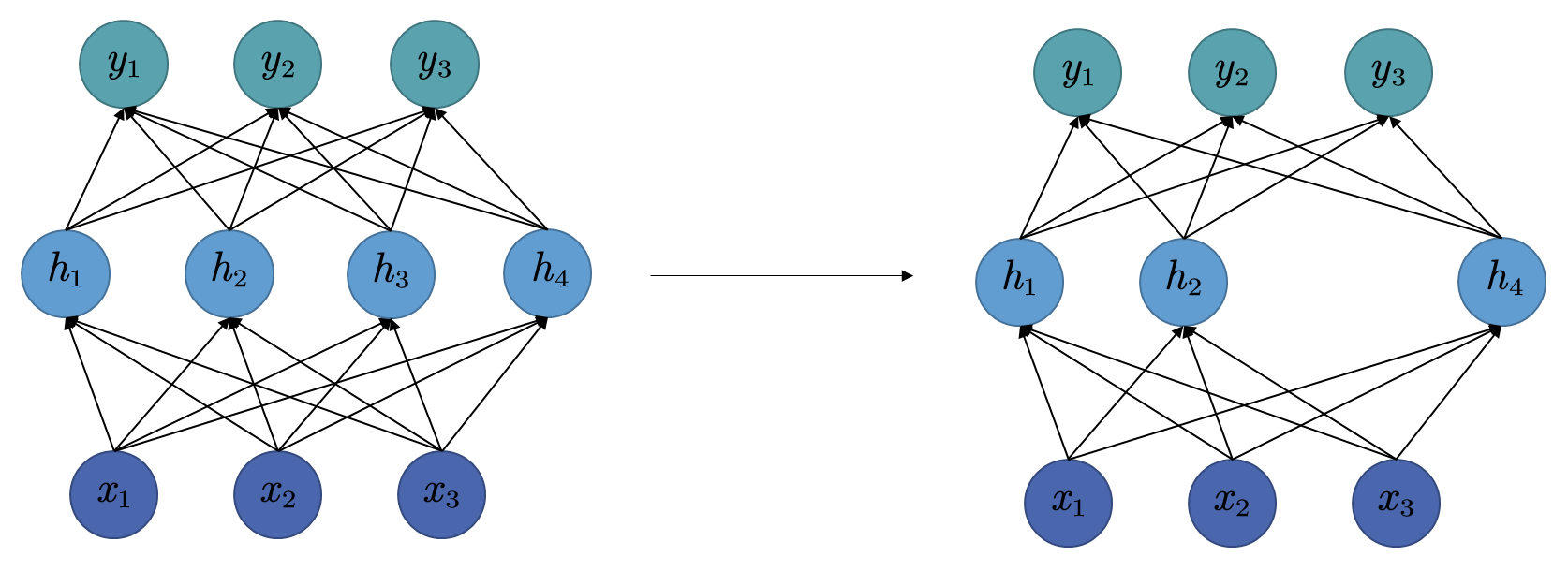
而丢弃法 (Dropout)是一种针对多层神经网络结构的模型设计的,用于防止过拟合问题的方法,对于神经网络模型来说,相比于正则化,Dropout是更常用的防止过拟合的方法 。
Dropout的策略是对于隐含层(非输入输出层) ,在训练过程 中,对每一轮迭代(即每一个小批量的训练),均按相同的概率p p p
其实现方法为,生成一个与隐含层输出向量h \boldsymbol{h} h m \boldsymbol{m} m p p p 0 0 0 1 − p 1 - p 1 − p 1 1 1 h \boldsymbol{h} h m \boldsymbol{m} m 0 0 0
在模型的推理阶段 ,Dropout将不再丢弃神经元 ,但是此时会出现一个问题,由于在训练过程中仅有部分神经元参与工作,如果在推理过程中启用所有的神经元,那么可以预见在训练过程中使用了Dropout的网络层的输出会变大,这显然会出大问题,但是如果在推理过程中也随机进行神经元的丢弃,那么会给模型引入随机性,这也是我们不愿看到的。
因此,最终的解决方案为,在推理阶段,对使用了Dropout的网络层的输出进行缩放 ,具体为将每一个输出值乘以1 − p 1 - p 1 − p x x x 1 − p 1 - p 1 − p x ( 1 − p ) x(1 - p) x ( 1 − p ) x x x 1 − p 1 - p 1 − p
Pytorch代码实现
对于上述介绍的技术,Pytorch也提供了相应的实现,首先是正则化,Pytorch将L 2 L_2 L 2 weight_decay,该参数即为正则化系数α \alpha α 0 0 0 L 1 L_1 L 1 Pytorch中并没有被实现,若需使用,则必须进行手动实现。在上述训练函数中,将优化算法对应的代码改为如下代码,并为训练函数添加一个新的参数wd,即可在模型训练中使用L 2 L_2 L 2
1 torch.optim.SGD(model.parameters(), lr=lr, weight_decay=wd)
而Dropout在Pytorch中被视为一个网络层,其使用nn.Dropout()函数实现,该函数有一个参数p,对应Dropout中的丢弃概率p p p p p p 0 0 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class MLP_dropout (nn.Module): def __init__ (self ): super ().__init__() self.input = nn.Flatten() self.L1 = nn.Linear(784 , 256 ) self.L2 = nn.Linear(256 , 10 ) self.ReLU = nn.ReLU() self.Dropout = nn.Dropout(p=0.5 ) def forward (self, x ): x = self.input (x) x = self.L1(x) x = self.ReLU(x) x = self.Dropout(x) x = self.L2(x) return x
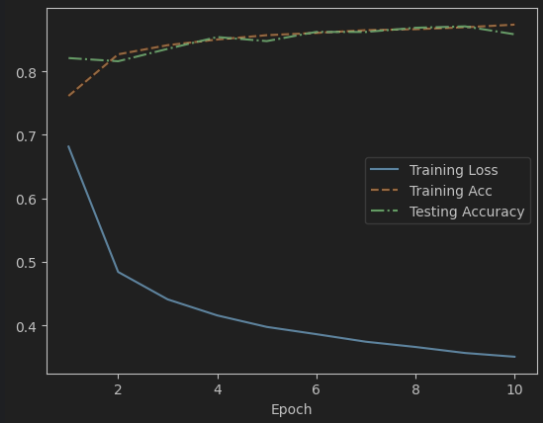
1 2 MLP_dropout = MLP_dropout() model_train(MLP_dropout, FashionMNIST_train, FashionMNIST_test, num_epoch=10 , lr=0.1 , wd=0 , device=device)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Epoch: 1 Training Loss: 0.681472 Epoch: 1 Training Accuracy: 76.13% Epoch: 1 Testing Accuracy: 82.08% Epoch: 2 Training Loss: 0.484318 Epoch: 2 Training Accuracy: 82.67% Epoch: 2 Testing Accuracy: 81.58% Epoch: 3 Training Loss: 0.441137 Epoch: 3 Training Accuracy: 84.11% Epoch: 3 Testing Accuracy: 83.53% Epoch: 4 Training Loss: 0.415889 Epoch: 4 Training Accuracy: 85.00% Epoch: 4 Testing Accuracy: 85.39% Epoch: 5 Training Loss: 0.397788 Epoch: 5 Training Accuracy: 85.68% Epoch: 5 Testing Accuracy: 84.75% Epoch: 6 Training Loss: 0.386381 Epoch: 6 Training Accuracy: 86.04% Epoch: 6 Testing Accuracy: 86.20% Epoch: 7 Training Loss: 0.374492 Epoch: 7 Training Accuracy: 86.47% Epoch: 7 Testing Accuracy: 86.19% Epoch: 8 Training Loss: 0.366260 Epoch: 8 Training Accuracy: 86.62% Epoch: 8 Testing Accuracy: 86.85% Epoch: 9 Training Loss: 0.356786 Epoch: 9 Training Accuracy: 86.93% Epoch: 9 Testing Accuracy: 87.07% Epoch: 10 Training Loss: 0.350871 Epoch: 10 Training Accuracy: 87.34% Epoch: 10 Testing Accuracy: 85.82%
从结果上我们可以看出,相比于不使用正则化与丢弃法的结果,训练准确率与测试准确率之间的差距明显更小。
参数初始化
最后,我们来讨论深度学习模型训练中的另一个重要问题,参数初始化 问题,顾名思义,就是训练前,深度学习模型的初始权重应该如何设置。千万不要觉得参数初始化就是随便生成一些随机数,一个好的初始参数可以让模型的训练事半功倍,甚至可能影响模型的最终效果。
对称性问题
一般来说,我们会希望初始参数在0 0 0 0 0 0 0 0 0
我们关注w 11 ( 2 ) w_{11}^{(2)} w 11 ( 2 ) w 21 ( 2 ) w_{21}^{(2)} w 21 ( 2 )
∂ L ∂ w 11 ( 2 ) = − y 1 ( 1 − y ^ 1 ) h 1 ∂ L ∂ w 21 ( 2 ) = − y 1 ( 1 − y ^ 1 ) h 2 \frac{\partial L}{\partial w_{11}^{(2)}} = -y_1 (1 - \hat{y}_1) h_1 \\
\frac{\partial L}{\partial w_{21}^{(2)}} = -y_1 (1 - \hat{y}_1) h_2
∂ w 11 ( 2 ) ∂ L = − y 1 ( 1 − y ^ 1 ) h 1 ∂ w 21 ( 2 ) ∂ L = − y 1 ( 1 − y ^ 1 ) h 2
由于所有的参数均被初始化为0 0 0 h 1 h_1 h 1 h 2 h_2 h 2 w 11 ( 2 ) w_{11}^{(2)} w 11 ( 2 ) w 21 ( 2 ) w_{21}^{(2)} w 21 ( 2 ) h 1 h_1 h 1 h 2 h_2 h 2
梯度爆炸与梯度消失
让我们回到正题,我们希望初始参数在0 0 0 0 0 0 N ( 0 , 0.01 ) N(0, 0.01) N ( 0 , 0.01 )
由于现代的神经网络模型,其网络深度都很深,从上文我们可以得知,梯度下降的过程中,浅层梯度的计算式中存在深层梯度的连乘 ,在网络层数足够深时,这种计算方法就很容易造成浅层梯度的数值过大或者过小 ,这也就是著名的梯度爆炸与梯度消失 问题。
解决梯度爆炸与梯度消失的方法有很多,例如梯度裁剪,通过网络结构设计在乘法运算中加入加法运算(ResNet),而合适的参数初始化也是解决方法之一 。
方差守恒与Xavier初始化
刚才说到,我们会选择一个均值为0 0 0 方差守恒 ,其想法为,若在每一个网络层中,在正向传播与反向传播的过程中,其输入与输出值的方差相等,则可以避免训练中出现梯度爆炸与梯度消失。
这样说可能有点抽象,下面我们通过Xavier初始化 的推导来详细了解如何实现方差守恒,Xavier初始化是一种经典且实用的初始化,从经验上讲,Xavier初始化可以应对大多数情况,也是大多数教材会介绍的第一种初始化方法。
下面我们正式开始推导,首先,我们要聚焦于一个网络层,不考虑激活函数,记其输入向量的元素为x j x_j x j n i n n_{in} n in h i h_i h i n o u t n_{out} n o u t w i j w_{ij} w ij w i j w_{ij} w ij 0 0 0 σ 2 \sigma^2 σ 2 x j x_j x j 0 0 0 V a r ( x j ) \mathrm{Var}(x_j) Var ( x j ) w i j w_{ij} w ij x j x_j x j x j x_j x j h i h_i h i
h i = ∑ j = 1 n i n w i j x j h_i = \sum_{j = 1}^{n_{in}} w_{ij} x_j
h i = j = 1 ∑ n in w ij x j
则h i h_i h i 0 0 0 V a r ( h i ) \mathrm{Var}(h_i) Var ( h i ) V a r ( h i ) = V a r ( x j ) \mathrm{Var}(h_i) = \mathrm{Var}(x_j) Var ( h i ) = Var ( x j ) V a r ( h i ) \mathrm{Var}(h_i) Var ( h i )
V a r ( h i ) = E ( h i 2 ) − [ E ( h i ) ] 2 = E ( h i 2 ) = E [ ( ∑ j = 1 n i n w i j x j ) 2 ] = E [ ∑ j = 1 n i n w i j 2 x j 2 + ∑ j ≠ k w i j w i k x j x k ] = E [ ∑ j = 1 n i n w i j 2 x j 2 ] = ∑ j = 1 n i n E ( w i j 2 ) E ( x j 2 ) = ∑ j = 1 n i n V a r ( w i j ) V a r ( x j ) = n i n σ 2 V a r ( x j ) \mathrm{Var}(h_i) = \mathrm{E}(h_i^2) - [\mathrm{E}(h_i)]^2 = \mathrm{E}(h_i^2) = \mathrm{E}\left[ (\sum_{j = 1}^{n_{in}} w_{ij} x_j)^2 \right] = \mathrm{E}\left[ \sum_{j = 1}^{n_{in}} w_{ij}^2 x_j^2 + \sum_{j \neq k} w_{ij} w_{ik} x_j x_k \right] \\
= \mathrm{E}\left[ \sum_{j = 1}^{n_{in}} w_{ij}^2 x_j^2 \right] = \sum_{j = 1}^{n_{in}} \mathrm{E}(w_{ij}^2) \mathrm{E}(x_j^2) = \sum_{j = 1}^{n_{in}} \mathrm{Var}(w_{ij}) \mathrm{Var}(x_j) = n_{in} \sigma^2 \mathrm{Var}(x_j)
Var ( h i ) = E ( h i 2 ) − [ E ( h i ) ] 2 = E ( h i 2 ) = E [ ( j = 1 ∑ n in w ij x j ) 2 ] = E j = 1 ∑ n in w ij 2 x j 2 + j = k ∑ w ij w ik x j x k = E [ j = 1 ∑ n in w ij 2 x j 2 ] = j = 1 ∑ n in E ( w ij 2 ) E ( x j 2 ) = j = 1 ∑ n in Var ( w ij ) Var ( x j ) = n in σ 2 Var ( x j )
注:上述推导中多处使用了0 0 0 V a r ( x ) = E ( x ) − [ E ( x ) ] 2 \mathrm{Var}(x) = \mathrm{E}(x) - [\mathrm{E}(x)]^2 Var ( x ) = E ( x ) − [ E ( x ) ] 2
经过上述推导,我们可以得到结论,若要满足目标V a r ( h i ) = V a r ( x j ) \mathrm{Var}(h_i) = \mathrm{Var}(x_j) Var ( h i ) = Var ( x j ) n i n σ 2 = 1 n_{in} \sigma^2 = 1 n in σ 2 = 1
不过还没完,方差守恒理论中说的是正向传播与反向传播都要满足方差相等,因此我们还需要计算反向传播的情况,依旧沿用上述符号以及假设,在反向传播中,输入与输出跟正向传播是相反的,且均为梯度值,即输入为∂ L / ∂ h i {\partial L}/{\partial h_i} ∂ L / ∂ h i ∂ L / ∂ x j {\partial L}/{\partial x_j} ∂ L / ∂ x j
∂ L ∂ x j = ∑ i = 1 n o u t w i j ∂ L ∂ h i \frac{\partial L}{\partial x_j} = \sum_{i = 1}^{n_{out}} w_{ij} \frac{\partial L}{\partial h_i}
∂ x j ∂ L = i = 1 ∑ n o u t w ij ∂ h i ∂ L
我们希望V a r ( ∂ L / ∂ x j ) = V a r ( ∂ L / ∂ h i ) \mathrm{Var}({\partial L}/{\partial x_j}) = \mathrm{Var}({\partial L}/{\partial h_i}) Var ( ∂ L / ∂ x j ) = Var ( ∂ L / ∂ h i ) V a r ( ∂ L / ∂ x j ) \mathrm{Var}({\partial L}/{\partial x_j}) Var ( ∂ L / ∂ x j )
V a r ( ∂ L ∂ x j ) = E [ ( ∂ L ∂ x j ) 2 ] − [ E ( ∂ L ∂ x j ) ] 2 = E [ ( ∑ i = 1 n o u t w i j ∂ L ∂ h i ) 2 ] − [ E ( ∑ i = 1 n o u t w i j ∂ L ∂ h i ) ] 2 = E [ ( ∑ i = 1 n o u t w i j ∂ L ∂ h i ) 2 ] = ∑ i = 1 n o u t E ( w i j 2 ) E [ ( ∂ L ∂ h i ) 2 ] = ∑ i = 1 n o u t V a r ( w i j ) V a r ( ∂ L ∂ h i ) = n o u t σ 2 V a r ( ∂ L ∂ h i ) \mathrm{Var} \left( \frac{\partial L}{\partial x_j} \right) = \mathrm{E} \left[ \left( \frac{\partial L}{\partial x_j} \right)^2 \right] - \left[ \mathrm{E}\left( \frac{\partial L}{\partial x_j} \right) \right]^2
= \mathrm{E} \left[ \left( \sum_{i = 1}^{n_{out}} w_{ij} \frac{\partial L}{\partial h_i} \right)^2 \right] - \left[ \mathrm{E}\left( \sum_{i = 1}^{n_{out}} w_{ij} \frac{\partial L}{\partial h_i} \right) \right]^2 \\
= \mathrm{E} \left[ \left( \sum_{i = 1}^{n_{out}} w_{ij} \frac{\partial L}{\partial h_i} \right)^2 \right] = \sum_{i = 1}^{n_{out}} \mathrm{E}(w_{ij}^2) \mathrm{E} \left[ \left( \frac{\partial L}{\partial h_i} \right)^2 \right] \\
= \sum_{i = 1}^{n_{out}} \mathrm{Var}(w_{ij}) \mathrm{Var} \left( \frac{\partial L}{\partial h_i} \right) = n_{out} \sigma^2 \mathrm{Var} \left( \frac{\partial L}{\partial h_i} \right)
Var ( ∂ x j ∂ L ) = E [ ( ∂ x j ∂ L ) 2 ] − [ E ( ∂ x j ∂ L ) ] 2 = E ( i = 1 ∑ n o u t w ij ∂ h i ∂ L ) 2 − [ E ( i = 1 ∑ n o u t w ij ∂ h i ∂ L ) ] 2 = E ( i = 1 ∑ n o u t w ij ∂ h i ∂ L ) 2 = i = 1 ∑ n o u t E ( w ij 2 ) E [ ( ∂ h i ∂ L ) 2 ] = i = 1 ∑ n o u t Var ( w ij ) Var ( ∂ h i ∂ L ) = n o u t σ 2 Var ( ∂ h i ∂ L )
计算过程与正向传播非常相似,而得出的结论为,若要满足V a r ( ∂ L / ∂ x j ) = V a r ( ∂ L / ∂ h i ) \mathrm{Var}({\partial L}/{\partial x_j}) = \mathrm{Var}({\partial L}/{\partial h_i}) Var ( ∂ L / ∂ x j ) = Var ( ∂ L / ∂ h i ) n o u t σ 2 = 1 n_{out} \sigma^2 = 1 n o u t σ 2 = 1 1 2 ( n i n + n o u t ) σ 2 = 1 \frac{1}{2}(n_{in} + n_{out}) \sigma^2 = 1 2 1 ( n in + n o u t ) σ 2 = 1
至此,我们就完成了对Xavier初始化的推导,先别着急问这个结论有什么用,让我们先来回顾一下我们干了什么。首先,我们在寻找一个参数初始化的方法,也就是给上述推导中的w i j w_{ij} w ij 0 0 0 σ 2 \sigma^2 σ 2
1 2 ( n i n + n o u t ) σ 2 = 1 ⇒ σ 2 = 2 n i n + n o u t \frac{1}{2}(n_{in} + n_{out}) \sigma^2 = 1 \quad \Rightarrow \quad \sigma^2 = \frac{2}{n_{in} + n_{out}}
2 1 ( n in + n o u t ) σ 2 = 1 ⇒ σ 2 = n in + n o u t 2
也就是说,Xavier初始化就是帮我们确定了这个未定的方差值,需要注意的是,这个方差值与网络层的输入输出数量有关,也就是说,在Xavier初始化中,不同网络层所使用的概率分布的方差是不同的 ,以上文实现的多层感知机为例,一共有两个网络层,第一个网络层中n i n = 784 n_{in} = 784 n in = 784 n o u t = 256 n_{out} = 256 n o u t = 256 n i n = 256 n_{in} = 256 n in = 256 n o u t = 10 n_{out} = 10 n o u t = 10
最后,还剩最后一件事情,就是确定分布类型,这里一般使用正态分布或者均匀分布 ,Pytorch中的实现会使用均匀分布,具体原因有很多,比如正态分布有概率出现极端数值,均匀分布产生的随机数更便于计算等等,不过从实际使用上来讲,两者差别其实不大,根据Xavier初始化的均值和方差,使用正态分布与均匀分布进行初始化时所使用的具体分布为
N ( 0 , 2 n i n + n o u t ) o r U ( − 6 n i n + n o u t , 6 n i n + n o u t ) N \left(0, \sqrt{\frac{2}{n_{in} + n_{out}}} \right) \quad or \quad U \left( -\sqrt{\frac{6}{n_{in} + n_{out}}}, \sqrt{\frac{6}{n_{in} + n_{out}}} \right)
N ( 0 , n in + n o u t 2 ) or U ( − n in + n o u t 6 , n in + n o u t 6 )
Pytorch代码实现
Pytorch自然也实现了多数常用的参数初始化方法,下面我们就来介绍一下,在Pytorch中实现参数初始化一般会采用自定义初始化函数配合模型的apply()方法使用,还是以上文中实现的多层感知机为例,参数初始化函数如下
1 2 3 4 5 6 def weight_init (m ): if isinstance (m, nn.Linear): nn.init.xavier_normal_(m.weight) nn.init.constant_(m.bias, 0 )
该函数中,输入m为神经网络模型的网络层,isinstance()函数用于判断该网络层是否为指定类型,例如此处判断网络层是否为线性层。常用的参数初始化方法均在nn.init中,此处用到了nn.init.xavier_normal_(),即Xavier初始化,输入为网络层的权重,即代表对网络层的权重使用Xavier初始化,还用到了nn.init.constant_(),该函数用于将参数初始化为常数,此处代表将网络层的偏置初始化为0 0 0
而后,我们使用模型的apply()方法,参数为上述初始化函数名
1 model.apply(weight_init)
在Pytorch中,模型的apply()方法的作用是,遍历模型的所有网络层,并将指定函数应用于模型的网络层,上述代码的作用就是将实现好的参数初始化函数遍历的作用于模型的所有网络层。
将上述参数初始化代码加入到训练函数中,再进行一次训练
1 model_train(MLP, FashionMNIST_train, FashionMNIST_test, num_epoch=10 , lr=0.1 , wd=0 , device=device)
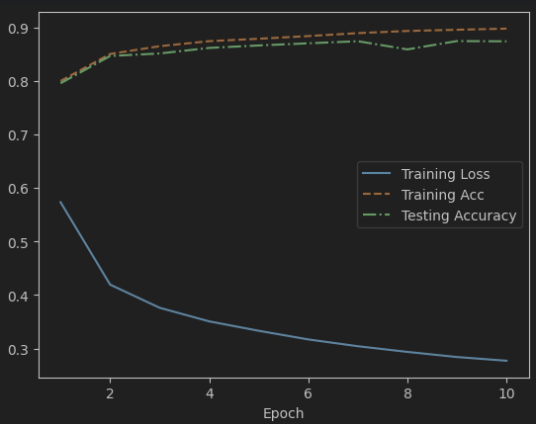
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Epoch: 1 Training Loss: 0.573314 Epoch: 1 Training Accuracy: 79.96% Epoch: 1 Testing Accuracy: 79.53% Epoch: 2 Training Loss: 0.419421 Epoch: 2 Training Accuracy: 85.01% Epoch: 2 Testing Accuracy: 84.63% Epoch: 3 Training Loss: 0.376108 Epoch: 3 Training Accuracy: 86.46% Epoch: 3 Testing Accuracy: 85.10% Epoch: 4 Training Loss: 0.350751 Epoch: 4 Training Accuracy: 87.40% Epoch: 4 Testing Accuracy: 86.14% Epoch: 5 Training Loss: 0.333174 Epoch: 5 Training Accuracy: 87.85% Epoch: 5 Testing Accuracy: 86.60% Epoch: 6 Training Loss: 0.317027 Epoch: 6 Training Accuracy: 88.35% Epoch: 6 Testing Accuracy: 87.00% Epoch: 7 Training Loss: 0.304352 Epoch: 7 Training Accuracy: 88.90% Epoch: 7 Testing Accuracy: 87.39% Epoch: 8 Training Loss: 0.293761 Epoch: 8 Training Accuracy: 89.31% Epoch: 8 Testing Accuracy: 85.86% Epoch: 9 Training Loss: 0.284190 Epoch: 9 Training Accuracy: 89.53% Epoch: 9 Testing Accuracy: 87.42% Epoch: 10 Training Loss: 0.277256 Epoch: 10 Training Accuracy: 89.74% Epoch: 10 Testing Accuracy: 87.37%
可以看出,相比与不使用Xavier初始化,第一轮训练的损失值更小,且后续模型的收敛速度也更快。